
Конвейерът за агрегиране е препоръчителният начин за изпълнение на сложни заявки в MongoDB. Ако сте използвали MapReduce на MongoDB, по-добре преминете към тръбопровода за агрегиране за по-ефективни изчисления.
Съдържание
Какво е агрегиране в MongoDB и как работи?
Конвейерът за агрегиране е многоетапен процес за изпълнение на разширени заявки в MongoDB. Той обработва данни през различни етапи, наречени конвейер. Можете да използвате резултатите, генерирани от едно ниво, като оперативен шаблон в друго.
Например, можете да прехвърлите резултата от операция за съвпадение на друг етап за сортиране в този ред, докато получите желания резултат.
Всеки етап от тръбопровода за агрегиране включва MongoDB оператор и генерира един или повече трансформирани документи. В зависимост от вашата заявка, едно ниво може да се появи няколко пъти в конвейера. Например може да се наложи да използвате етапите на оператора $count или $sort повече от веднъж в целия тръбопровод за агрегиране.
Етапите на тръбопровода за агрегиране
Конвейерът за агрегиране преминава данните през множество етапи в една заявка. Има няколко етапа и можете да намерите техните подробности в MongoDB документация.
Нека дефинираме някои от най-често използваните по-долу.
Етапът на $match
Този етап ви помага да дефинирате конкретни условия за филтриране, преди да започнете другите етапи на агрегиране. Можете да го използвате, за да изберете съвпадащите данни, които искате да включите в тръбопровода за агрегиране.
$груповата сцена
Груповият етап разделя данните в различни групи въз основа на специфични критерии, използвайки двойки ключ-стойност. Всяка група представлява ключ в изходния документ.
Например, разгледайте следните примерни данни за продажби:
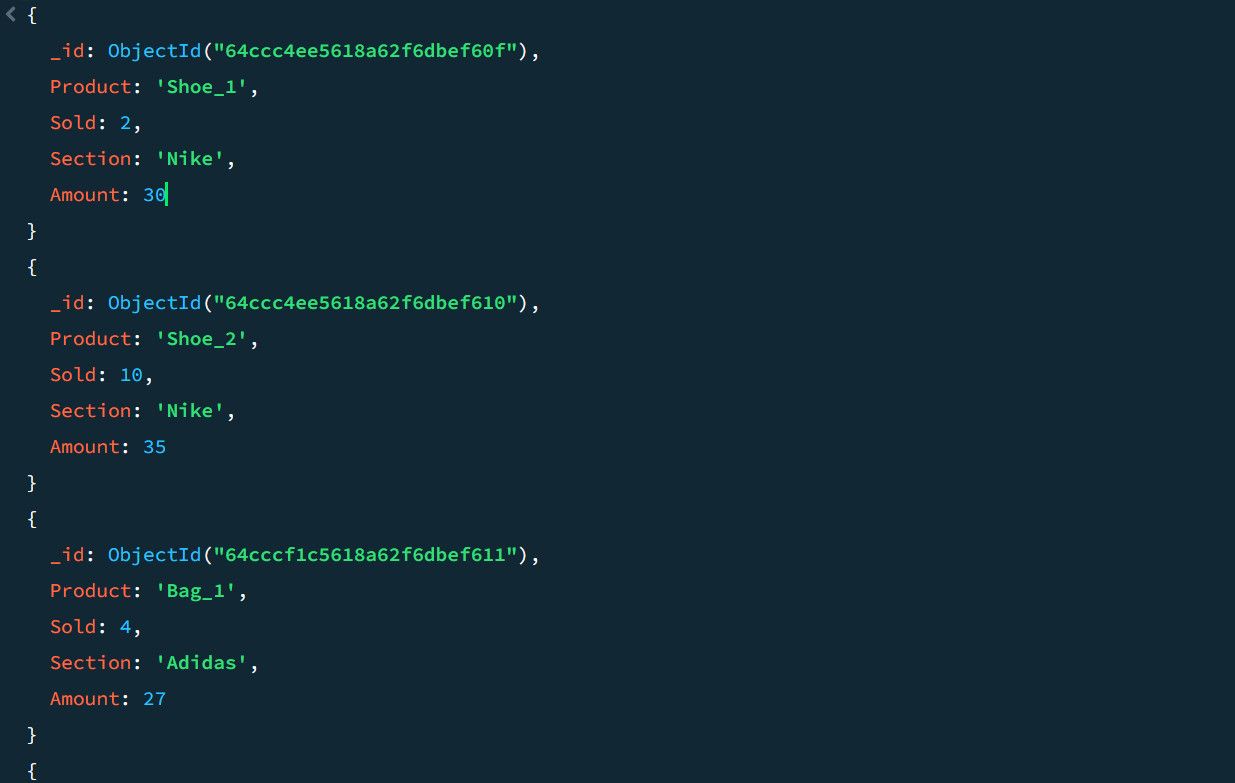
Използвайки тръбопровода за обобщаване, можете да изчислите общия брой продажби и най-добрите продажби за всяка продуктова секция:
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
}
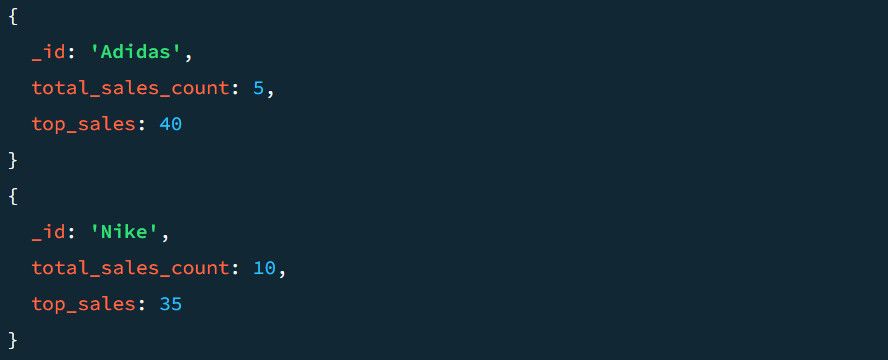
Двойката _id: $Section групира изходния документ въз основа на секциите. Чрез посочване на полетата top_sales_count и top_sales, MongoDB създава нови ключове въз основа на операцията, дефинирана от агрегатора; това може да бъде $sum, $min, $max или $avg.
Етапът $skip
Можете да използвате етапа $skip, за да пропуснете определен брой документи в изхода. Обикновено идва след груповата фаза. Например, ако очаквате два изходни документа, но пропуснете един, агрегирането ще изведе само втория документ.
За да добавите етап на пропускане, вмъкнете операцията $skip в конвейера за агрегиране:
...,
{
$skip: 1
},
Етапът на $sort
Етапът на сортиране ви позволява да подредите данните в низходящ или възходящ ред. Например, можем допълнително да сортираме данните в предишния пример на заявка в низходящ ред, за да определим кой раздел има най-високи продажби.
Добавете оператора $sort към предишната заявка:
...,
{
$sort: {top_sales: -1}
},
Етапът на $limit
Операцията за ограничаване помага за намаляване на броя на изходните документи, които искате да показва тръбопроводът за агрегиране. Например, използвайте оператора $limit, за да получите секцията с най-високи продажби, върната от предишния етап:
...,
{
$sort: {top_sales: -1}
},{"$limit": 1}
Горното връща само първия документ; това е секцията с най-високи продажби, тъй като се появява в горната част на сортирания резултат.
Етапът $project
Етапът $project ви позволява да оформите изходния документ както желаете. С помощта на оператора $project можете да посочите кое поле да включите в изхода и да персонализирате името на неговия ключ.
Например примерен резултат без $project етап изглежда така:
Нека да видим как изглежда с етапа $project. За да добавите $project към конвейера:
...,{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",}
}
Тъй като преди това сме групирали данните въз основа на продуктови секции, горното включва всяка продуктова секция в изходния документ. Той също така гарантира, че обобщеният брой продажби и най-добрите продажби се включват в изхода като TotalSold и TopSale.
Крайният резултат е много по-чист в сравнение с предишния:

Етапът $unwind
Етапът $unwind разбива масив в рамките на документ на отделни документи. Вземете например следните данни за поръчки:
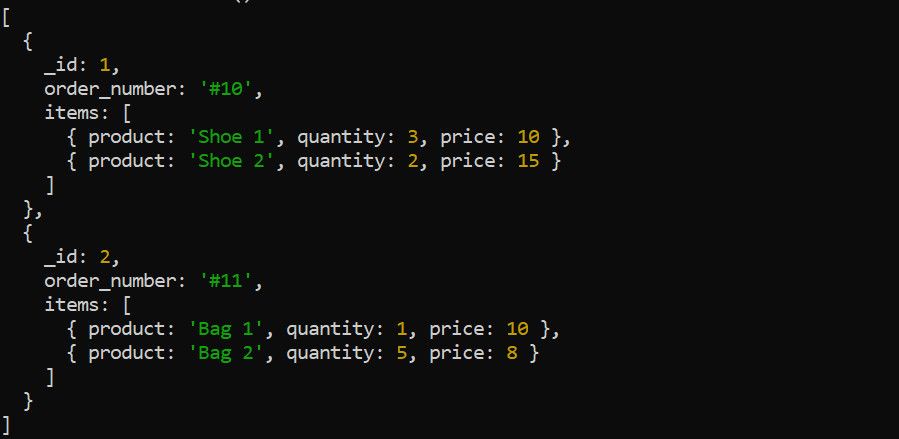
Използвайте етапа $unwind, за да деконструирате масива от елементи, преди да приложите други етапи на агрегиране. Например, разгъването на масива с елементи има смисъл, ако искате да изчислите общия приход за всеки продукт:
db.Orders.aggregate(
[
{
"$unwind": "$items"
},
{
"$group": {
"_id": "$items.product",
"total_revenue": { "$sum": { "$multiply": ["$items.quantity", "$items.price"] } }
}
},
{
"$sort": { "total_revenue": -1 }
},{
"$project": {
"_id": 0,
"Product": "$_id",
"TotalRevenue": "$total_revenue",}
}
])
Ето резултата от горната заявка за обобщаване:

Как да създадете тръбопровод за агрегиране в MongoDB
Докато конвейерът за агрегиране включва няколко операции, представените по-рано етапи ви дават представа как да ги приложите в конвейера, включително основната заявка за всеки.
Използвайки предишната извадка от данни за продажбите, нека разгледаме някои от етапите, обсъдени по-горе, на едно място за по-широк поглед върху тръбопровода за агрегиране:
db.sales.aggregate([{
"$match": {
"Sold": { "$gte": 5 }
}
},{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}},
{
"$sort": { "top_sales": -1 }
},{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",}
}
])
Крайният резултат изглежда като нещо, което сте виждали преди:
Конвейер за агрегиране срещу MapReduce
До оттеглянето му от MongoDB 5.0, конвенционалният начин за агрегиране на данни в MongoDB беше чрез MapReduce. Въпреки че MapReduce има по-широки приложения отвъд MongoDB, той е по-малко ефективен от тръбопровода за агрегиране, изисквайки скриптове на трети страни, за да напишат отделно картата и функциите за намаляване.
Тръбопроводът за агрегиране, от друга страна, е специфичен само за MongoDB. Но предоставя по-чист и по-ефективен начин за изпълнение на сложни заявки. Освен простотата и мащабируемостта на заявките, представените етапи на тръбопровода правят изхода по-персонализиран.
Има много повече разлики между тръбопровода за агрегиране и MapReduce. Ще ги видите, докато превключвате от MapReduce към тръбопровода за агрегиране.
Направете заявките за големи данни ефективни в MongoDB
Вашата заявка трябва да бъде възможно най-ефективна, ако искате да извършвате задълбочени изчисления върху сложни данни в MongoDB. Конвейерът за агрегиране е идеален за разширени заявки. Вместо да манипулирате данни в отделни операции, което често намалява производителността, агрегирането ви позволява да ги опаковате всички в един производителен конвейер и да ги изпълните веднъж.
Въпреки че тръбопроводът за агрегиране е по-ефективен от MapReduce, можете да направите агрегирането по-бързо и по-ефективно, като индексирате вашите данни. Това ограничава количеството данни, които MongoDB трябва да сканира по време на всеки етап на агрегиране.