
Apache Parquet предоставя няколко предимства за съхранение и извличане на данни в сравнение с традиционни методи като CSV.
Parquet format е предназначен за по-бърза обработка на данни от сложни типове. В тази статия говорим за това как форматът Parquet е подходящ за днешните непрекъснато нарастващи нужди от данни.
Преди да навлезем в детайлите на формата Parquet, нека разберем какво представляват CSV данните и предизвикателствата, които поставя пред съхранението на данни.
Съдържание
Какво е CSV съхранение?
Всички сме чували много за CSV (стойности, разделени със запетая) – един от най-разпространените начини за организиране и форматиране на данни. CSV съхранението на данни е базирано на редове. CSV файловете се съхраняват с разширение .csv. Можем да съхраняваме и отваряме CSV данни с помощта на Excel, Google Sheets или всеки текстов редактор. Данните са лесно видими след отваряне на файла.
Е, това не е добре – определено не е за формат на база данни.
Освен това, тъй като обемът на данните нараства, става трудно да се правят заявки, да се управляват и извличат.
Ето пример за данни, съхранени в .CSV файл:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutions
Ако го прегледаме в Excel, можем да видим структура ред-колона, както е показано по-долу:
Предизвикателства с CSV съхранението
Базираните на редове хранилища като CSV са подходящи за операции за създаване, актуализиране и изтриване.
Какво ще кажете за Read in CRUD тогава?
Представете си един милион реда в горния .csv файл. Отварянето на файла и търсенето на данните, които търсите, ще отнеме разумно време. Не е толкова готино. Повечето облачни доставчици като AWS таксуват компаниите въз основа на количеството сканирани или съхранени данни – отново CSV файловете заемат много място.
CSV хранилището няма изключителна опция за съхраняване на метаданни, което прави сканирането на данни досадна задача.
И така, какво е рентабилното и оптимално решение за извършване на всички CRUD операции? Нека проучим.
Какво представлява съхранението на данни в Parquet?
Паркет е формат за съхранение с отворен код за съхранение на данни. Използва се широко в екосистемите Hadoop и Spark. Паркетните файлове се съхраняват с разширение .parquet.
Паркетът е силно структуриран формат. Може също да се използва за оптимизиране на сложни необработени данни, присъстващи в насипно състояние в езера от данни. Това може значително да намали времето за заявка.
Parquet прави съхранението на данни ефективно и извличането по-бързо поради комбинация от редови и колонни (хибридни) формати за съхранение. В този формат данните се разделят както хоризонтално, така и вертикално. Форматът на паркета също така елиминира до голяма степен разходите за анализ.
Форматът ограничава общия брой I/O операции и, в крайна сметка, цената.
Parquet също съхранява метаданните, които съхраняват информация за данни като схема на данни, брой стойности, местоположение на колони, минимална стойност, максимален брой стойности на групи редове, тип кодиране и т.н. Метаданните се съхраняват на различни нива във файла , което прави достъпа до данни по-бърз.
При достъп, базиран на редове, като CSV, извличането на данни отнема време, тъй като заявката трябва да премине през всеки ред и да получи конкретните стойности на колоните. С Parquet storage всички необходими колони могат да бъдат достъпни наведнъж.
В обобщение,
- Паркетът се основава на колонна структура за съхранение на данни
- Това е оптимизиран формат на данни за групово съхраняване на сложни данни в системи за съхранение
- Parquet формат включва различни методи за компресиране и кодиране на данни
- Той значително намалява времето за сканиране на данни и времето за заявка и заема по-малко дисково пространство в сравнение с други формати за съхранение като CSV
- Минимизира броя на IO операциите, намалявайки разходите за съхранение и изпълнение на заявки
- Включва метаданни, които улесняват намирането на данни
- Осигурява поддръжка с отворен код
Формат на данните за паркета
Преди да преминем към пример, нека разберем по-подробно как се съхраняват данните във формат Parquet:
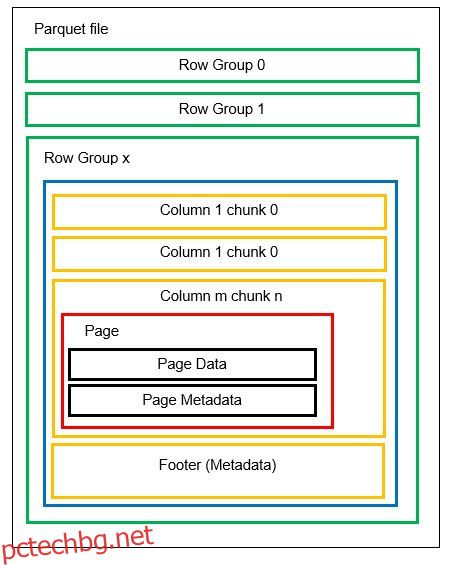
Можем да имаме множество хоризонтални дялове, известни като групи редове в един файл. Във всяка група редове се прилага вертикално разделяне. Колоните са разделени на няколко части от колони. Данните се съхраняват като страници в частите на колоните. Всяка страница съдържа стойностите на кодирани данни и метаданни. Както споменахме по-рано, метаданните за целия файл също се съхраняват в долния колонтитул на файла на ниво група редове.
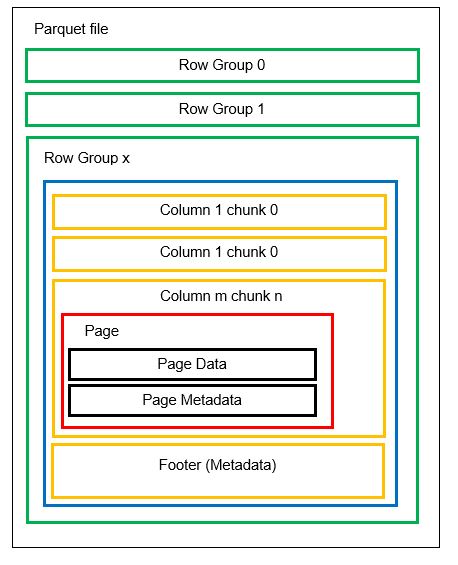
Тъй като данните са разделени на части от колони, добавянето на нови данни чрез кодиране на новите стойности в нова част и файл също е лесно. След това метаданните се актуализират за засегнатите файлове и групи редове. Така можем да кажем, че Parquet е гъвкав формат.
Parquet поддържа естествено компресирането на данни с помощта на техники за компресиране на страници и кодиране на речници. Нека да видим прост пример за компресиране на речника:
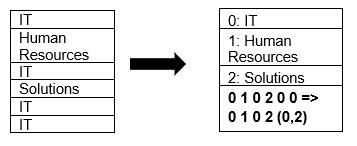
Обърнете внимание, че в горния пример виждаме IT разделението 4 пъти. Така че, докато се съхранява в речника, форматът кодира данните с друга лесна за съхраняване стойност (0,1,2…) заедно с броя пъти, които се повтарят непрекъснато – IT, IT се променя на 0,2, за да се запази повече пространство. Запитването на компресирани данни отнема по-малко време.
Пряко сравнение
След като вече имаме ясна представа как изглеждат форматите CSV и Parquet, време е за някои статистически данни, за да сравним двата формата:
CSV
Паркет
Формат за съхранение, базиран на редове.
Хибрид от базирани на редове и базирани на колони формати за съхранение.
Консумира много място, тъй като не е налична опция за компресиране по подразбиране. Например файл от 1TB ще заема същото място, когато се съхранява в Amazon S3 или друг облак.
Компресира данните по време на съхранение, като по този начин заема по-малко място. Файл от 1 TB, съхранен във формат Parquet, ще заема само 130 GB място.
Времето за изпълнение на заявката е бавно поради търсенето по редове. За всяка колона всеки ред от данни трябва да бъде извлечен.
Времето за заявка е около 34 пъти по-бързо поради базираното на колони съхранение и наличието на метаданни.
Трябва да се сканират повече данни за всяка заявка.
Около 99% по-малко данни се сканират за изпълнение на заявката, като по този начин се оптимизира производителността.
Повечето устройства за съхранение таксуват въз основа на пространството за съхранение, така че форматът CSV означава висока цена за съхранение.
По-малко разходи за съхранение, тъй като данните се съхраняват в компресиран, кодиран формат.
Файловата схема трябва да бъде изведена (водеща до грешки) или предоставена (досадно).
Файловата схема се съхранява в метаданните.
Форматът е подходящ за прости типове данни.
Parquet е подходящ дори за сложни типове като вложени схеми, масиви, речници.
Заключение 👩💻
Чрез примери видяхме, че Parquet е по-ефективен от CSV по отношение на цена, гъвкавост и производителност. Това е ефективен механизъм за съхранение и извличане на данни, особено когато целият свят се движи към облачно съхранение и оптимизиране на пространството. Всички основни платформи като Azure, AWS и BigQuery поддържат формат Parquet.