
Support Vector Machine е сред най-популярните алгоритми за машинно обучение. Той е ефективен и може да се обучава в ограничени набори от данни. Но какво е това?
Съдържание
Какво е поддържаща векторна машина (SVM)?
Поддържащата векторна машина е алгоритъм за машинно обучение, който използва контролирано обучение, за да създаде модел за двоична класификация. Това е хапка. Тази статия ще обясни SVM и как се свързва с обработката на естествен език. Но първо нека анализираме как работи машината за поддържащи вектори.
Как работи SVM?
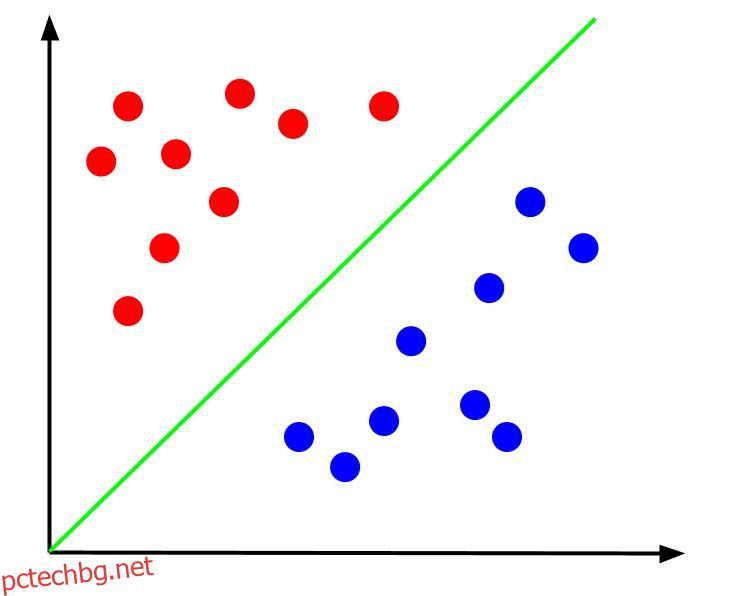
Помислете за прост проблем с класификацията, при който имаме данни, които имат две характеристики, x и y, и един изход – класификация, която е или червена, или синя. Можем да начертаем въображаем набор от данни, който изглежда така:
Като се имат предвид данни като тези, задачата би била да се създаде граница на решение. Граница на решение е линия, която разделя двата класа на нашите точки от данни. Това е същият набор от данни, но с граница на решение:
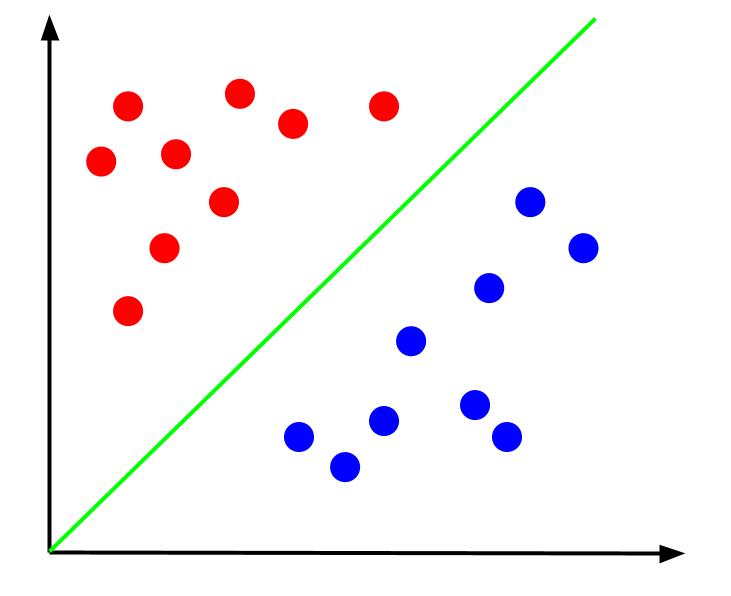
С тази граница на решение можем след това да направим прогнози за кой клас принадлежи точка от данни, като се има предвид къде се намира спрямо границата на решение. Алгоритъмът на Support Vector Machine създава най-добрата граница на решение, която ще се използва за класифициране на точки.
Но какво имаме предвид под най-добра граница на решение?
Може да се твърди, че най-добрата граница на решение е тази, която максимизира разстоянието си от който и да е от опорните вектори. Поддържащите вектори са точки от данни от всеки клас, който е най-близо до противоположния клас. Тези точки от данни представляват най-голям риск от погрешна класификация поради близостта им до другия клас.
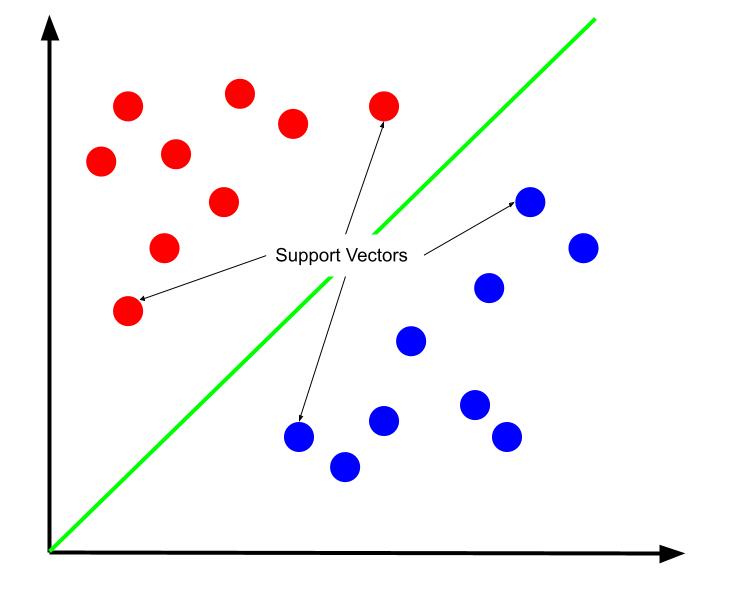
Следователно обучението на машина за опорни вектори включва опит за намиране на линия, която максимизира маржа между опорните вектори.
Също така е важно да се отбележи, че тъй като границата на решението е позиционирана спрямо опорните вектори, те са единствените детерминанти на позицията на границата на решението. Следователно другите точки от данни са излишни. И по този начин обучението изисква само опорните вектори.
В този пример формираната граница на решение е права линия. Това е само защото наборът от данни има само две функции. Когато наборът от данни има три характеристики, формираната граница на решение е равнина, а не линия. И когато има четири или повече характеристики, границата на решение е известна като хиперравнина.
Нелинейно разделими данни
Примерът по-горе разглежда много прости данни, които, когато са начертани, могат да бъдат разделени от линейна граница на решение. Помислете за различен случай, при който данните се изобразяват, както следва:
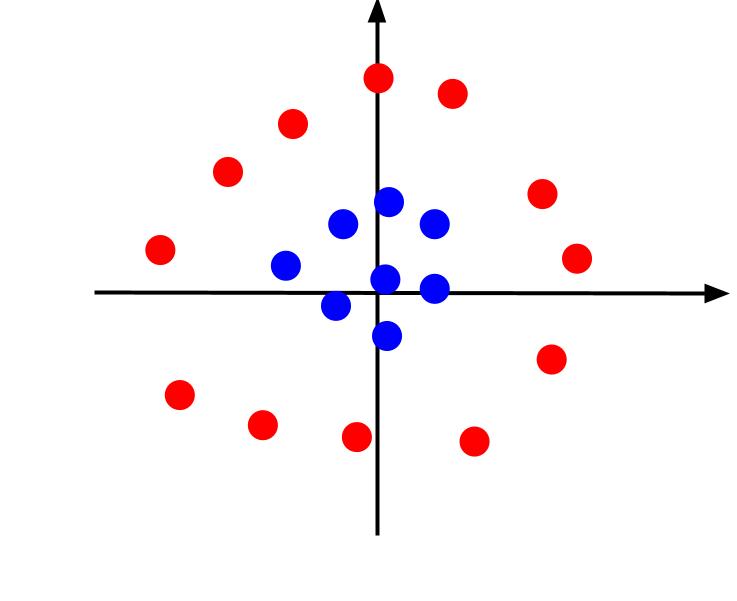
В този случай разделянето на данните с линия е невъзможно. Но можем да създадем друга функция, z. И тази характеристика може да бъде дефинирана от уравнението: z = x^2 + y^2. Можем да добавим z като трета ос към равнината, за да я направим триизмерна.
Когато погледнем 3D диаграмата от такъв ъгъл, че оста x е хоризонтална, докато оста z е вертикална, това е изгледът, който получаваме нещо, което изглежда така:
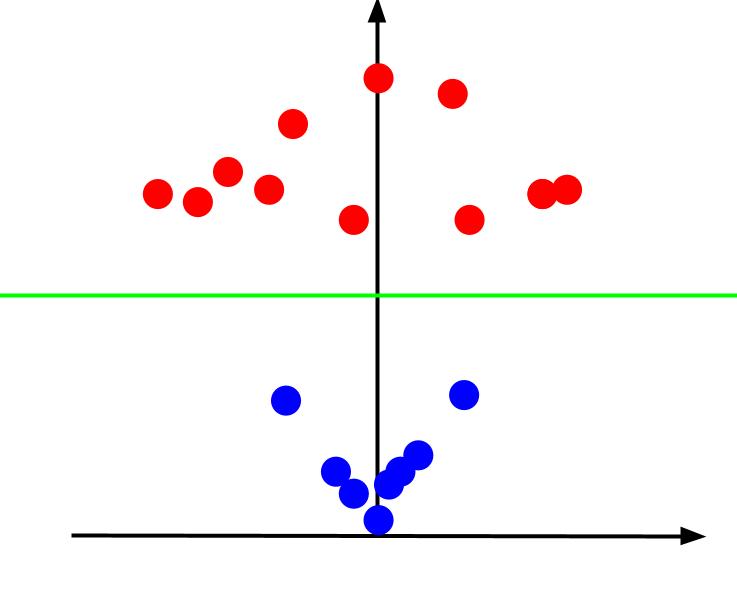
Z-стойността представлява колко далеч е дадена точка от началото спрямо другите точки в старата XY-равнина. В резултат на това сините точки по-близо до началото имат ниски z-стойности.
Докато червените точки по-далеч от началото имат по-високи z-стойности, начертаването им спрямо техните z-стойности ни дава ясна класификация, която може да бъде разграничена от линейна граница на решение, както е илюстрирано.
Това е мощна идея, която се използва в Support Vector Machines. По-общо, това е идеята за картографиране на измеренията в по-голям брой измерения, така че точките от данни да могат да бъдат разделени от линейна граница. Функциите, които са отговорни за това, са функции на ядрото. Има много функции на ядрото, като сигмоидна, линейна, нелинейна и RBF.
За да направи картографирането на тези функции по-ефективно, SVM използва трик на ядрото.
SVM в машинното обучение
Support Vector Machine е един от многото алгоритми, използвани в машинното обучение, наред с популярните като дървета на решенията и невронни мрежи. Той е предпочитан, защото работи добре с по-малко данни в сравнение с други алгоритми. Обикновено се използва за извършване на следното:
- Текстова класификация: Класифициране на текстови данни като коментари и рецензии в една или повече категории
- Разпознаване на лица: Анализиране на изображения за откриване на лица за извършване на неща като добавяне на филтри за разширена реалност
- Класификация на изображения: Поддържащите векторни машини могат да класифицират изображения ефективно в сравнение с други подходи.
Проблемът с класификацията на текста
Интернет е пълен с много и много текстови данни. Голяма част от тези данни обаче са неструктурирани и неетикетирани. За да се използват по-добре тези текстови данни и да се разбират по-добре, има нужда от класификация. Примерите за моменти, когато текстът е класифициран, включват:
- Когато туитовете се категоризират в теми, така че хората да могат да следват теми, които искат
- Когато имейл е категоризиран като Социални, Промоции или Спам
- Когато коментарите са класифицирани като насаждащи омраза или нецензурни в публични форуми
Как SVM работи с класификацията на естествен език
Support Vector Machine се използва за класифициране на текст в текст, който принадлежи към определена тема, и текст, който не принадлежи към темата. Това се постига чрез първо преобразуване и представяне на текстовите данни в набор от данни с няколко функции.
Един от начините да направите това е чрез създаване на функции за всяка дума в набора от данни. След това за всяка точка от текстови данни записвате колко пъти се среща всяка дума. Да предположим, че в набора от данни се срещат уникални думи; ще имате функции в набора от данни.
Освен това ще предоставите класификации за тези точки от данни. Въпреки че тези класификации са етикетирани с текст, повечето реализации на SVM очакват цифрови етикети.
Следователно ще трябва да конвертирате тези етикети в числа преди тренировка. След като наборът от данни бъде подготвен, като използвате тези характеристики като координати, можете да използвате SVM модел за класифициране на текста.
Създаване на SVM в Python
За да създадете поддържаща векторна машина (SVM) в Python, можете да използвате класа SVC от библиотеката sklearn.svm. Ето пример за това как можете да използвате класа SVC за изграждане на SVM модел в Python:
from sklearn.svm import SVC
# Load the dataset
X = ... y = ...
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19)
# Create an SVM model
model = SVC(kernel="linear")
# Train the model on the training data
model.fit(X_train, y_train)
# Evaluate the model on the test data
accuracy = model.score(X_test, y_test)
print("Accuracy: ", accuracy)
В този пример първо импортираме SVC класа от библиотеката sklearn.svm. След това зареждаме набора от данни и го разделяме на набори за обучение и тестове.
След това създаваме SVM модел чрез инстанциране на SVC обект и указване на параметъра на ядрото като „линеен“. След това обучаваме модела върху данните за обучение, използвайки метода на прилягане и оценяваме модела върху данните от теста, използвайки метода на резултата. Методът за оценка връща точността на модела, която отпечатваме на конзолата.
Можете също така да посочите други параметри за обекта SVC, като параметъра C, който контролира силата на регуляризацията, и параметъра gamma, който контролира коефициента на ядрото за определени ядра.
Предимства на SVM
Ето списък с някои предимства от използването на поддържащи векторни машини (SVM):
- Ефективни: SVM обикновено са ефективни за обучение, особено когато броят на пробите е голям.
- Устойчив на шум: SVM са относително устойчиви на шум в данните за обучение, докато се опитват да намерят класификатора за максимален марж, който е по-малко чувствителен към шума от другите класификатори.
- Ефективност на паметта: SVM изискват само подмножество от данните за обучение да бъдат в паметта във всеки даден момент, което ги прави по-ефективни от паметта в сравнение с други алгоритми.
- Ефективен в пространства с големи размери: SVM все още могат да работят добре дори когато броят на функциите надвишава броя на пробите.
- Гъвкавост: SVM могат да се използват за задачи за класификация и регресия и могат да обработват различни типове данни, включително линейни и нелинейни данни.
Сега нека разгледаме някои от най-добрите ресурси за изучаване на Support Vector Machine (SVM).
Ресурси за обучение
Въведение в опорните векторни машини
Тази книга за Въведение в поддържащите векторни машини изчерпателно и постепенно ви въвежда в методите за обучение, базирани на ядрото.
Той ви дава здрава основа върху теорията на опорните векторни машини.
Поддръжка на приложения за векторни машини
Докато първата книга се фокусира върху теорията на опорните векторни машини, тази книга за приложенията на опорните векторни машини се фокусира върху техните практически приложения.
Той разглежда как SVM се използват при обработка на изображения, откриване на шаблони и компютърно зрение.
Поддържащи векторни машини (информационни науки и статистика)
Целта на тази книга за опорни векторни машини (информационни науки и статистика) е да предостави общ преглед на принципите зад ефективността на опорните векторни машини (SVM) в различни приложения.
Авторите подчертават няколко фактора, които допринасят за успеха на SVM, включително тяхната способност да работят добре с ограничен брой регулируеми параметри, тяхната устойчивост на различни видове грешки и аномалии и тяхната ефективна изчислителна производителност в сравнение с други методи.
Обучение с ядра
„Обучение с ядра“ е книга, която запознава читателите с поддръжката на векторни машини (SVM) и свързаните с тях техники на ядрото.
Той е предназначен да даде на читателите основно разбиране на математиката и знанията, от които се нуждаят, за да започнат да използват алгоритми на ядрото в машинното обучение. Книгата има за цел да предостави задълбочено, но достъпно въведение в SVM и методите на ядрото.
Поддържайте векторни машини със Sci-kit Learn
Този онлайн курс за поддържащи векторни машини със Sci-kit Learn от мрежата на проекта Coursera учи как да внедрите SVM модел с помощта на популярната библиотека за машинно обучение, Sci-Kit Learn.

Освен това ще научите теорията зад SVM и ще определите техните силни страни и ограничения. Курсът е за начинаещи и отнема около 2,5 часа.
Поддържайте векторни машини в Python: Концепции и код
Този платен онлайн курс за Support Vector Machines в Python от Udemy има до 6 часа видео базирани инструкции и се предлага със сертификат.

Той обхваща SVM и как те могат стабилно да бъдат внедрени в Python. Освен това, той обхваща бизнес приложенията на Support Vector Machines.
Машинно обучение и AI: Поддръжка на векторни машини в Python
В този курс за машинно обучение и AI ще научите как да използвате поддържащи векторни машини (SVM) за различни практически приложения, включително разпознаване на изображения, откриване на спам, медицинска диагноза и регресионен анализ.

Ще използвате езика за програмиране Python, за да реализирате ML модели за тези приложения.
Заключителни думи
В тази статия научихме накратко за теорията зад опорните векторни машини. Научихме за приложението им в машинното обучение и обработката на естествен език.
Видяхме също как изглежда внедряването му с помощта на scikit-learn. Освен това говорихме за практическите приложения и предимствата на Support Vector Machines.
Въпреки че тази статия беше само въведение, допълнителните ресурси препоръчваха навлизане в повече подробности, обяснявайки повече за Support Vector Machines. Като се има предвид колко гъвкави и ефективни са те, SVM си струва да се разберат, за да се развивате като учен за данни и ML инженер.
След това можете да разгледате най-добрите модели за машинно обучение.