
Изграждането на автоматизирана софтуерна система означаваше настройка на множество сървъри със специална конфигурация на процесора, памет, съхранение и други ресурси за много години. След това беше сформиран екип от администратори, които да управляват тези системи. Тогава екипът за разработка пое инфраструктурата и започна да създава процеси, които свързват сървърите.
Този процес може да бъде сложен, защото включва много различни групи, които работят заедно за постигане на обща цел. Тогава тези конфликти на интереси могат да бъдат проблем.
Освен това може да бъде доста скъпо. Това изисква да имате администратори във вашата ведомост. Сървърите, които работят непрекъснато, консумират ресурси, въпреки че не се използват.
За да поддържате най-добрата производителност във времето, имате нужда от решение за автоматично мащабиране, което автоматично мащабира ресурсите на сървъра.
Облачната платформа има едно предимство: тя ви позволява да създавате архитектура от край до край без необходимост от настройка на сървърен клъстер. От гледна точка на администрацията няма какво да се поддържа.
Това е рентабилна опция за стартиращи фирми и фазите на проектите с минимален жизнеспособен продукт (MVP). Това е добра отправна точка, ако е трудно да се предвидят бъдещи производствени натоварвания и потребителска активност. Това е мястото, където може да бъде предизвикателство да се определи конфигурацията на клъстерните сървъри.
Автоматизирането на процесите чрез безсървърни облачни услуги е това, което отличава безсървърната архитектура. Той свързва услуги и произвежда резултати, които са подобни на традиционните клъстерни сървъри.
Това е пример за изграждане на такава архитектура, като се използват само собствени AWS услуги.
Съдържание
Подхващане на потока на услугите без сървър
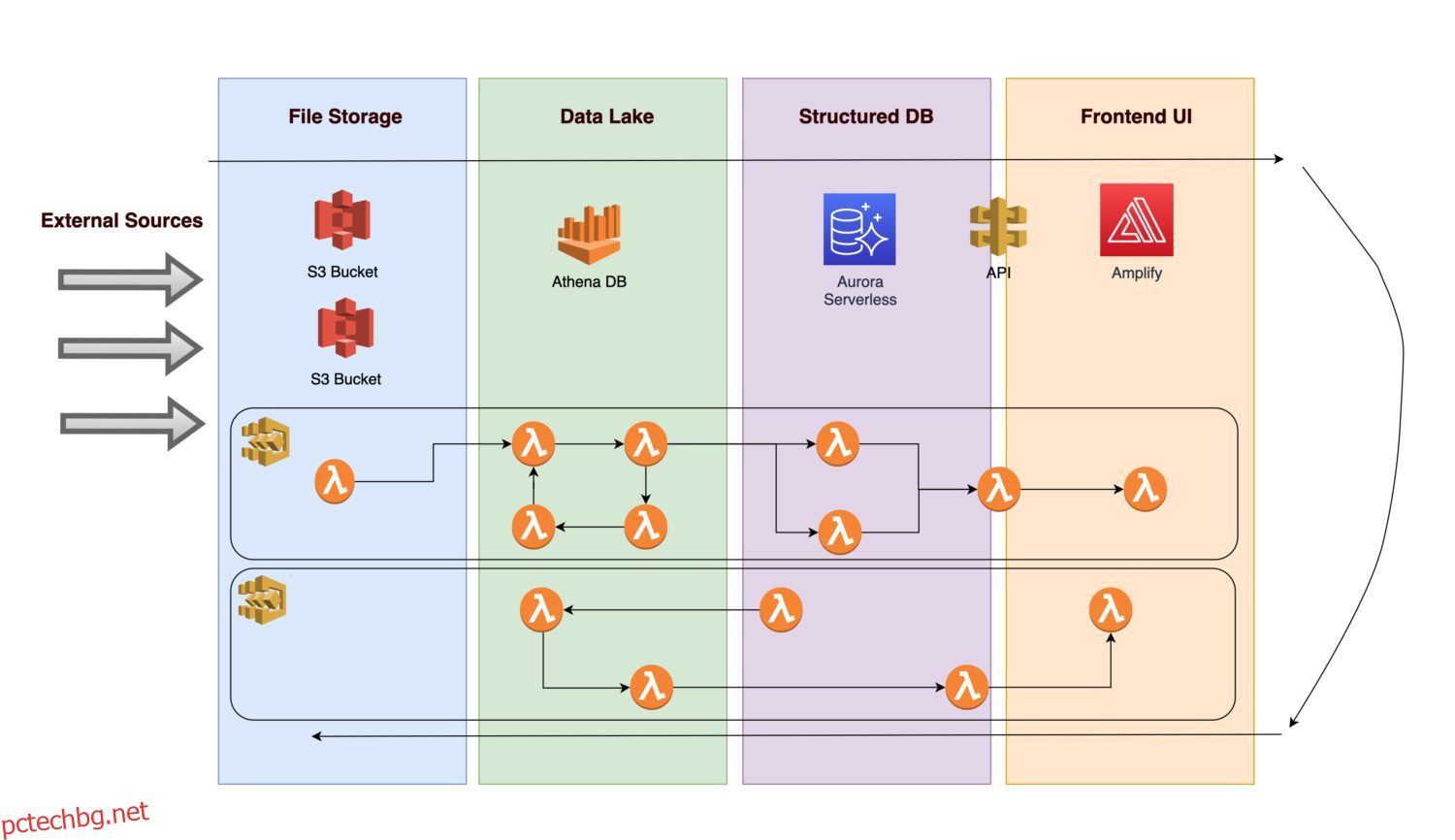
Представете си, че искате да създадете платформа за събиране на различни данни и снимки (или снимки) на инфраструктурата на някои конкретни активи (това може да бъде всеки производствен или комунален актив).
- За да бъде възможен бъдещият анализ, е необходимо първо да бъдат погълнати входящите данни.
- След прилагане на бизнес правила, back-end процедура записва изчислените резултати като нормализирана информация в релационна база данни.
- Предният край на приложението, който показва нормализирани чисти данни, позволява на потребителите да преглеждат резултатите.
Нека разгледаме кои компоненти може да включва архитектурата.
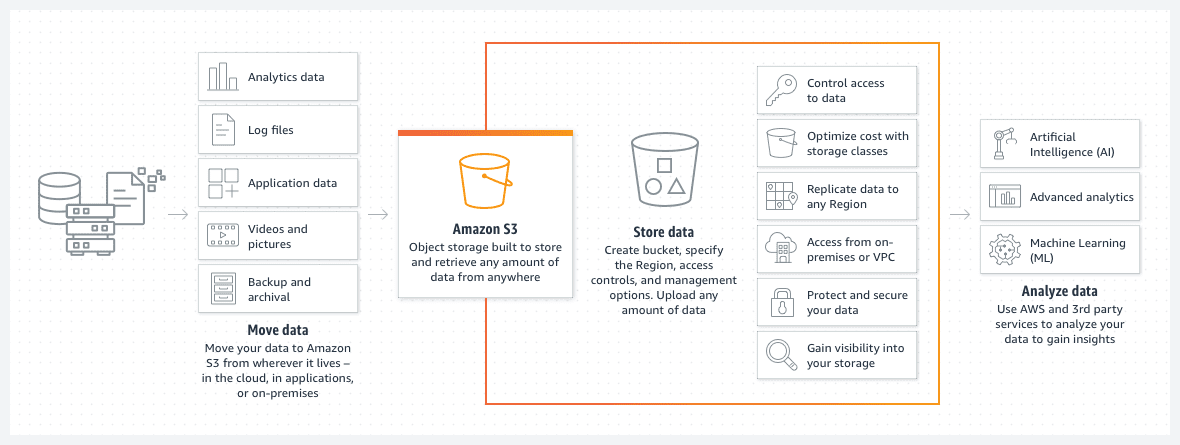
AWS S3 кофи
 Източник: aws.amazon.com
Източник: aws.amazon.com
Кофите на Amazon S3 са чудесен начин за съхраняване на файлове или снимки в облака на AWS. Цената на съхранението на кофата S3 е забележително ниска. Нещо повече, въвеждането на политика за жизнения цикъл на кофа S3 допълнително намалява тази цена.
Подобна политика автоматично ще премести по-стари файлове в различни класове S3 кофи, като например достъп до архив или дълбок архив. Тогава класовете се различават и по скоростта на времето за достъп, но за стари данни това ще бъде по-малък проблем. Той служи основно за достъп до архивираните данни в случай на спешно събитие, а не за стандартни оперативни нужди.
- Можете да организирате вашите данни в подпапки.
- Трябва да зададете подходящи ограничения за разрешения.
- Добавете етикети към кофи, за да ги направите лесни за идентифициране и за възможна употреба в рамките на динамични S3 политики за кофи.
- Кофата е без сървър по дизайн. Това е просто място за съхранение на вашите данни.
Кофата S3 е без сървър по дизайн. Това е просто място за съхранение на вашите данни.
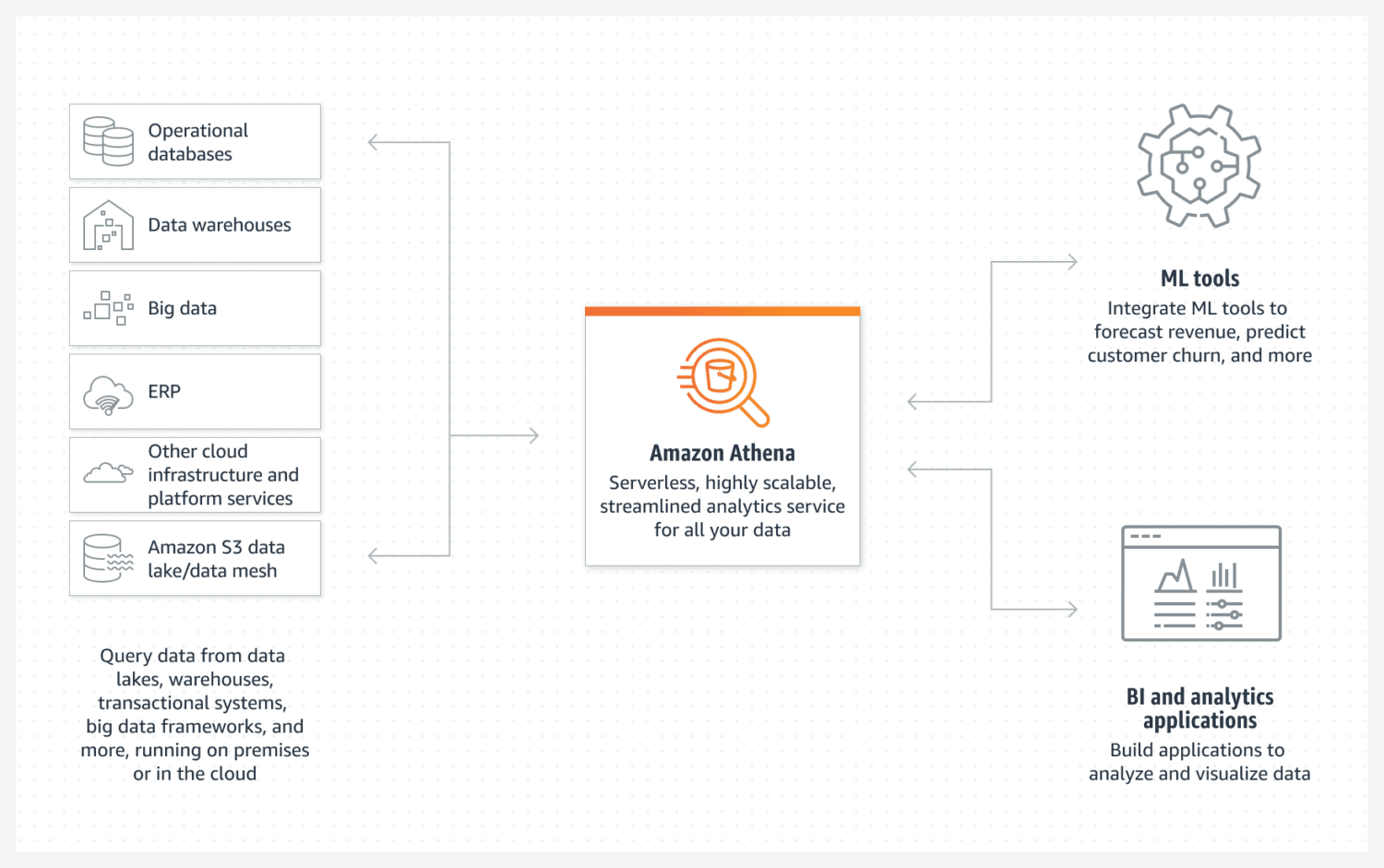
База данни AWS Athena
 Източник: aws.amazon.com
Източник: aws.amazon.com
Athena улеснява създаването на езеро с основни данни на AWS. Това е база данни без сървъри, която използва S3 контейнер за съхранение на своите данни. Организацията на данните се поддържа от структурирани файлови формати като паркет или файлове със стойности, разделени със запетая (CSV). Кофата S3 съдържа файловете и Athena се позовава на тях всеки път, когато процесите избират данните от базата данни.
Само имайте предвид, че Athena не поддържа различни функционалности, които иначе се считат за стандартни, например изявления за актуализиране. Ето защо трябва да гледате на Атина като на много проста опция.
Той обаче поддържа индексиране и разделяне. Може също така да се мащабира хоризонтално много лесно, тъй като това е толкова сложно, колкото добавянето на нови кофи към инфраструктурата. За просто, но функционално създаване на езеро от данни, това все още може да е достатъчно в повечето случаи.
За добра производителност изборът на най-добрия дизайн на данни с акцент върху бъдещата употреба е от съществено значение. Важно е да сте много ясни относно начина, по който искате да изберете данни. Повторното създаване на таблици по-късно, след като вече съществуват и са пълни с много данни, е трудно.
Athena DB е чудесен избор и е подходящ за вашата цел, ако искате да създадете прост и неизменен набор от данни, който лесно се мащабира хоризонтално с течение на времето.
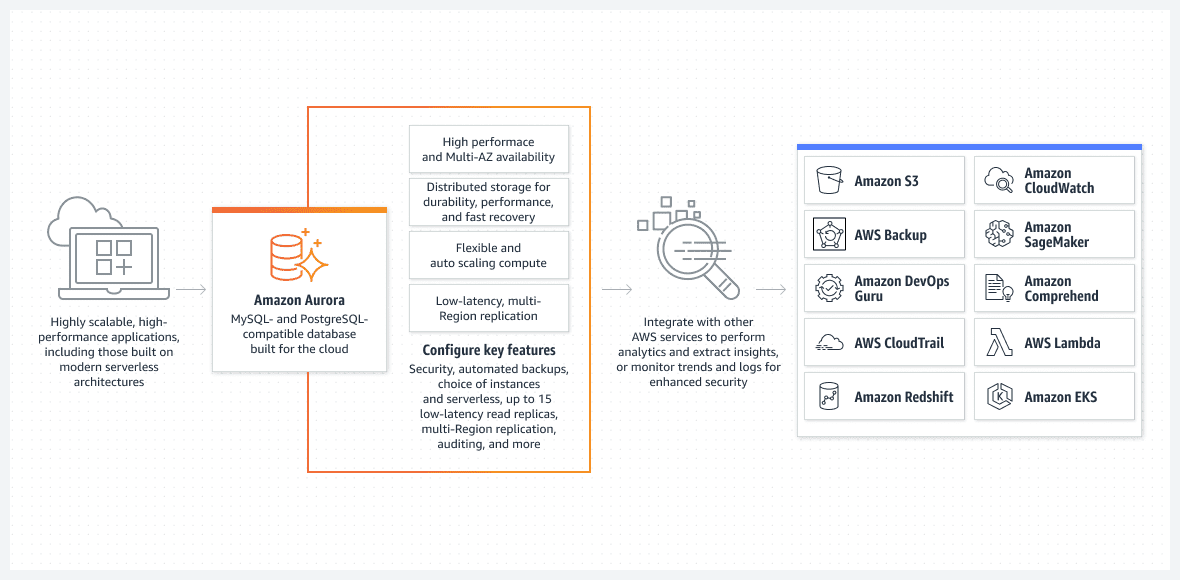
База данни AWS Aurora
 Източник: aws.amazon.com
Източник: aws.amazon.com
Athena DB се отличава със съхранението на неподготвени данни. Ето как искате да съхраните оригиналното си съдържание, за да увеличите максимално бъдещото му повторно използване, в края на краищата. Въпреки това е бавно да се предоставят избрани резултати на приложение от предния край.
Една от най-добрите опции, главно от гледна точка на лесна за изпълнение настройка, е базата данни Aurora, работеща в режим без сървър.
Aurora далеч не е основна база данни. Това е едно от най-модерните естествени решения за релационни бази данни в AWS. Това също е изключително сложно естествено решение за релационна база данни, което се подобрява с всяка версия.
Aurora е уникална, защото може да работи в режим без сървър, което я отличава от другите релационни услуги. Ето как работи режимът:
- За да конфигурирате клъстера Aurora, използвайте конзолата на AWS. Ще трябва да посочите стандартните нива на CPU и RAM, както и максималния интервал на функционалност за автоматично мащабиране. Това ще повлияе на производителността, която клъстерът Aurora може динамично да добавя или премахва. Въз основа на текущото използване на базата данни, AWS решава да увеличи или намали мащаба.
- Клъстерът Aurora няма да стартира, освен ако потребителят или процесът не инициират истинска заявка. Например, когато започне планираната пакетна обработка. Или ако приложението изпълнява извикване на задния API, за да извлече данни от база данни. Базата данни ще се отвори автоматично и ще остане активна за предварително определено време след приключване на процесите на заявка.
- Клъстерът Aurora ще се изключи автоматично, ако няма повече работа в базата данни.
За да го подчертая още веднъж, Aurora DB без сървър работи само когато трябва да върши реална работа. Автоматично стартираният клъстер отново ще се изключи, ако не обработва никаква работа. Действителната работа е това, за което плащате, а не вашето време на празен ход.
Aurora без сървър се управлява изцяло от AWS и не изисква администратор.
AWS Amplify
Amplify предлага безсървърна платформа за бързо внедряване на предни приложения, направени с библиотеки на JavaScript и React. Няма нужда да настройвате клъстерни сървъри. Използвайте конзолата на AWS, за да внедрите кода директно, или използвайте автоматизиран конвейер DevOps.
Можете да извикате back-end API, за да достигнете до данни, съхранявани в бази данни. Тези обаждания ви позволяват да получите достъп до действителните данни в приложението от предния край. Основната оптимизация на производителността на бекенда трябва да се извърши от екипа. Можете дори допълнително да намалите възможността за бавен отговор в потребителския интерфейс, ако проектирате ефективни изрази за избор в извикванията на API директно.
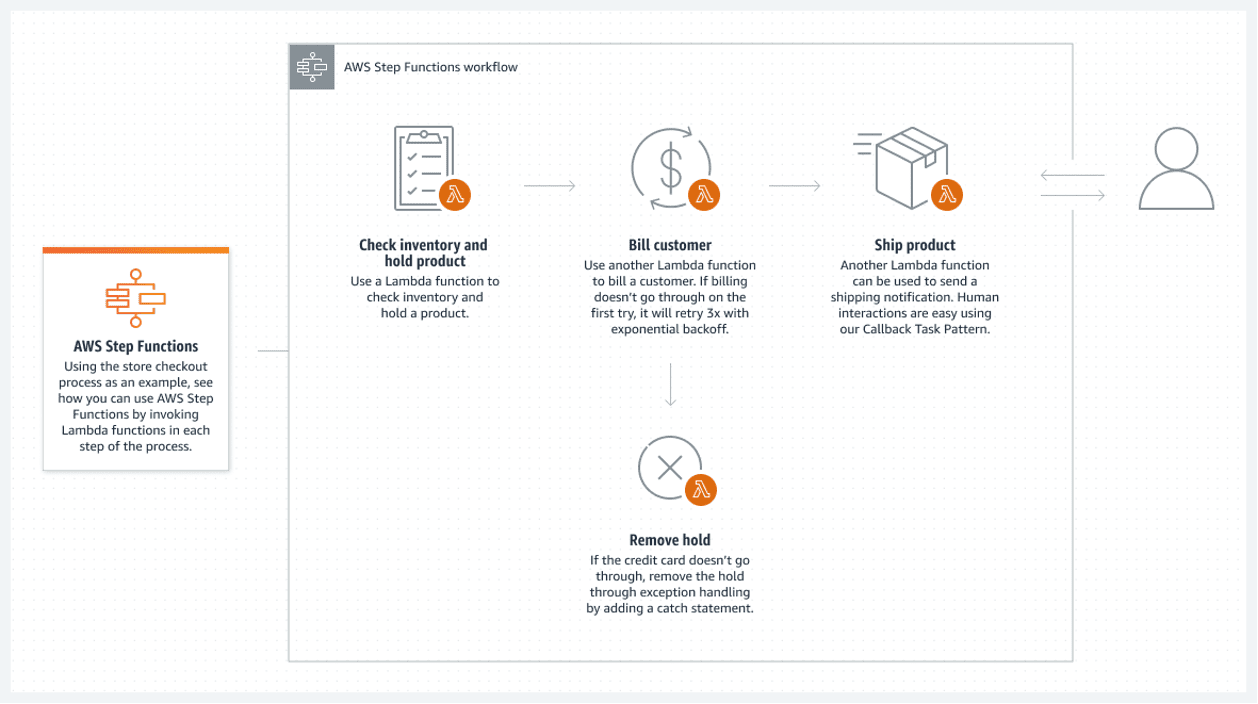
Стъпкови функции на AWS
 Източник: aws.amazon.com
Източник: aws.amazon.com
Въпреки че всички основни компоненти на системата са без сървъри, това не гарантира напълно безсървърна архитектура. Това е възможно само ако всички групови процеси между компонентите са без сървър.
Функциите на AWS Step предоставят най-доброто решение в облака на AWS. Свързан списък от AWS Lambda функции съставлява стъпковата функция. Тези функции създават блок-схема, която има ясни начални и крайни състояния. Ламбда функция, обикновено написана на езиците Python или Node JS, е изпълним бит код, който обработва всичко необходимо.
Следното е пример за това как можете да изпълните стъпкова функция:
Този поток без сървър има един основен недостатък: всяка ламбда функция може да работи само за максимум 15 минути. Следователно разделянето на потока на по-малки ламбда функции може да направи това по-малко проблематично.
Възможно е да се извикат множество ламбда функции едновременно в една стъпка, което основно означава паралелизиране на стъпка с множество ламбда, изпълнявани едновременно. Просто изчакайте цялата паралелна ламбда обработка да приключи, преди да продължите. След това преминете към следващата ламбда обработка.
Заключителни думи
Архитектурата без сървър предлага уникална възможност за създаване на облачна платформа, която покрива цялата системна среда. Тази платформа е хоризонтално мащабируема и има ниски оперативни разходи, докато го прави.
Това е идеалното решение за проекти с ограничен бюджет. Това е отлична възможност за проучване, обикновено когато никой не знае реалността на производствения товар. Това е особено важно, след като успешно сте включили всички потребители. Възможно е проектните екипи да получат цялостна представа за това как работи системата. Можете да имате всички тези предимства и пак да не се налага да правите компромиси.
Това покритие няма да е адекватно за всички случаи, особено за тези, които включват високо натоварване на процесора. Облакът AWS обаче непрекъснато се развива по отношение на случаи на използване без сървър. Обикновено е добра идея да проведете задълбочено проучване, преди да решите опцията без сървър за следващия си облачен проект на AWS.
След това вижте най-добрите бази данни без сървър за съвременни приложения.