Командата на Linux curl може да направи много повече от изтегляне на файлове. Разберете на какво е способен curl и кога трябва да го използвате вместо wget.
Съдържание
curl срещу wget: Каква е разликата?
Хората често се борят да идентифицират относителните силни страни на командите wget и curl. Командите имат известно функционално припокриване. Всеки от тях може да извлича файлове от отдалечени места, но с това приликата свършва.
wget е a фантастичен инструмент за изтегляне на съдържание и файлове. Може да изтегля файлове, уеб страници и директории. Той съдържа интелигентни процедури за преминаване на връзки в уеб страници и рекурсивно изтегляне на съдържание в цял уебсайт. Той е ненадминат като мениджър за изтегляне от команден ред.
къдрица удовлетворява една съвсем различна нужда. Да, той може да извлича файлове, но не може рекурсивно да навигира в уебсайт, търсейки съдържание за извличане. Това, което curl всъщност прави, е да ви позволява да взаимодействате с отдалечени системи, като правите заявки към тези системи и извличате и показвате техните отговори към вас. Тези отговори може да са съдържание и файлове на уеб страница, но те също могат да съдържат данни, предоставени чрез уеб услуга или API в резултат на „въпроса“, зададен от заявката за curl.
И curl не се ограничава само до уебсайтове. curl поддържа над 20 протокола, включително HTTP, HTTPS, SCP, SFTP и FTP. И може да се каже, че поради превъзходното си боравене с Linux pipe, curl може по-лесно да се интегрира с други команди и скриптове.
Авторът на curl има уеб страница, която описва разликите, които вижда между curl и wget.
Инсталиране на curl
От компютрите, използвани за изследване на тази статия, Fedora 31 и Manjaro 18.1.0 вече имаха инсталиран curl. curl трябваше да бъде инсталиран на Ubuntu 18.04 LTS. В Ubuntu изпълнете тази команда, за да я инсталирате:
sudo apt-get install curl

Версията на къдриците
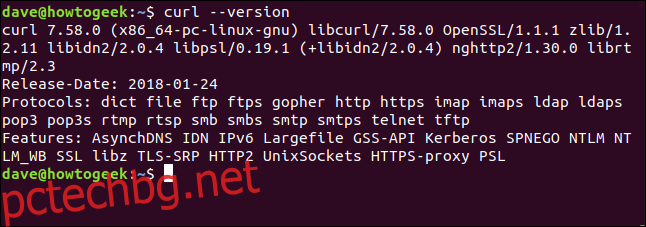
Опцията –version прави curlreport своя версия. Той също така изброява всички протоколи, които поддържа.
curl --version
Извличане на уеб страница
Ако посочим curl към уеб страница, тя ще я извлече вместо нас.
curl https://www.bbc.com

Но неговото действие по подразбиране е да го изхвърли в прозореца на терминала като изходен код.
Внимание: Ако не кажете на curl, че искате нещо да се съхранява като файл, той винаги ще го изхвърли в прозореца на терминала. Ако файлът, който извлича, е двоичен файл, резултатът може да бъде непредсказуем. Shell може да се опита да интерпретира някои от стойностите на байтовете в двоичния файл като контролни символи или escape последователности.
Записване на данни във файл
Нека кажем на curl да пренасочи изхода във файл:
curl https://www.bbc.com > bbc.html

Предоставената информация е:
% Общо: Общата сума, която трябва да бъде извлечена.
% Получени: Процентът и действителните стойности на данните, извлечени до момента.
% Xferd: Процентът и действително изпратените, ако данните се качват.
Средна скорост на изтегляне: Средната скорост на изтегляне.
Средна скорост на качване: Средната скорост на качване.
Общо време: Приблизителната обща продължителност на трансфера.
Прекарано време: Времето, изминало досега за този трансфер.
Оставащо време: Очакваното оставащо време за завършване на трансфера
Текуща скорост: Текущата скорост на трансфер за този трансфер.
Тъй като пренасочихме изхода от curl към файл, сега имаме файл, наречен „bbc.html“.
Щракването двукратно върху този файл ще отвори вашия браузър по подразбиране, така че да покаже извлечената уеб страница.
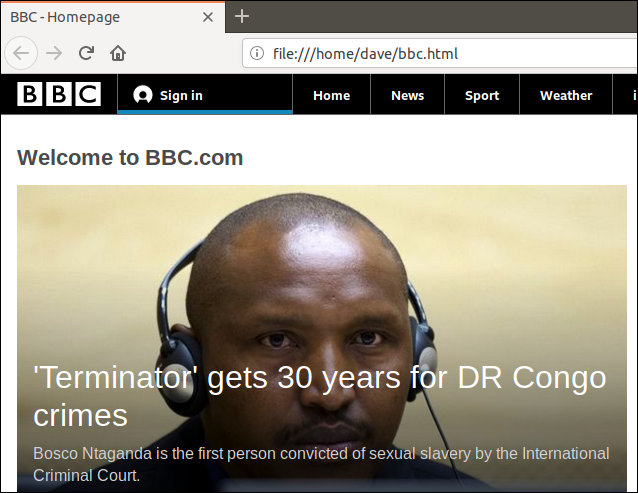
Имайте предвид, че адресът в адресната лента на браузъра е локален файл на този компютър, а не отдалечен уебсайт.
Не е нужно да пренасочваме изхода, за да създадем файл. Можем да създадем файл, като използваме опцията -o (изход) и кажем на curl да създаде файла. Тук използваме опцията -o и предоставяме името на файла, който искаме да създадем „bbc.html“.
curl -o bbc.html https://www.bbc.com
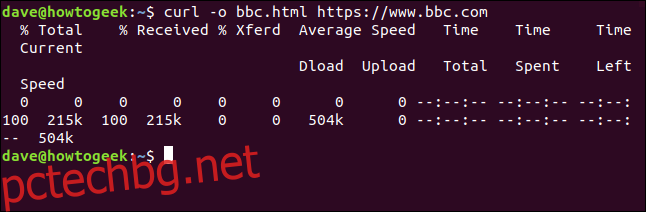
Използване на лента за напредък за наблюдение на изтеглянията
За да бъде заменена текстовата информация за изтегляне с обикновена лента за напредък, използвайте опцията -# (лента на напредъка).
curl -x -o bbc.html https://www.bbc.com

Рестартиране на прекъснато изтегляне
Лесно е да рестартирате изтегляне, което е прекратено или прекъснато. Нека започнем изтегляне на голям файл. Ще използваме най-новата сборка за дългосрочна поддръжка на Ubuntu 18.04. Използваме опцията –output, за да посочим името на файла, в който искаме да го запишем: „ubuntu180403.iso.“
curl --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Изтеглянето започва и върви към завършване.
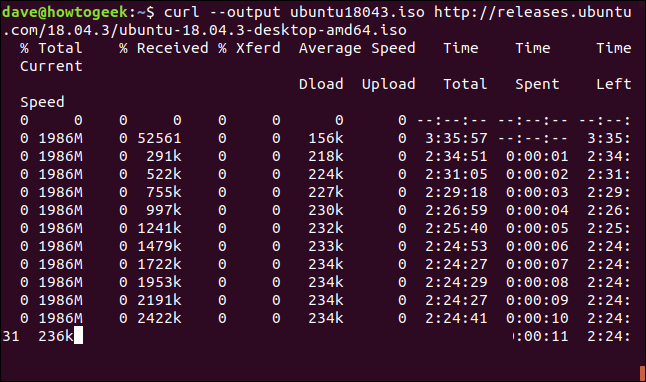
Ако принудително прекъснем изтеглянето с Ctrl+C, се връщаме към командния ред и изтеглянето се прекратява.
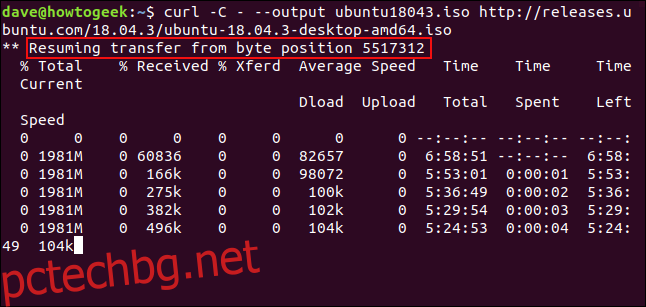
За да рестартирате изтеглянето, използвайте опцията -C (продължете в). Това кара curl да рестартира изтеглянето в определена точка или отместване в рамките на целевия файл. Ако използвате тире – като отместване, curl ще разгледа вече изтеглената част от файла и ще определи правилното отместване, което да използва за себе си.
curl -C - --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Изтеглянето се рестартира. curl отчита изместването, при което се рестартира.
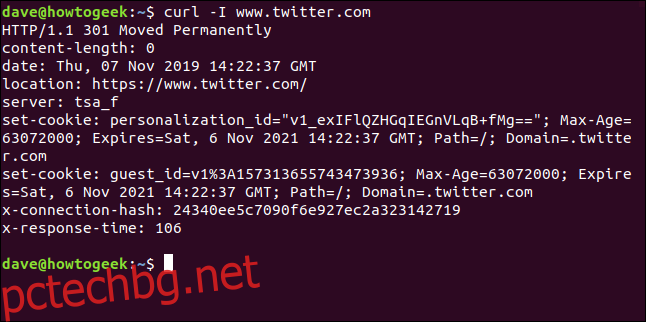
Извличане на HTTP заглавки
С опцията -I (head) можете да извлечете само HTTP заглавките. Това е същото като изпращането на HTTP HEAD команда към уеб сървър.
curl -I www.twitter.com

Тази команда извлича само информация; не изтегля никакви уеб страници или файлове.
Изтегляне на множество URL адреси
С помощта на xargs можем да изтеглим множество URL адреси веднага. Може би искаме да изтеглим серия от уеб страници, които съставляват една статия или урок.
Копирайте тези URL адреси в редактор и го запазете във файл, наречен „urls-to-download.txt“. Можем да използваме xargs за третирайте съдържанието на всеки ред на текстовия файл като параметър, който на свой ред ще подава, за да се навие.
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#0 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#1 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#2 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#3 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#4 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#5
Това е командата, която трябва да използваме, за да накараме xargs да предадат тези URL адреси, за да се навиват един по един:
xargs -n 1 curl -ONote that this command uses the -O (remote file) output command, which uses an uppercase “O.” This option causes curl to save the retrieved file with the same name that the file has on the remote server.
The -n 1 option tells xargs to treat each line of the text file as a single parameter.
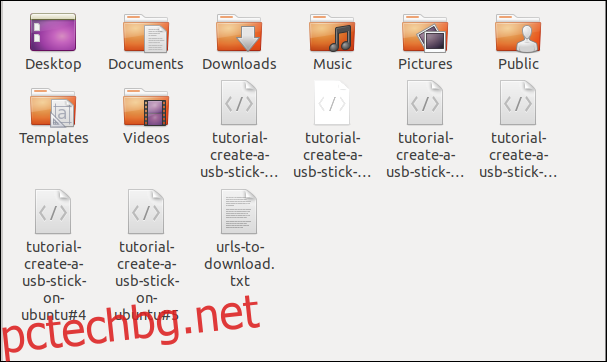
When you run the command, you’ll see multiple downloads start and finish, one after the other.
Checking in the file browser shows the multiple files have been downloaded. Each one bears the name it had on the remote server.
Downloading Files From an FTP Server
Using curl with a File Transfer Protocol (FTP) server is easy, even if you have to authenticate with a username and password. To pass a username and password with curl use the -u (user) option, and type the username, a colon “:”, and the password. Don’t put a space before or after the colon.
This is a free-for-testing FTP server hosted by Rebex. The test FTP site has a pre-set username of “demo”, and the password is “password.” Don’t use this type of weak username and password on a production or “real” FTP server.
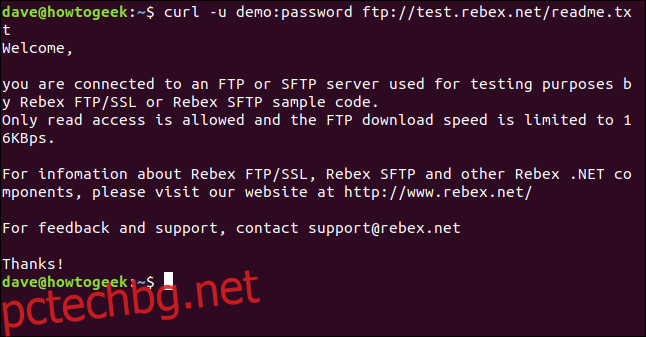
curl -u demo:password ftp://test.rebex.net
curl разбира, че го насочваме към FTP сървър, и връща списък с файловете, които присъстват на сървъра.
Единственият файл на този сървър е файл “readme.txt” с дължина 403 байта. Нека го извлечем. Използвайте същата команда като преди малко, с добавено име на файла към нея:
curl -u demo:password ftp://test.rebex.net/readme.txt
Файлът се извлича и curl показва съдържанието му в прозореца на терминала.
В почти всички случаи ще бъде по-удобно извлеченият файл да бъде запазен на диск за нас, вместо да се показва в прозореца на терминала. Още веднъж можем да използваме изходната команда -O (отдалечен файл), за да запазим файла на диск със същото име на файла, което има на отдалечения сървър.
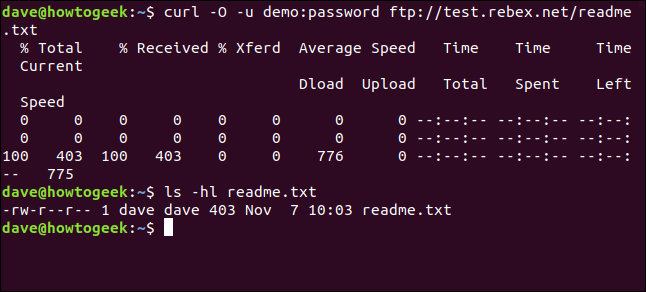
curl -O -u demo:password ftp://test.rebex.net/readme.txt
Файлът се извлича и записва на диск. Можем да използваме ls, за да проверим подробностите за файла. Той има същото име като файла на FTP сървъра и е със същата дължина, 403 байта.
ls -hl readme.txt
Изпращане на параметри към отдалечени сървъри
Някои отдалечени сървъри ще приемат параметри в заявките, които се изпращат до тях. Параметрите могат да се използват за форматиране на върнатите данни, например, или могат да се използват за избор на точните данни, които потребителят желае да извлече. Често е възможно да взаимодействате с уеб интерфейси за програмиране на приложения (API) с помощта на curl.
Като прост пример, ipify уебсайтът има API, може да бъде поискано да се установи вашия външен IP адрес.
curl https://api.ipify.orgКато добавим параметъра format към командата, със стойността на “json” можем отново да поискаме нашия външен IP адрес, но този път върнатите данни ще бъдат кодирани в JSON формат.
curl https://api.ipify.org?format=json
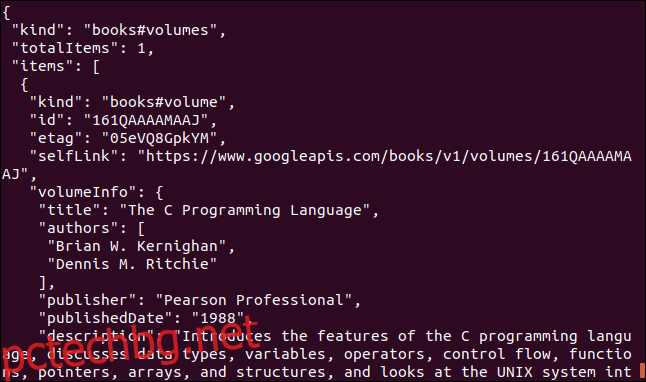
Ето още един пример, който използва API на Google. Той връща JSON обект, описващ книга. Параметърът, който трябва да предоставите, е Международен стандартен номер на книга (ISBN) номер на книга. Можете да ги намерите на задната корица на повечето книги, обикновено под баркод. Параметърът, който ще използваме тук, е „0131103628.“
curl https://www.googleapis.com/books/v1/volumes?q=isbn:0131103628
Върнатите данни са изчерпателни:
Понякога навийте, понякога wget
Ако искам да изтегля съдържание от уебсайт и дървовидната структура на уебсайта да търси рекурсивно това съдържание, бих използвал wget.
Ако исках да взаимодействам с отдалечен сървър или API и евентуално да изтегля някои файлове или уеб страници, бих използвал curl. Особено ако протоколът е един от многото, които не се поддържат от wget.