

Данните стават все по-важни за изграждане на модели за машинно обучение, тестване на приложения и извличане на бизнес прозрения.
Въпреки това, за спазване на многото регулации за данни, те често се съхраняват и са строго защитени. Достъпът до такива данни може да отнеме месеци, за да получите необходимите подписи. Като алтернатива фирмите могат да използват синтетични данни.
Съдържание
Какво представляват синтетичните данни?
Снимка: Twinify
Синтетичните данни са изкуствено генерирани данни, които статистически приличат на стария набор от данни. Може да се използва с реални данни за поддръжка и подобряване на AI модели или може да се използва като заместител.
Тъй като не принадлежи на нито един субект на данни и не съдържа лична идентифицираща информация или чувствителни данни, като например номера на социално осигуряване, може да се използва като алтернатива за защита на поверителността на реалните производствени данни.
Разлики между реални и синтетични данни
- Най-важната разлика е в начина, по който се генерират двата типа данни. Реалните данни идват от реални субекти, чиито данни са събрани по време на проучвания или докато са използвали вашето приложение. От друга страна, синтетичните данни са изкуствено генерирани, но все пак приличат на оригиналния набор от данни.
- Втората разлика е в разпоредбите за защита на данните, засягащи реални и синтетични данни. С реални данни субектите трябва да могат да знаят какви данни за тях се събират и защо се събират и има ограничения за това как могат да бъдат използвани. Тези разпоредби обаче вече не се прилагат за синтетичните данни, тъй като данните не могат да бъдат приписани на субект и не съдържат лична информация.
- Третата разлика е в количеството налични данни. С реални данни можете да имате само толкова, колкото ви дават потребителите. От друга страна, можете да генерирате толкова синтетични данни, колкото искате.
Защо трябва да обмислите използването на синтетични данни
- Той е сравнително по-евтин за производство, защото можете да генерирате много по-големи набори от данни, наподобяващи по-малкия набор от данни, който вече имате. Това означава, че вашите модели за машинно обучение ще имат повече данни, с които да се обучават.
- Генерираните данни автоматично се маркират и почистват вместо вас. Това означава, че не е нужно да прекарвате време в трудоемката работа по подготовка на данните за машинно обучение или анализи.
- Няма проблеми с поверителността, тъй като данните не идентифицират лично и не принадлежат на субект на данни. Това означава, че можете да го използвате и споделяте свободно.
- Можете да преодолеете пристрастията към AI, като гарантирате, че малцинствените класове са добре представени. Това ви помага да изградите справедлив и отговорен AI.
Как да генерираме синтетични данни
Въпреки че процесът на генериране варира в зависимост от инструмента, който използвате, обикновено процесът започва със свързване на генератор към съществуващ набор от данни. След което идентифицирате персонално идентифициращите полета във вашия набор от данни и ги етикетирате за изключване или обфускация.
След това генераторът започва да идентифицира типовете данни на останалите колони и статистическите модели в тези колони. Оттогава можете да генерирате толкова синтетични данни, колкото са ви необходими.
Обикновено можете да сравните генерираните данни с оригиналния набор от данни, за да видите колко добре синтетичните данни приличат на реалните данни.
Сега ще проучим инструментите за генериране на синтетични данни за обучение на модели за машинно обучение.
Предимно AI

Предимно AI има генератор на синтетични данни, захранван от AI, който се учи от статистическите модели на оригиналния набор от данни. След това AI генерира измислени герои, които отговарят на научените модели.
С Mostly AI можете да генерирате цели бази данни с референтна цялост. Можете да синтезирате всякакви данни, за да ви помогне да изградите по-добри AI модели.
Синтезирано.io

Synthesized.io се използва от водещи компании за техните AI инициативи. За да използвате synthesize.io, вие посочвате изискванията за данни в YAML конфигурационен файл.
След това създавате задание и го изпълнявате като част от канал за данни. Освен това има много щедро безплатно ниво, което ви позволява да експериментирате и да видите дали отговаря на вашите нужди от данни.
YData

С YData можете да генерирате таблични, времеви серии, транзакционни, многотаблични и релационни данни. Това ви позволява да избегнете проблемите, свързани със събирането, споделянето и качеството на данни.
Той идва с AI и SDK, които да използвате за взаимодействие с тяхната платформа. В допълнение, те имат щедро безплатно ниво, което можете да използвате, за да демонстрирате продукта.
Гретел AI

Gretel AI предлага API за генериране на неограничени количества синтетични данни. Gretel има генератор на данни с отворен код, който можете да инсталирате и използвате.
Като алтернатива можете да използвате техния REST API или CLI, което ще има цена. Тяхното ценообразуване обаче е разумно и зависи от размера на бизнеса.
Копули
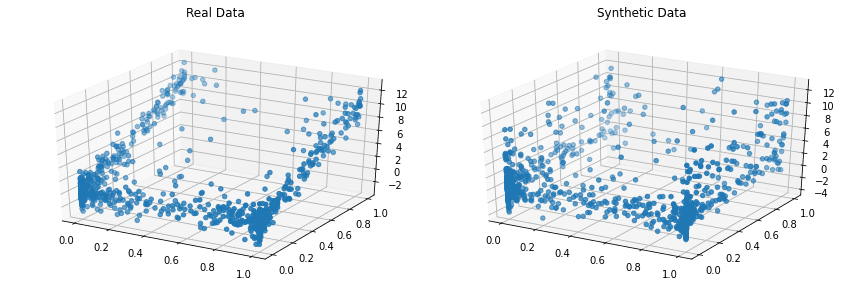
Copulas е библиотека на Python с отворен код за моделиране на многовариантни разпределения с помощта на функции на копула и генериране на синтетични данни, които следват същите статистически свойства.
Проектът стартира през 2018 г. в MIT като част от проекта Synthetic Data Vault.
CTGAN
CTGAN се състои от генератори, които могат да се учат от реални данни от една таблица и да генерират синтетични данни от идентифицираните модели.
Той е реализиран като библиотека на Python с отворен код. CTGAN, заедно с Copulas, е част от проекта Synthetic Data Vault.
DoppelGANger
DoppelGANger е реализация с отворен код на Generative Adversarial Networks за генериране на синтетични данни.
DoppelGANger е полезен за генериране на данни от времеви редове и се използва от компании като Gretel AI. Библиотеката на Python е достъпна безплатно и е с отворен код.
Синт

Synth е генератор на данни с отворен код, който ви помага да създавате реалистични данни според вашите спецификации, да скривате лична информация и да разработвате тестови данни за вашите приложения.
Можете да използвате Synth за генериране на серии в реално време и релационни данни за вашите нужди от машинно обучение. Synth също е агностик на база данни, така че можете да го използвате с вашите SQL и NoSQL бази данни.
SDV.dev
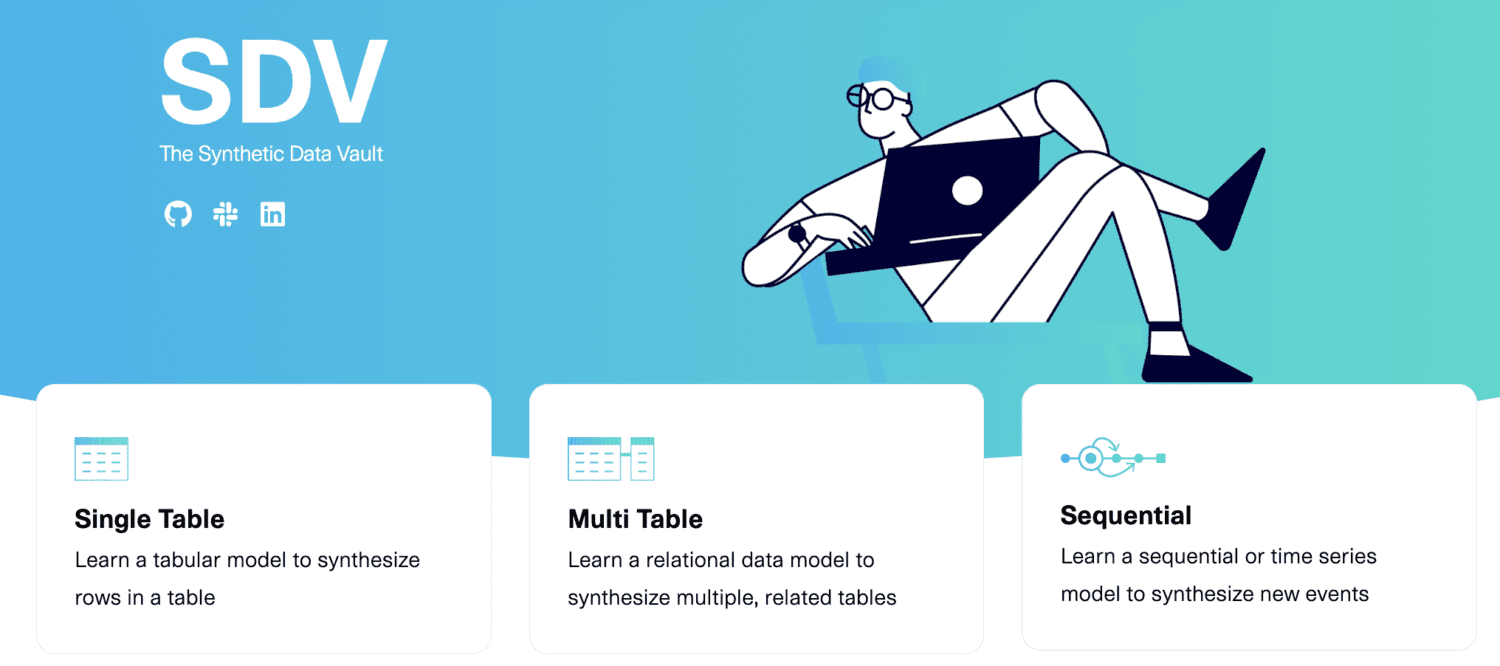
SDV означава Synthetic Data Vault. SDV.dev е софтуерен проект, който започна в MIT през 2016 г. и създаде различни инструменти за генериране на синтетични данни.
Тези инструменти включват Copulas, CTGAN, DeepEcho и RDT. Тези инструменти са внедрени като библиотеки на Python с отворен код, които можете лесно да използвате.
Тофу
Tofu е библиотека на Python с отворен код за генериране на синтетични данни въз основа на данни от биобанка в Обединеното кралство. За разлика от инструментите, споменати по-горе, които ще ви помогнат да генерирате всякакъв вид данни въз основа на вашия съществуващ набор от данни, Tofu генерира данни, които приличат само на тези от биобанката.
UK Biobank е проучване на фенотипните и генотипни характеристики на 500 000 възрастни на средна възраст от Обединеното кралство.
Twinify
Twinify е софтуерен пакет, използван като библиотека или инструмент за команден ред за двойни чувствителни данни чрез създаване на синтетични данни с идентични статистически разпределения.

За да използвате Twinify, предоставяте реалните данни като CSV файл и той се учи от данните, за да създаде модел, който може да се използва за генериране на синтетични данни. Използването му е напълно безплатно.
Datanamic
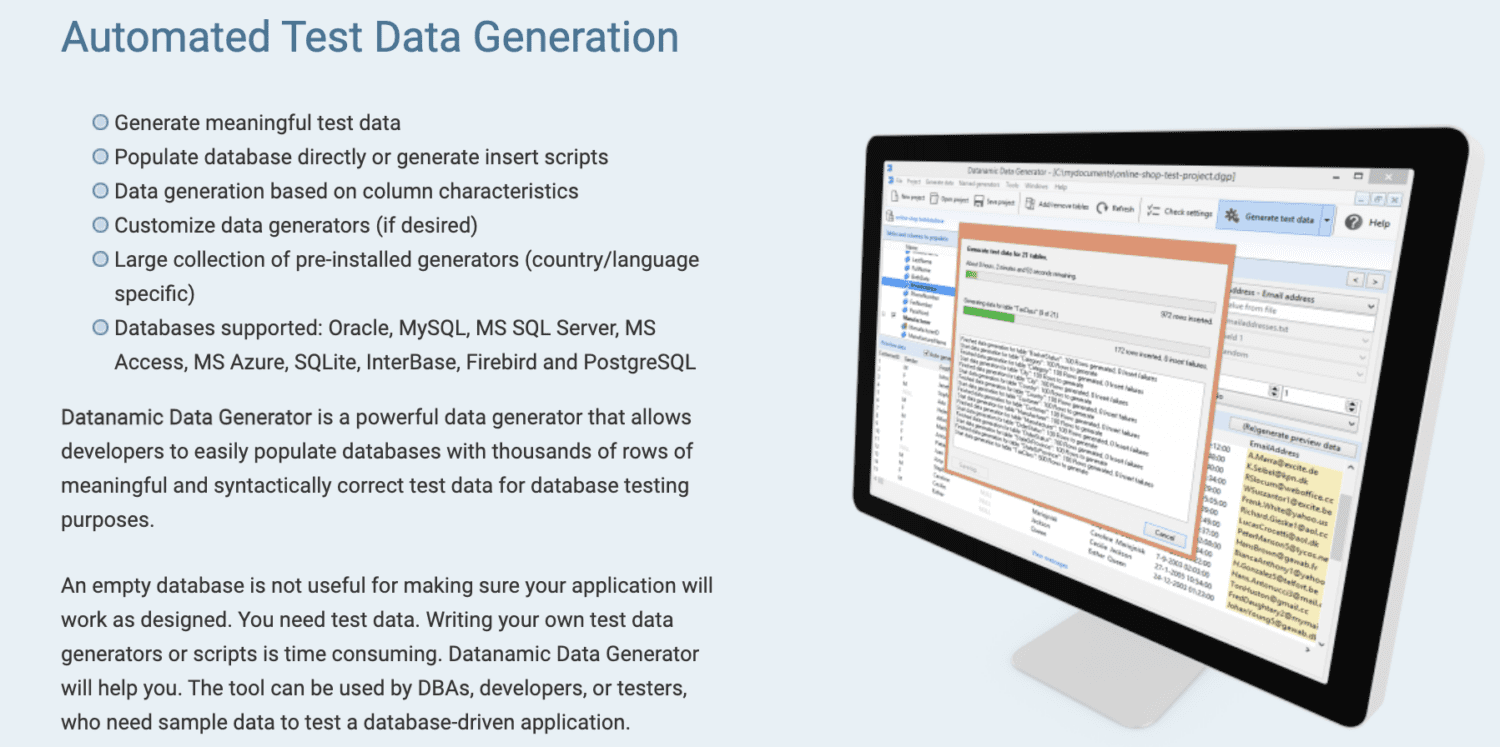
Datanamic ви помага да създавате тестови данни за приложения, управлявани от данни и машинно обучение. Той генерира данни въз основа на характеристики на колони като имейл, име и телефонен номер.
Datanamic генераторите на данни могат да се персонализират и поддържат повечето бази данни като Oracle, MySQL, MySQL Server, MS Access и Postgres. Той поддържа и гарантира референтна цялост в генерираните данни.
Бенератор
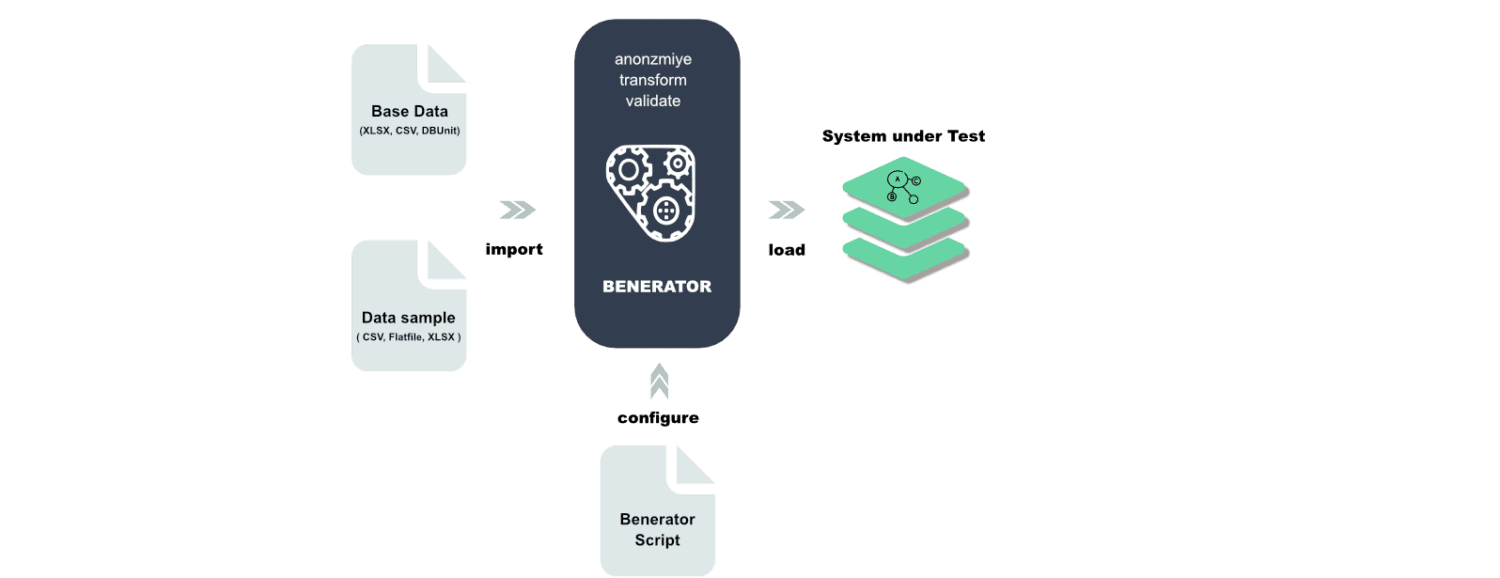
Benerator е софтуер за обфускация, генериране и мигриране на данни за целите на тестване и обучение. Използвайки Benerator, вие описвате данни с помощта на XML (Extensible Markup Language) и генерирате с помощта на инструмента на командния ред.
Той е направен да може да се използва от неразработчици и с него можете да генерирате милиарди редове от данни. Benerator е безплатен и с отворен код.
Заключителни думи
Gartner изчислява, че до 2030 г. ще има повече синтетични данни, използвани за машинно обучение, отколкото ще има реални данни.
Не е трудно да се разбере защо, като се имат предвид разходите и опасенията за поверителността на използването на реални данни. Следователно е необходимо предприятията да научат повече за синтетичните данни и различните инструменти, които да им помогнат при генерирането им.
След това разгледайте синтетичните инструменти за наблюдение за вашия онлайн бизнес.