

Уеб скрапирането ви позволява ефективно да събирате големи количества данни от интернет по много бърз начин и е особено полезно в случаите, когато уебсайтовете не излагат данните си по структуриран начин чрез използването на интерфейси за програмиране на приложения (API).
Например, представете си, че създавате приложение, което сравнява цените на артикулите в сайтовете за електронна търговия. Как бихте постъпили по въпроса? Един от начините е ръчно да проверявате сами цената на артикулите във всички сайтове и да записвате констатациите си. Това обаче не е умен начин, тъй като в платформите за електронна търговия има хиляди продукти и ще ви отнеме цяла вечност, за да извлечете подходящи данни.
По-добър начин да направите това е чрез уеб бракуване. Уеб скрапирането е процес на автоматично извличане на данни от уеб страници и уебсайтове чрез използването на софтуер.
Софтуерните скриптове, наричани уеб скрепери, се използват за достъп до уебсайтове и извличане на данни от уебсайтовете. Извлечените данни, обикновено в неструктурирана форма, след това могат да бъдат анализирани и съхранени по структуриран начин, който е значим за потребителите.
Уеб скрапингът е много ценен при извличането на данни, тъй като осигурява достъп до богатство от данни и позволява автоматизация, така че можете да планирате вашия скрипт за уеб скрапинг да се изпълнява в определени моменти или в отговор на определени задействания. Уеб сканирането също ви позволява да получавате актуализации в реално време и улеснява провеждането на пазарни проучвания.

Много бизнеси и компании разчитат на уеб скрапинг за извличане на данни за анализ. Компаниите, специализирани в човешките ресурси, електронната търговия, финансите, недвижимите имоти, пътуванията, социалните медии и изследванията, използват уеб скрапинг, за да извлекат подходящи данни от уебсайтове.
Самият Google използва уеб скрапинг, за да индексира уебсайтове в интернет, така че да може да предостави подходящи резултати от търсенето на потребителите.
Въпреки това е важно да бъдете внимателни, когато скрапирате мрежата. Въпреки че изтриването на публично достъпни данни не е незаконно, някои уебсайтове не позволяват изтриването. Това може да се дължи на факта, че имат чувствителна потребителска информация, техните условия за ползване изрично забраняват бракуване на уеб сайтове или защитават интелектуалната собственост.
Освен това някои уебсайтове не позволяват уеб скрапинг, тъй като може да претовари сървъра на уебсайта и да доведе до увеличени разходи за честотна лента, особено когато уеб скрапингът се извършва в мащаб.
За да проверите дали даден уебсайт може да бъде бракуван, добавете robots.txt към URL адреса на уебсайта. robots.txt се използва, за да посочи на ботовете кои части от уебсайта могат да бъдат изчерпани. Например, за да проверите дали можете да изтриете Google, отидете на google.com/robots.txt
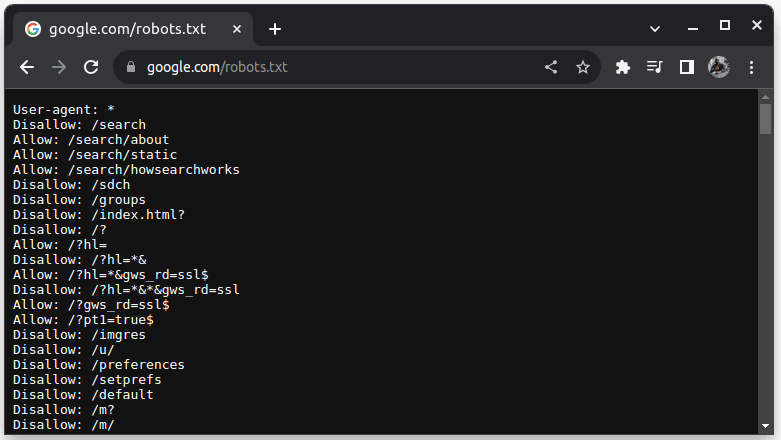
Потребителски агент: * се отнася за всички ботове или софтуерни скриптове и роботи. Disallow се използва, за да каже на ботове, че не могат да получат достъп до URL адрес в директория, например /search. Allow указва директории, откъдето могат да имат достъп до URL адреси.
Пример за сайт, който не позволява скрапинг, е LinkedIn. За да проверите дали можете да изтриете LinkedIn, отидете на linkedin.com/robots.txt
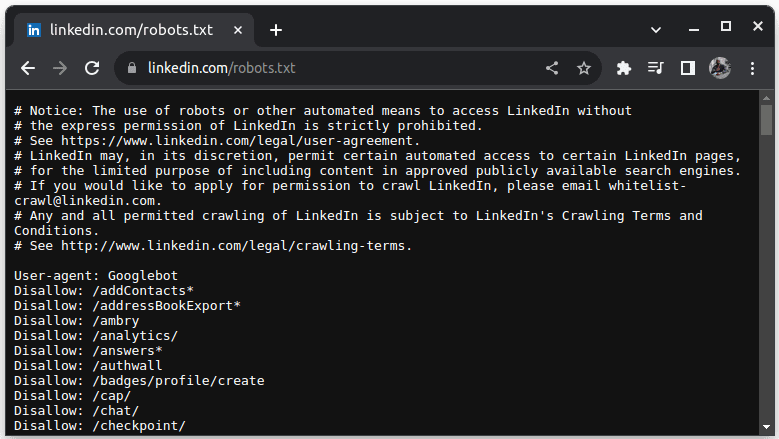
Както можете да видите, нямате право да изтривате LinkedIn без тяхно разрешение. Винаги проверявайте дали уебсайтът позволява изчерпване, за да избегнете правни проблеми.
Съдържание
Защо Java е подходящ език за уеб скрапинг
Докато можете да създадете уеб скрепер с различни езици за програмиране, Java е особено идеален за тази работа поради редица причини. Първо, Java има богата екосистема и голяма общност и предоставя разнообразие от библиотеки за уеб скрапиране като JSoup, WebMagic и HTMLUnit, които улесняват писането на уеб скрапери.

Той също така предоставя HTML Parsing Libraries за опростяване на процеса на извличане на данни от HTML документи и мрежови библиотеки като HttpURLConnection за отправяне на заявки към различни URL адреси на уебсайтове.
Силната поддръжка на Java за паралелност и многопоточност също е полезна при уеб скрапинг, тъй като позволява паралелна обработка и обработка на задачи за уеб скрапинг с множество заявки, което ви позволява да скрапирате няколко страници едновременно. Тъй като мащабируемостта е ключова сила на Java, можете удобно да изтривате уебсайтове в огромен мащаб, като използвате уеб скрепер, написан на Java.
Поддръжката на различни платформи на Java също е полезна, тъй като ви позволява да напишете уеб скрепер и да го стартирате във всяка система, която има съвместима виртуална машина на Java. Следователно можете да напишете уеб скрепер в една операционна система или устройство и да го стартирате в друга операционна система, без да е необходимо да променяте уеб скрепера.
Java може да се използва и с браузъри без глава, като Headless Chrome, HTML Unit, Headless Firefox и PhantomJs, наред с други. Безглавият браузър е браузър без графичен потребителски интерфейс. Браузърите без глава могат да симулират потребителски взаимодействия и са много полезни при сканиране на уебсайтове, които изискват потребителски взаимодействия.
Като завършек на всичко, Java е много популярен и широко използван език, който се поддържа и може лесно да се интегрира с различни инструменти като бази данни и рамки за обработка на данни. Това е от полза, защото гарантира, че докато скрейпвате данни, всички инструменти, които ще ви трябват за скрейп, обработка и съхраняване на данните, вероятно поддържат Java.
Нека видим как можем да използваме Java за уеб бракуване.
Java за уеб скрапиране: Предпоставки
За да използвате Java в уеб скрапинг, трябва да бъдат изпълнени следните предварителни условия:
1. Java – трябва да имате инсталирана Java, за предпочитане най-новата версия за дългосрочна поддръжка. В случай, че нямате инсталирана Java, отидете на инсталиране на Java, за да научите как да инсталирате Java на вашето устройство
2. Интегрирана среда за разработка (IDE) – Трябва да имате инсталирана IDE на вашата машина. В този урок ще използваме IntelliJ IDEA, но можете да използвате всяка IDE, с която сте запознати.
3. Maven – това ще се използва за управление на зависимости и за инсталиране на библиотека за уеб скрапинг.
В случай, че нямате инсталиран Maven, можете да го инсталирате, като отворите терминала и изпълните:
sudo apt install maven
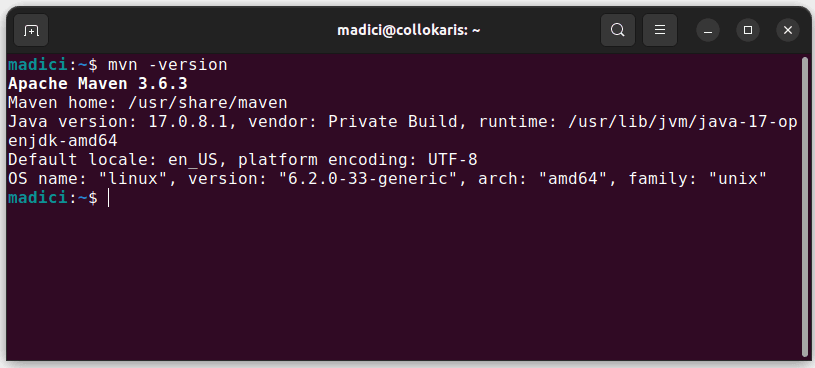
Това инсталира Maven от официалното хранилище. Можете да потвърдите, че Maven е инсталиран успешно, като изпълните:
mvn -version
В случай, че инсталацията е успешна, трябва да получите следния резултат:
Настройка на средата
За да настроите вашата среда:
1. Отворете IntelliJ IDEA. В лявата лента с менюта щракнете върху Проекти, след което изберете Нов проект.
2. В прозореца Нов проект, който се отваря, го попълнете, както е показано по-долу. Уверете се, че езикът е зададен на Java, а системата за изграждане на Maven. Можете да дадете на проекта произволно име, което предпочитате, след което използвайте Местоположение, за да посочите папката, в която искате да бъде създаден проектът. След като сте готови, щракнете върху Създаване.
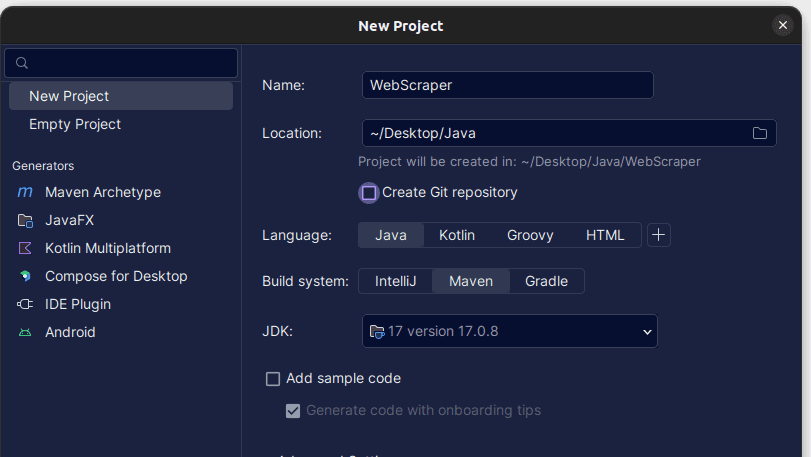
3. След като вашият проект е създаден, трябва да имате pom.xml във вашия проект, както е показано по-долу.
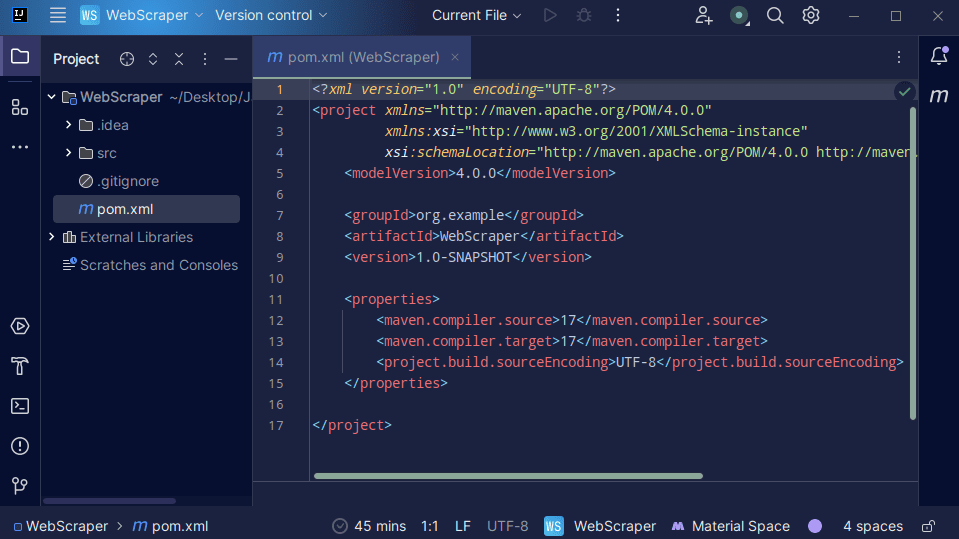
Файлът pom.xml е създаден от Maven и съдържа информация за проекта и подробности за конфигурацията, използвани от Maven за изграждане на проекта. Този файл също използваме, за да посочим, че ще използваме външни библиотеки.
При изграждането на уеб скрепер ще използваме библиотеката jsoup. Следователно трябва да го добавим като зависимост във файла pom.xml, така че Maven да може да го направи достъпен в нашия проект.
4. Добавете зависимост от jsoup във файла pom.xml, като копирате кода по-долу и го добавите към вашия файл pom.xml
<dependencies>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
Резултатът трябва да бъде както е показано по-долу:
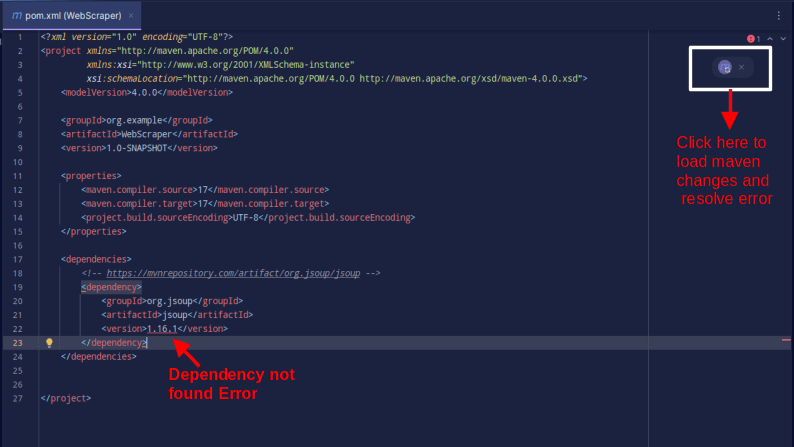
В случай, че срещнете грешка, че зависимостта не може да бъде намерена, щракнете върху посочената икона за Maven, за да заредите направените промени, да заредите зависимостта и да премахнете грешката.
С това вашата среда е напълно готова.
Уеб скрапинг с Java
За извличане на данни в мрежата ще вземем данни от ScrapeThisSiteкойто предоставя пясъчна среда, където разработчиците могат да практикуват уеб скрапинг, без да се натъкват на правни проблеми.
За да скрейпвате уебсайт с помощта на Java
1. В лявата лента с менюта на IntelliJ отворете директорията src, след това главната директория, която е вътре в директорията src. Основната директория съдържа директория, наречена java; щракнете с десния бутон върху него и изберете New, след това Java Class
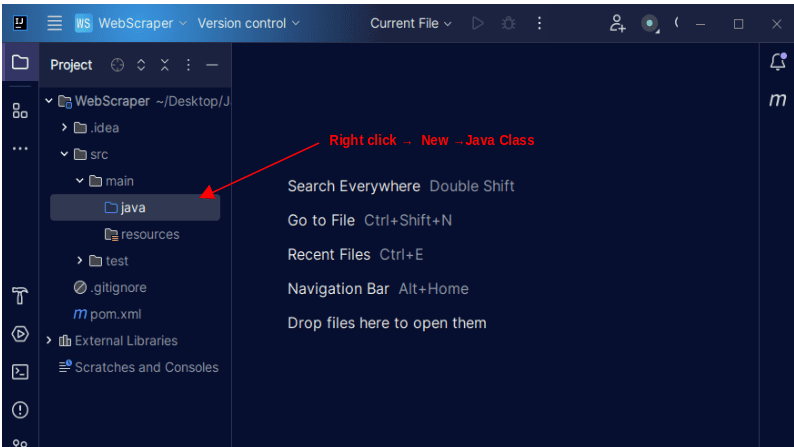
Дайте на класа произволно име, което желаете, като например WebScraper, след което натиснете Enter, за да създадете нов Java клас.
Отворете новосъздадения файл, съдържащ Java класовете, които току-що създадохте.
2. Уеб сканирането включва получаване на данни от уебсайтове. Следователно трябва да посочим URL адреса, от който искаме да изчерпваме данни. След като посочим URL адреса, трябва да се свържем с URL адреса и да направим GET заявка, за да извлечем HTML съдържанието на страницата.
Кодът, който прави това, е показан по-долу:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Изход:
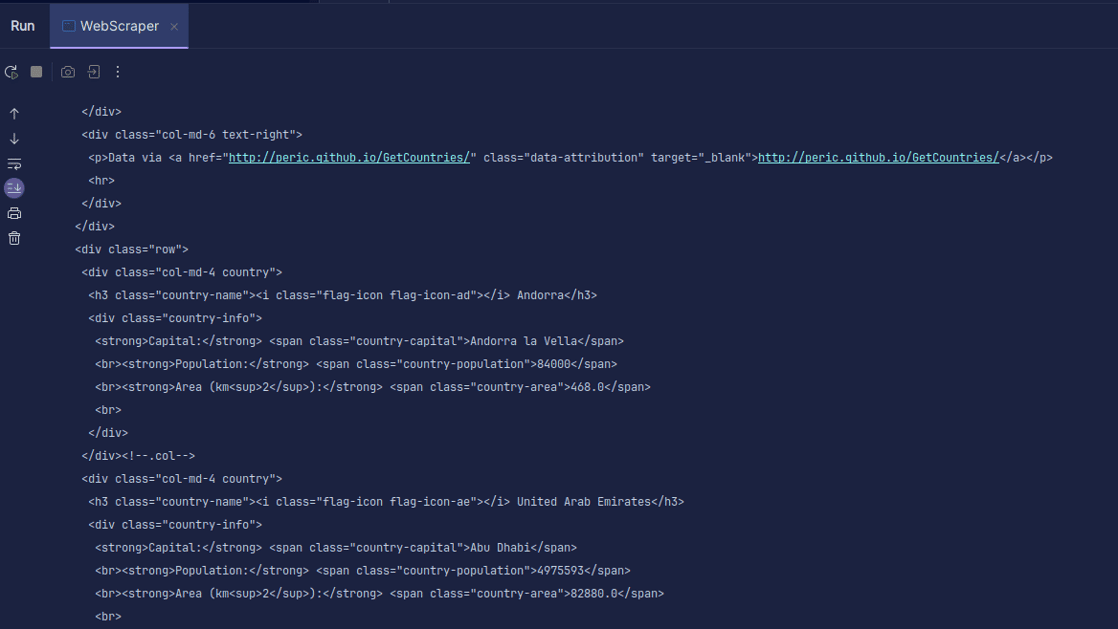
Както можете да видите, HTML кодът на страницата се връща и е това, което отпечатваме. Когато копирате, посоченият от вас URL може да има грешка и ресурсът, който се опитвате да скрапирате, може изобщо да не съществува. Ето защо е важно да увием нашия код в оператор try-catch.
Линията:
Document doc = Jsoup.connect(url).get();
Използва се за свързване към URL адреса, който искате да изкопчите. Методът get() се използва за създаване на GET заявка и извличане на HTML на страницата. След това върнатият резултат се съхранява в обект JSOUP Document, наречен doc. Съхраняването на резултата в JSOUP документ ви позволява да използвате JSOUP API за манипулиране на върнатия HTML.
3. Отидете на ScrapeThisSite и прегледайте страницата. В HTML трябва да видите структурата, показана по-долу:
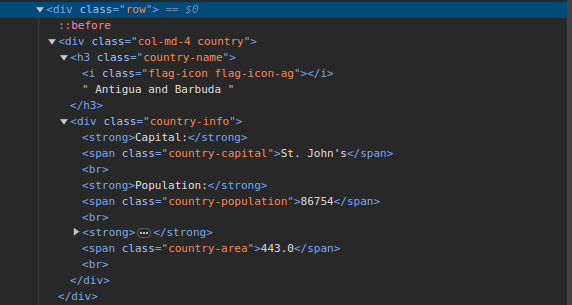
Забележете, че всички държави на страницата се съхраняват под подобна структура. Има div с клас, наречен страна, с елемент h3 с клас име на държава, съдържащ името на всяка държава на страницата.
Вътре в основния div има друг div с клас информация за страната и той съдържа информация като столица, население и площ на страната. Можем да използваме тези имена на класове, за да избираме HTML елементите и да извличаме информация от тях.
4. Извлечете конкретно съдържание от HTML на страницата, като използвате следните редове:
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " Population - " + population);
}
Използваме метода select(), за да изберем елементи от HTML на страницата, които съответстват на конкретния CSS селектор, който подаваме. В нашия случай предаваме имената на класовете. От проверката на страницата видяхме, че цялата информация за държавата на страницата се съхранява под div с клас държава.
Всяка държава има свой собствен div с клас на държава и div съдържа информация като името на държавата, столицата и населението.
Затова първо избираме всички държави на страницата с помощта на класа .country. След това съхраняваме това в променлива, наречена държави от тип Elements, която работи точно като списък. След това използваме for-цикъл, за да преминем през държави и да извлечем името на държавата, столицата и населението и да отпечатаме намереното.
Цялата ни кодова база е показана по-долу:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " - Population - " + population);
}
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Изход:
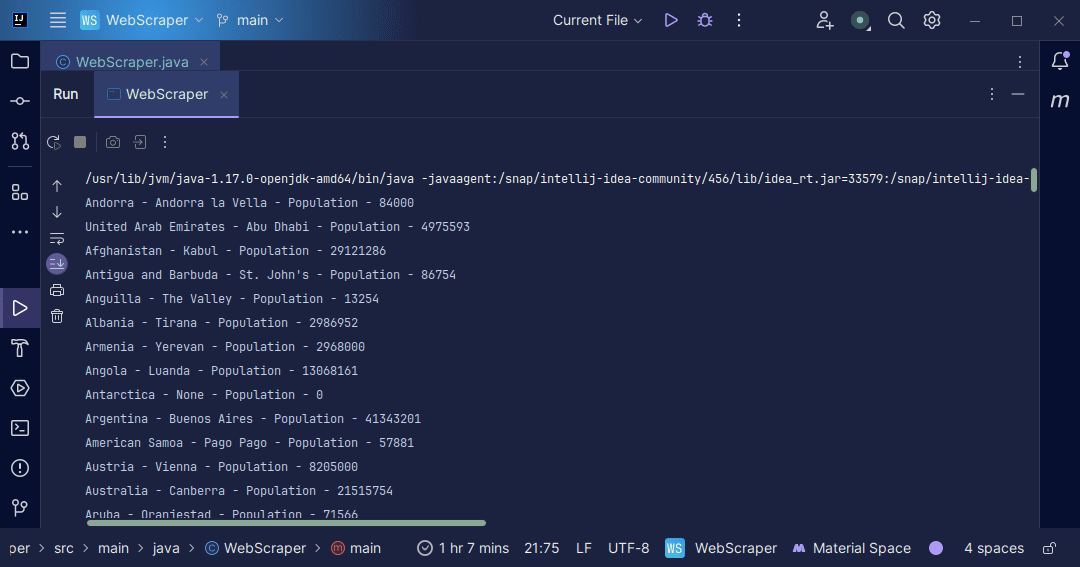
С информацията, която получаваме обратно от страницата, можем да правим различни неща, като например да я отпечатаме, както току-що направихме, или да я съхраним във файл, в случай че искаме да извършим допълнителна обработка на данни.
Заключение
Уеб скрапирането е отличен начин за извличане на неструктурирани данни от уебсайтове, съхраняване на данните по структуриран начин и обработка на данните за извличане на значима информация. Въпреки това е важно да бъдете внимателни при уеб скрапинг, тъй като някои уебсайтове не позволяват уеб скрапинг.
За по-сигурно използвайте уебсайтове, които предоставят пясъчници, за да практикувате бракуване. В противен случай винаги проверявайте robots.txt на всеки уебсайт, който искате да скрапирате, за да разберете дали уебсайтът позволява бракуване.
когато пишете уеб скрапър, Java е отличен език, тъй като предоставя библиотеки, които правят уеб скрапирането по-лесно и по-ефективно. Като разработчик на Java, изграждането на уеб скрепер ще ви помогне да развиете още повече уменията си за програмиране. Така че давайте напред и напишете свой собствен уеб скраппер или модифицирайте този, използван в статията, за да извличате различни видове информация. Приятно кодиране!
Можете също така да разгледате някои популярни базирани на облак решения за уеб скрапиране.