

Планът за възстановяване след бедствие е основната мярка, която една организация трябва да има, преди да я сполети необичайно събитие.
В ИТ индустрията започва със създаването на официален документ, съдържащ планове, действия и процедури за справяне с бедствието и последиците от него.
Бедствието е събитие, което идва внезапно без предварително предупреждение и може да бъде от различни видове. И когато се приземи, хората и организациите се сблъскват с много видове трудности, включително финансови проблеми и потребителски опит.
Ако се случи атака, трябва да сте готови да минимизирате ефектите й и да възстановите операциите си по-бързо. Това е мястото, където изготвянето на практичен план за възстановяване след бедствие ще ви помогне да задържите или предотвратите бедствието. Можете също така да намалите последиците от него по отношение на потребителското изживяване, разходите и времето на престой.
Освен това трябва да поддържате вашите планове, хора, стратегии, оборудване и системи готови, за да върнете всичко обратно в действие. Но за това трябва да разберете задълбочено възстановяването след бедствие.
В тази статия ще обсъдя това подробно, заедно с ключовите терминологии за възстановяване след бедствие, за да можете да отвърнете на удара смело и да излезете по-силен в такива неблагоприятни условия.
Нека да започнем!
Съдържание
Какво е бедствие?
Бедствието е непредвидено събитие, което може да се случи навсякъде, включително в ИТ индустрията. Това се случва естествено или от хора и може да попречи на дейността на компанията и да наруши структурата на инфраструктурата.
В резултат на това са засегнати една организация и нейните клиенти, доставчици, служители и партньори. Това оказва натиск върху организацията по отношение на финанси, репутация в индустрията, доверие на клиентите и периметър на сигурност.
Следователно трябва да сте готови предварително да преодолеете подобен сценарий. За целта трябва незабавно да възстановите всяка операция и данни. С прости думи, трябва да подготвите вашата организация да възстанови всичко във възможно най-краткия интервал за вашите клиенти.
Бедствията са много видове, като кибератаки, саботаж, терористични атаки, ransomware или физически заплахи, урагани, земетресения, пожари, наводнения, промишлени аварии, прекъсвания на електрозахранването и много други.
Какво имате предвид под възстановяване след бедствие?

Възстановяването след бедствие е процес на възстановяване на нормалните операции след претърпяно бедствие. Това включва възобновяване на достъпа до хардуер, софтуер, оборудване, свързаност, мрежа, захранване и данни. Трябва да зададете правила и процедури в документиран процес, за да подготвите вашата организация преди бедствие.
Въпреки това, ако съоръженията на вашата организация са унищожени, трябва да разширите някои от дейностите, като работите по комуникация, транспорт, снабдяване, работни места и др.
Защо е важен планът за възстановяване след бедствие?
Изготвянето на перфектен план за възстановяване от бедствие, било то природно или причинено от човека, е от съществено значение за всяка ИТ индустрия. Уверете се, че разполагате с правилния служител и инструменти на правилното място, за да изпълните плана гладко.
Нека се потопим по-дълбоко в това защо възстановяването след бедствие е от решаващо значение.
Ограничени щети
Бедствието е непредвидимо. Никой не знае кога идва и си отива. Но вие се подготвяте предварително да контролирате щетите, причинени на вашата инфраструктура.
Например в райони, застрашени от наводнения, можете да поставите основните си документи и видове оборудване на последния етаж, за да избегнете повреда.
По същия начин направете резервно копие на основните си данни, преди кибератаките да могат да нарушат данните или да ги откраднат.
Услуги за възстановяване
Ако подготвите солиден план за възстановяване от бедствието, възстановяването на всички услуги в нормалната им форма е бързо и лесно. Това означава, че за кратък интервал от време можете да възстановите почти всички основни активи и услуги.
Минимизиране на прекъсването
Не можете да знаете какво ще се случи утре или в следващата стъпка от операция. Но с перфектен план за възстановяване не е нужно да се притеснявате много за последствията. Вашата инфраструктура може да продължи операциите с минимално прекъсване.
Обучение и подготовка

ИТ инфраструктурата се състои от много служители, работещи под един покрив. Всички трябва да знаят за възстановяването, за да действат незабавно според изискванията и очакванията в случай на спешност.
Правилната подготовка също ще намали нивата на стрес на всички, свързани с вашата организация. Освен това можете да обучите служителите си да предприемат необходимите действия, ако настъпи неочаквано събитие.
Терминологии за възстановяване след бедствие
Нека започнем с терминологията, за да разберем възстановяването след бедствие от по-близък поглед.
RTO
Целното време за възстановяване (RTO) е времето, което една организация определя според естеството на бизнеса, за да толерира бедствие, без да засяга финансовия растеж.
Докато задава RTO, компанията трябва да провери времето на престой, което може да повлияе на вашата организация по много начини. Използва се за проучване на жизнеспособни стратегии за продължаване на вашите бизнес операции дори след бедствие. Когато клиентите се сблъскат с някакви смущения в приложението, те питат колко време ще отнеме на приложението, за да се върне към действието. Отговорът е RTO за всяка организация.
Пример: Да предположим, че сте компания за онлайн транзакции като PayPal или Pioneer, изправена пред непредвидими събития. В този случай вашият RTO ще бъде достатъчно бърз, за да възстанови операцията.
С други думи, една компания задава своя RTO на час или два, за да избегне последствия под формата на финанси или данни.
RPO
Целите на точките за възстановяване (RPO) са загубата на данни, с която ИТ инфраструктурата може да се справи по отношение на времето и количеството информация.
объркващо?
Вземете пример за база данни, която записва транзакции на банка, включително трансфери, планиране, плащания и други. Когато се случи бедствие, базата данни се възстановява в реално време. Разликата между базата данни по време на бедствието и възстановяването на базата данни след бедствие в този случай е нула.
За някои компании е приемливо да отнеме около 24 часа, за да възстановят цялата информация от архива, но понякога може да бъде катастрофално. От съществено значение е да настроите вашата инфраструктура според изискванията на RPO. Това включва повишаване на честотата на архивирането, добавяне на резервна база данни към вашата архитектура и др.
Срив
Помислете за ситуация, в която пътувате на голямо разстояние. Изведнъж сте спукали гума поради някаква неочаквана причина. Вие благодарите на наличната резервна гума във вашия автомобил и инструментите за смяна на дефектната гума.
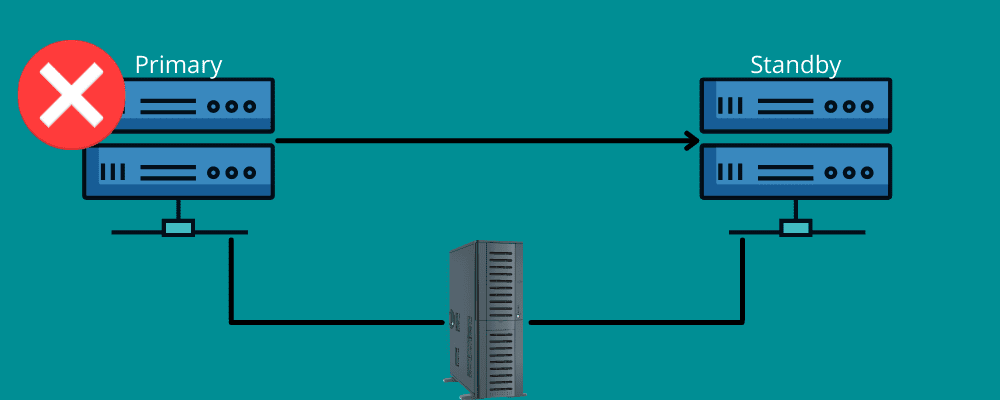
Failover работи по същия начин.
Това означава, че имате нужда от резервна връзка по време на бедствието. Накратко, преходът при срив означава да имате мрежи и системи, които можете да използвате по време на бедствие, за да превключите информацията си към системата за възстановяване.
Failover гарантира, че всички ваши услуги работят гладко, дори ако има инфраструктурни или хардуерни повреди. По този начин можете да предотвратите загубата на данни и приходи от вашата организация и да избегнете прекъсвания на услугите за вашите крайни потребители.
Можете или да го зададете ръчно, или да му позволите да функционира автоматично, за да премести данните към резервния сървър.
Възстановяване
Възстановяването при отказ на ИТ е проста операция, при която оригиналната продукция се връща на първоначалното си място (система) след справяне с бедствието. По време на атаката компаниите следват операция за преместване при срив, поради което всички работни натоварвания се прехвърлят към VM реплика или резервна система.
Не можете обаче просто да пропуснете следващата стъпка на връщане. Когато възстановите всичко и се върнете в действие, трябва да прехвърлите всички работни натоварвания към техните оригинални виртуални машини или системи. Този цялостен процес на връщане на работните натоварвания към първоначалното работно място или система е известен като възстановяване при отказ. Това означава, че се „връщате“ след атаката.
Failback се използва и за планирана поддръжка на предприятие. Вярно е, че възстановяването при срив винаги се случва след прехода. С други думи, отказът е първата стъпка, а отказът е втората стъпка при възстановяването на основни данни. Може да се настрои между облак към облак, локално към локално, локално към облак или произволна комбинация от тях.
д-р
Disaster Recovery (DR) е процесът, при който имате предварително изградени планове за възстановяване на вашите активи в рамките на времевата рамка.
DR дава възможност на организацията да реагира бързо и да възстанови всяка отделна услуга от неочаквано събитие. Той също така дава официална документация, която съдържа инструкции за предприемане на незабавни действия в случай на непредвидени инциденти.
ГКПП
Планът за непрекъснатост на бизнеса (BCP) е един от най-приемливите планове за възстановяване след бедствие, който позволява на ИТ инфраструктурата да прави стратегии, за да се справя с прекъсвания на ИТ на сървъри, мобилни устройства, персонални компютри и мрежи.
BCP е малко по-различен от възстановяването след бедствие, тъй като помага на организацията да прави планове за възстановяване на корпоративен софтуер и производителност, за да отговори на ключови бизнес нужди.
Тук една компания създава система за възстановяване, за да преодолее потенциални заплахи, като кибератаки или природни бедствия. Той е предназначен да осигури активи и да гарантира, че всички услуги ще се върнат в действие бързо след стачката.
BCM

Управлението на непрекъснатостта на бизнеса (BCM) е процес за управление на риска, специално проектиран да действа като щит срещу заплахи за бизнес процесите. BCM е следващата стъпка на BCP, където валидира плановете за възстановяване, за да се увери, че всеки в бизнеса реагира незабавно на плана и възстановява всички основни неща.
BCM действа като управленска рамка за идентифициране на инфраструктурни рискове, когато е изправена пред външни и/или вътрешни заплахи. Той също така гарантира, че рамката работи ефективно с помощта на редовно тестване за подобряване на предвидимостта, намаляване на риска и привеждане в съответствие на плана за бъдещи атаки.
БСК
Анализът на въздействието върху бизнеса (BIA) е процес на анализиране на степента на оцеляване на даден бизнес чрез идентифициране на ключови системи, операции и процеси. Той разказва за ефекта от бедствие върху вашата организация поради прекъсване на вашите операции.
BIA прогнозира последствията преди атаката да се случи, за да събере ключова информация, която може да помогне за създаването на мощни стратегии за възстановяване. Той също така идентифицира свързаните разходи, дължащи се на повредите, като например разходите за подмяна на оборудването, загуба на паричен поток, печалби, заплати и др.
Когато създавате доклад за BIA, трябва да имате предвид ключовите процеси, включени във вашия бизнес, въздействието на смущенията в различни области, приемлива продължителност, допустими области, финансови разходи и др.
Call Tree
Дървото на обажданията е процес на съставяне на списък с персонал, който да се обади по време на спешен случай. Това е процедура, която следва дървовидна структура.
Например, по време на бедствие, един човек ще се свърже с малка група членове с спешно съобщение, тези членове на персонала се обаждат на всяка група поотделно. По този начин целият персонал ще бъде информиран по време на заплахата и ще започне възложената им работа, за да възстанови всяка функция и процес навреме. Създаването на списък е лесно, но прилагането му в реално време създава объркване.
Трябва да извършвате редовни дейности по обаждане, за да подготвите всеки член на спешния персонал да остане нащрек. Редовното тестване също може да помогне за идентифициране на променени или липсващи числа, които могат сериозно да повлияят на производителността.
Дървото на повикванията съдържа информация, която да се използва по време на спешен случай за доставяне на инструкции. Може да се направи и ръчно, но хората използват автоматизация, за да ускорят процеса и да уведомят членовете в днешния дигитален свят.
Команден център/Център за управление
Това е виртуално или физическо съоръжение, специално подготвено да осигури командване или контрол върху плановете за възстановяване по време на криза. Той комуникира с екипа за управление на системите и функциите по време на бедствието.
Традиционно инфраструктурата зависи от командния център, който се справя с кризи без подходящ подход. В днешно време организациите са проектирали своя контролен център перфектно, което превръща незабавния отговор в основната компетентност.
След като усети бедствие, командният център бързо преминава към фазата на възстановяване. Освен това той служи като точка за отчитане в случай на услуги, преса, доставки и др. Той също така обединява хора от различни дисциплини по време на такива сценарии.
Реагиране на инциденти

Реакцията при инцидент е вид реакция, дадена за справяне с атака. Това се прави с помощта на правилните процедури и персонал за ефективно запазване на сигурността на мрежата и данните в точното време.
Ако една организация има план за инциденти преди неочакваното събитие, тя може да защити данните си от заплахи в реално време. Специалистите по реагиране при инциденти винаги остават нащрек за проблемите и действат естествено по време на инцидент. Те предприемат определени мерки, за да избегнат пробиви в сигурността, като гарантират, че не пропускат нито една стъпка по време на възстановяване след бедствие.
В началото трябва да определите критичните данни и да ги съхраните в облака или на всяко отдалечено място, за да осигурите безопасност. Обърнете внимание на текущите инфраструктурни нужди и развиващите се кибернетични заплахи чрез редовно актуализиране на плановете за реакция при инциденти.
Архивиране
Решенията за архивиране помагат на ИТ инфраструктурата да поддържа копия на данни и да ги съхранява сигурно в точното време. Ако се сблъскате с повреда на базата данни, случайно изтриване на всички данни или някакъв друг проблем, трябва да сте готови с резервното копие, за да възстановите данните незабавно и да продължите с услугите.

Това включва репликиране на файловете и съхраняването им на сигурно място за лесен достъп до всички данни след необичайно събитие. Ще помогне, ако направите резервно копие на данните си на няколко места, за да сте сигурни, че можете да ги възстановите, дори ако даден сайт се провали.
Устойчивост
Способността на общности, държави, организации и лица да устоят или да издържат на бедствие, без да компрометират услугите и системите, е известна като устойчивост на бедствия.
Една организация трябва да е готова да удържи голямо количество стрес поради опасностите. Уверете се, че имате възможностите да минимизирате загубите си с по-добро планиране, вместо да чакате някой да дойде и да ви спаси. Това ще ви помогне да се справите с бедствията и ефективно да възстановите вашата ИТ инфраструктура.
Тук основната цел е да се запазят и възстановят основните функции и структури в точното време, когато е необходимо. За да станете организация, устойчива на бедствия, трябва да се подготвите предварително и да имате способността да предвиждате рискове, да се приспособявате към промените, да споделяте и да учите, да интегрирате различни сектори и да управлявате нивата на риска.
SLA

Споразумението за ниво на обслужване (SLA) е план за бедствия, в който споменавате на крайните потребители времето, което може да ви отнеме за възстановяване на услугите по време на спешност.
SLA гарантира на клиентите, че техните данни са безопасни и не са компрометирани или споделяни с трети страни. Това е единствената точка за контакт с проблемите на крайния потребител.
Всяка ИТ инфраструктура дава увереност относно SLA на своите клиенти. Така че, уверете се, че комуникирате с вашите крайни потребители предварително.
SPOF
Единична точка на повреда (SPOF) е част от оборудването, индивид, ресурс или приложение, към което са свързани много други системи или приложения.
Ако такова оборудване или ресурс излезе от строя, всички основни части, свързани със системата, отпаднат с него. По този начин целият процес и бизнес операция ще бъдат засегнати.
Следователно трябва да имате стратегия за справяне с такъв проблем, за да поддържате организацията си работеща. Първото нещо, което можете да направите, е да идентифицирате тази отделна част от оборудването или системата, която може да повлияе повече. След това извършете анализ на въздействието върху бизнеса и получете резултат за оценка на риска, за да сте наясно със сцените, които ще се случат. Разровете се и ги намерете преди събитието.
След като изброите всички SPOF, класифицирайте ги според процеса на възстановяване. Поставете всеки един от SPOF в три различни категории:
- Възстановявайте лесно и директно с по-малко време и бюджет.
- Възстановяването би било трудно, но може да се разработи надежден процес за възстановяване.
- Нищо не може да се направи, за да се възстанови, след като падне.
Можете да действате съответно въз основа на категорията.
Възстановяване на системата
По време на хардуерен срив трябва да изпълните процес на възстановяване, за да възстановите конкретната система или сървър в оригиналната им форма. И за да възстановите цялата система, трябва да сте готови с изискванията за възстановяване, архивиране, съвместимост на фърмуера и хардуерна съвместимост.
Възстановяването на системата е процес, който нулира машината в предишните й настройки или в същото състояние, в което е била, когато е била нова. Това ще унищожи всички вирусни инфекции, дължащи се на инсталиран софтуер или приложения във вашата система.
Този процес включва планиране на възстановяване на ИТ инфраструктура, която задава и следва определени процедури за осигуряване на наличност на данни срещу причинени от човека или природни смущения.
Възстановяване на системата
Възстановяването на системата е инструмент за възстановяване, който ви позволява да възстановите определени файлове и информация до предишното им състояние в точното време.
С възстановяването на системата можете да възстановите ключове на системния регистър, инсталирани програми, драйвери, системни файлове и други обратно към предишната им версия. Това действа като спасител при много бедствия.
План за тестване
Отнася се за документ, който съхранява информация за тестова стратегия, оценки, ресурси, крайни срокове, цели и графици. Той работи като план, който провежда тестове, за да гарантира безопасността на хардуера и софтуера.
Това включва различни тестове в съответствие с процедурите и стъпките, планирани за управление на последствията от бедствие. Извършвайте редовни тестове, за да подготвите себе си и вашата организация да не пропуснете нито една стъпка по време на действието. По този начин ИТ инфраструктурата може да разбере недостатъците и да бъде готова за битката.
Заключение
Никой не знае кога ще се случи бедствие. Следователно подходящите мерки за безопасност и сигурност са от съществено значение за всеки бизнес.
Терминологията за възстановяване след бедствие ще ви помогне да разберете как да реагирате на атаки и бедствия. Освен това ще ви помогне да се подготвите предварително, за да можете да защитите вашата инфраструктура по време на неочаквано събитие. Ще можете да създадете ефективна стратегия за възстановяване след бедствие в реално време, за да спестите милиони долари и да откажете доверието на клиентите.