

Тъй като компаниите генерират все повече и повече данни, традиционният подход към съхранението на данни става все по-труден и скъп за поддържане. Data Vault, сравнително нов подход към складирането на данни, предлага решение на този проблем чрез предоставяне на мащабируем, гъвкав и рентабилен начин за управление на големи обеми от данни.
В тази публикация ще проучим как Data Vaults са бъдещето на складирането на данни и защо все повече компании възприемат този подход. Ние също така ще предоставим учебни ресурси за тези, които искат да се потопят по-дълбоко в темата!
Съдържание
Какво е Data Vault?
Data Vault е техника за моделиране на хранилище за данни, особено подходяща за гъвкави хранилища за данни. Той предлага висока степен на гъвкавост за разширения, пълно историцизиране на данните във времето и позволява силно паралелизиране на процесите на зареждане на данни. Дан Линстед разработи моделирането на Data Vault през 90-те години.
След първата публикация през 2000 г., тя спечели по-голямо внимание през 2002 г. чрез поредица от статии. През 2007 г. Linstedt спечели одобрението на Бил Инмон, който го описа като „оптималния избор“ за неговата архитектура Data Vault 2.0.
Всеки, който се занимава с термина гъвкаво хранилище на данни, бързо ще завърши с Data Vault. Особеното при технологията е, че тя е фокусирана върху нуждите на компаниите, тъй като позволява гъвкави, лесни за настройка настройки на хранилище за данни.
Data Vault 2.0 разглежда целия процес на разработка и архитектурата и се състои от метода на компонентите (имплементация), архитектура и модел. Предимството е, че този подход взема предвид всички аспекти на бизнес разузнаването с основното хранилище на данни по време на разработката.
Моделът Data Vault предлага модерно решение за преодоляване на ограниченията на традиционните подходи за моделиране на данни. Със своята мащабируемост, гъвкавост и гъвкавост, той осигурява солидна основа за изграждане на платформа за данни, която може да поеме сложността и разнообразието на съвременните среди за данни.
Архитектурата hub-and-spoke на Data Vault и разделянето на обекти и атрибути позволяват интегриране на данни и хармонизиране в множество системи и домейни, улеснявайки постепенното и гъвкаво развитие.
Решаваща роля на Data Vault в изграждането на платформа за данни е да установи единен източник на истина за всички данни. Неговият унифициран изглед на данни и поддръжка за улавяне и проследяване на исторически промени в данните чрез сателитни таблици позволяват съответствие, одит, регулаторни изисквания и цялостен анализ и докладване.
Възможностите на Data Vault за интегриране на данни в почти реално време чрез делта зареждане улесняват обработката на големи обеми данни в бързо променящи се среди, като Big Data и IoT приложения.
Хранилище за данни срещу традиционни модели на складове за данни
Трета нормална форма (3NF) е един от най-известните традиционни модели за съхранение на данни, често предпочитан в много големи реализации. Между другото, това съответства на идеите на Бил Инмон, един от „прародителите“ на концепцията за хранилище на данни.
Архитектурата на Inmon се основава на модела на релационна база данни и елиминира излишъка на данни, като разделя източниците на данни на по-малки таблици, които се съхраняват в витрини с данни и са свързани помежду си чрез първични и външни ключове. Той гарантира, че данните са последователни и точни чрез налагане на правила за референтна цялост.
Целта на нормалната форма беше да се изгради цялостен модел на данни за цялата компания за основния склад на данни; въпреки това има проблеми с мащабируемостта и гъвкавостта поради силно свързани витрини с данни, трудности при зареждане в режим почти в реално време, трудоемки заявки и дизайн и внедряване отгоре надолу.
Моделът Kimbal, използван за OLAP (онлайн аналитична обработка) и витрини за данни, е друг известен модел на хранилище на данни, в който таблиците с факти съдържат обобщени данни, а таблиците с размери описват съхранени данни в схема на звезда или схема на снежинка. В тази архитектура данните са организирани в таблици с факти и измерения, които са денормализирани, за да опростят заявките и анализа.
Kimbal се основава на размерен модел, който е оптимизиран за заявки и отчети, което го прави идеален за приложения за бизнес разузнаване. Той обаче имаше проблеми с изолирането на тематично ориентирана информация, излишък на данни, несъвместими структури на заявки, трудности с мащабируемостта, непостоянна детайлност на таблиците с факти, проблеми със синхронизирането и необходимостта от дизайн отгоре надолу с изпълнение отдолу нагоре.
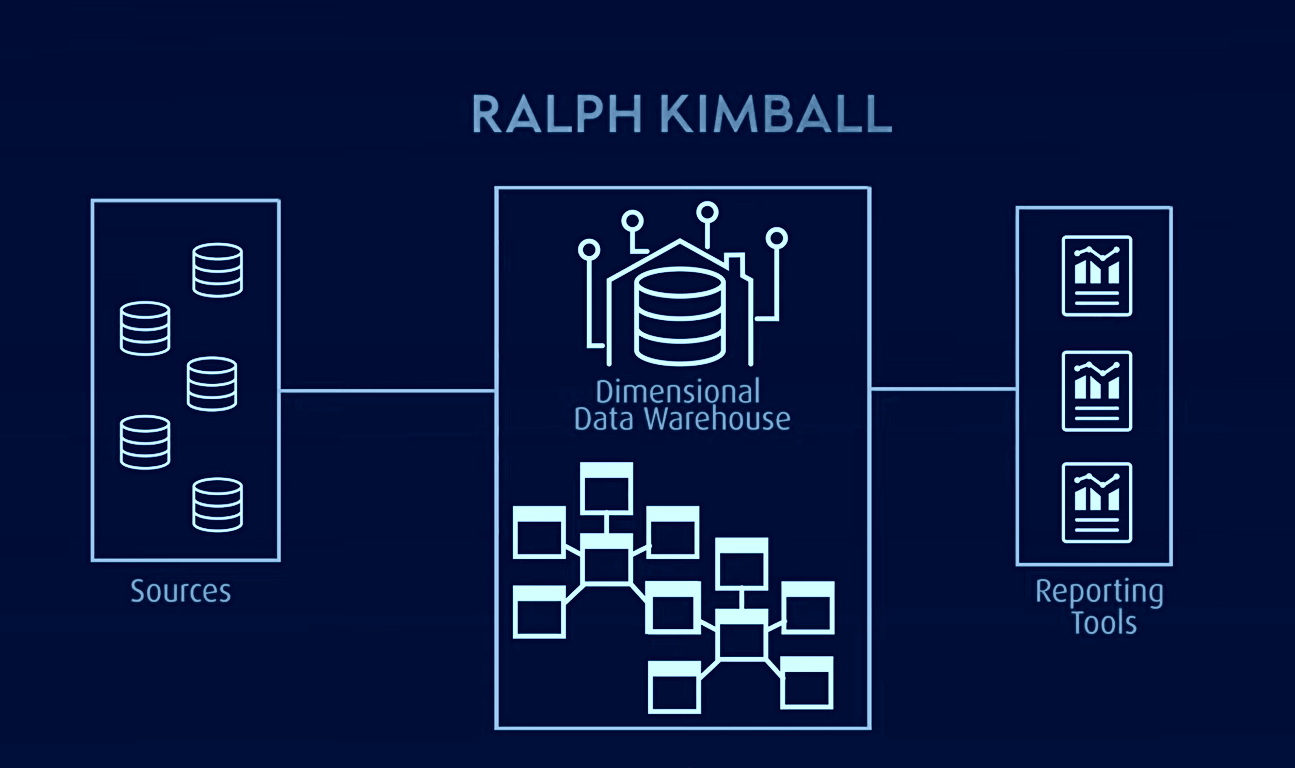
За разлика от тях, архитектурата на хранилището за данни е хибриден подход, който съчетава аспекти както на архитектурите 3NF, така и на Kimball. Това е модел, базиран на релационни принципи, нормализиране на данните и математика на излишъка, който представя връзките между обектите по различен начин и структурира по различен начин полетата на таблицата и времевите марки.
В тази архитектура всички данни се съхраняват в хранилище за необработени данни или езеро от данни, докато често използваните данни се съхраняват в нормализиран формат в бизнес хранилище, което съдържа исторически и специфични за контекста данни, които могат да се използват за отчитане.
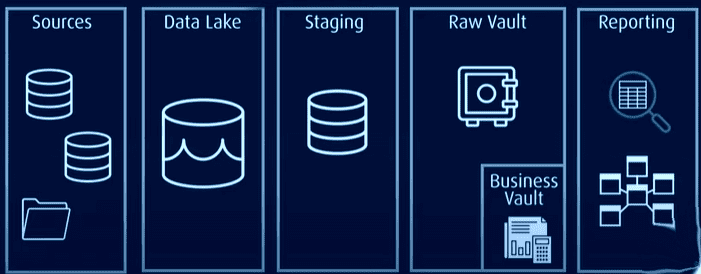
Data Vault адресира проблемите в традиционните модели, като е по-ефективен, мащабируем и гъвкав. Той позволява зареждане в почти реално време, по-добра цялост на данните и лесно разширяване, без да се засягат съществуващите структури. Моделът може също да бъде разширен без мигриране на съществуващите таблици.
Подход за моделиране Data StructureDesign Approach3NF ModelingTables в 3NFBottom-upKimbal ModelingStar Schema или Snowflake SchemaTop-downData VaultHub-and-SpokeBottom-up
Архитектура на Data Vault
Data Vault има архитектура hub-and-spoke и по същество се състои от три слоя:
Поетапен слой: Събира необработените данни от изходните системи, като CRM или ERP
Слой Data Warehouse: Когато е моделиран като модел Data Vault, този слой включва:
- Raw Data Vault: съхранява необработените данни.
- Хранилище за бизнес данни: включва хармонизирани и трансформирани данни въз основа на бизнес правила (по избор).
- Metrics Vault: съхранява информация за времето на изпълнение (по избор).
- Operational Vault: съхранява данните, които текат директно от операционните системи в хранилището на данни (по избор).
Data Mart Layer: Този слой моделира данни като звездна схема и/или други техники за моделиране. Предоставя информация за анализ и докладване.
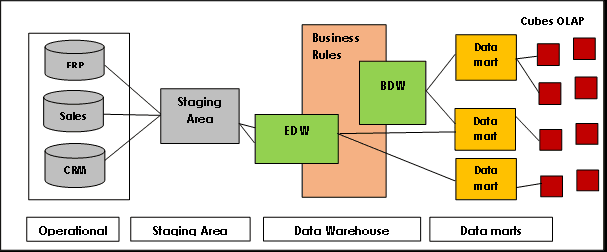 Източник на изображението: Lamia Yessad
Източник на изображението: Lamia Yessad
Data Vault не изисква преструктуриране. Новите функции могат да се изграждат паралелно директно с помощта на концепциите и методите на Data Vault, като съществуващите компоненти не се губят. Рамките могат значително да улеснят работата: те създават слой между хранилището на данни и разработчика и по този начин намаляват сложността на внедряването.
Компоненти на Data Vault
По време на моделирането Data Vault разделя цялата информация, принадлежаща на обекта, в три категории – за разлика от класическото моделиране на трета нормална форма. След това тази информация се съхранява строго отделена една от друга. Функционалните области могат да бъдат картографирани в Data Vault в така наречените хъбове, връзки и сателити:
#1. Хъбове
Хъбовете са сърцето на основната бизнес концепция, като клиент, продавач, продажба или продукт. Таблицата на концентратора се формира около бизнес ключа (име на магазина или местоположение), когато ново копие на този бизнес ключ се въведе за първи път в хранилището на данни.
Хъбът не съдържа описателна информация и FK. Състои се само от бизнес ключ, с генерирана от склад последователност от ID или хеш ключове, клеймо за дата/час на зареждане и източник на запис.
#2. Връзки
Връзките установяват връзки между бизнес ключовете. Всеки запис във връзка моделира nm връзки на произволен брой хъбове. Това позволява на хранилището за данни да реагира гъвкаво на промените в бизнес логиката на изходните системи, като например промени в сърдечността на взаимоотношенията. Точно като хъба, връзката не съдържа никаква описателна информация. Състои се от идентификаторите на последователностите на хъбовете, които препраща, генериран от склада идентификатор на последователност, клеймо за дата/час на зареждане и източник на запис.
#3. Сателити
Сателитите съдържат описателната информация (контекст) за бизнес ключ, съхранен в хъб, или връзка, съхранена във връзка. Сателитите работят „само за вмъкване“, което означава, че цялата история на данните се съхранява в сателита. Множество сателити могат да опишат един бизнес ключ (или връзка). Един сателит обаче може да опише само един ключ (хъб или връзка).
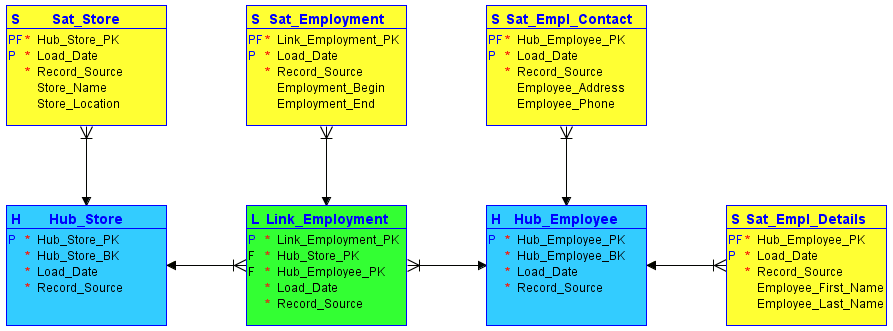 Източник на изображението: Carbidfischer
Източник на изображението: Carbidfischer
Как да изградите модел на хранилище за данни
Изграждането на модел на Data Vault включва няколко стъпки, всяка от които е критична за гарантиране, че моделът е мащабируем, гъвкав и способен да отговори на нуждите на бизнеса:
#1. Идентифицирайте обекти и атрибути
Идентифицирайте бизнес субектите и съответните им атрибути. Това включва тясна работа със заинтересованите страни в бизнеса, за да се разберат техните изисквания и данните, които трябва да съберат. След като тези обекти и атрибути бъдат идентифицирани, разделете ги на центрове, връзки и сателити.
#2. Дефиниране на връзки между обекти и създаване на връзки
След като идентифицирате обектите и атрибутите, връзките между обектите се дефинират и връзките се създават, за да представят тези взаимоотношения. На всяка връзка се присвоява бизнес ключ, който идентифицира връзката между обектите. След това сателитите се добавят, за да уловят атрибутите и връзките на обектите.
#3. Установете правила и стандарти
След създаването на връзки трябва да се установи набор от правила и стандарти за моделиране на хранилище за данни, за да се гарантира, че моделът е гъвкав и може да се справи с промените във времето. Тези правила и стандарти трябва да се преразглеждат и актуализират редовно, за да се гарантира, че остават уместни и съобразени с нуждите на бизнеса.
#4. Попълване на модела
След като моделът бъде създаден, той трябва да бъде попълнен с данни, като се използва подход на постепенно зареждане. Това включва зареждане на данните в хъбовете, връзките и сателитите с помощта на делта зареждания. Делтата се зарежда, за да гарантира, че се зареждат само промените, направени в данните, намалявайки времето и ресурсите, необходими за интегриране на данни.
#5. Тествайте и валидирайте модела
И накрая, моделът трябва да бъде тестван и валидиран, за да се гарантира, че отговаря на бизнес изискванията и е достатъчно мащабируем и гъвкав, за да се справи с бъдещи промени. Трябва да се извършват редовна поддръжка и актуализации, за да се гарантира, че моделът остава в съответствие с бизнес нуждите и продължава да предоставя унифициран изглед на данните.
Ресурси за обучение на Data Vault
Овладяването на Data Vault може да осигури ценни умения и знания, които са много търсени в днешните индустрии, управлявани от данни. Ето изчерпателен списък с ресурси, включително курсове и книги, които могат да помогнат в изучаването на тънкостите на Data Vault:
#1. Моделиране на Data Warehouse с Data Vault 2.0

Този курс на Udemy е изчерпателно въведение в подхода за моделиране на Data Vault 2.0, Agile управление на проекти и интеграция на Big Data. Курсът обхваща основите и основите на Data Vault 2.0, включително неговата архитектура и слоеве, бизнес и информационни трезори и усъвършенствани техники за моделиране.
Той ви учи как да проектирате модел на Data Vault от нулата, да конвертирате традиционни модели като 3NF и дименсионални модели в Data Vault и да разберете принципите на дименсионалното моделиране в Data Vault. Курсът изисква основни познания по бази данни и основи на SQL.
С висока оценка от 4,4 от 5 и над 1700 отзива, този най-продаван курс е подходящ за всеки, който иска да изгради здрава основа в Data Vault 2.0 и интеграцията на Big Data.
#2. Моделиране на хранилище за данни, обяснено със случай на употреба

Този курс на Udemy има за цел да ви насочи в изграждането на модел на хранилище за данни, използвайки практически бизнес пример. Той служи като ръководство за начинаещи в моделирането на Data Vault, като обхваща ключови концепции като подходящите сценарии за използване на модели на Data Vault, ограниченията на конвенционалното OLAP моделиране и систематичен подход за конструиране на модел на Data Vault. Курсът е достъпен за хора с минимални познания за бази данни.
#3. Гуруто на Data Vault: прагматично ръководство
Data Vault Guru от г-н Патрик Куба е изчерпателно ръководство за методологията на хранилището за данни, което предлага уникална възможност за моделиране на хранилище за данни на предприятието, като се използват принципи за автоматизация, подобни на тези, използвани при доставката на софтуер.
Книгата предоставя общ преглед на съвременната архитектура и след това предлага задълбочено ръководство за това как да се достави гъвкав модел на данни, който се адаптира към промените в предприятието, хранилището за данни.
Освен това книгата разширява методологията на хранилището за данни, като предоставя автоматизирана корекция на времевата линия, одитни пътеки, контрол на метаданни и интеграция с гъвкави инструменти за доставка.
#4. Изграждане на мащабируемо хранилище за данни с Data Vault 2.0
Тази книга предоставя на читателите изчерпателно ръководство за създаване на мащабируемо хранилище за данни от началото до края с помощта на методологията Data Vault 2.0.
Тази книга обхваща всички съществени аспекти на изграждането на мащабируемо хранилище за данни, включително техниката за моделиране на Data Vault, която е предназначена да предотврати типични повреди при съхранение на данни.
Книгата съдържа множество примери, за да помогне на читателите да разберат ясно концепциите. Със своите практически прозрения и примери от реалния свят тази книга е основен ресурс за всеки, който се интересува от съхранение на данни.
#5. Слонът в хладилника: Упътвани стъпки към успеха на Data Vault
„Слонът в хладилника“ от Джон Джайлс е практически наръчник, който има за цел да помогне на читателите да постигнат успех в Data Vault, като започнат с бизнеса и завършат с бизнеса.
Книгата се фокусира върху важността на корпоративната онтология и моделирането на бизнес концепции и предоставя стъпка по стъпка насоки как да приложите тези концепции за създаване на солиден модел на данни.
Чрез практически съвети и примерни модели авторът предлага ясно и лесно обяснение на сложни теми, което прави книгата отлично ръководство за тези, които са нови в Data Vault.
Заключителни думи
Data Vault представлява бъдещето на складирането на данни, предлагайки на компаниите значителни предимства по отношение на гъвкавост, мащабируемост и ефективност. Той е особено подходящ за фирми, които трябва бързо да зареждат големи обеми от данни и тези, които искат да развиват своите приложения за бизнес разузнаване по гъвкав начин.
Освен това компаниите, които имат съществуваща силозна архитектура, могат да се възползват значително от внедряването на основно хранилище за данни нагоре по веригата, използвайки Data Vault.
Може също да ви е интересно да научите за произхода на данните.