

Ако сте научили няколко езика за компютърно програмиране, може би сте чували термина анализиране на текст. Това се използва за опростяване на сложните стойности на данните във файла. Статията ви помага да разберете как да анализирате текст с помощта на езика. В допълнение към това, ако сте се сблъсквали с грешка при синтактичния анализ на текст x, ще знаете как да коригирате грешката при синтактичния анализ в статията.

Съдържание
Как да анализирате текст
В тази статия показахме пълно ръководство за анализиране на текст по различни начини и също така дадохме накратко въведение в анализа на текст.
Какво представлява анализирането на текст?
Преди да се задълбочите, за да научите концепциите за анализиране на текст с помощта на произволен код. Важно е да знаете за основите на езика и кодирането.
НЛП или обработка на естествен език
За анализиране на текст се използва обработка на естествен език или NLP, което е подполе на домейна на изкуствения интелект. Езикът Python, който е един от езиците, принадлежащи към категорията, се използва за анализиране на текст.
NLP кодовете позволяват на компютрите да разбират и обработват човешки езици, за да ги направят подходящи за различни приложения. За да се приложат ML или техники за машинно обучение към езика, неструктурираните текстови данни трябва да бъдат преобразувани в структурирани таблични данни. За завършване на дейността по анализиране езикът Python се използва за промяна на програмните кодове.
Какво представлява анализирането на текст?
Разборът на текст просто означава преобразуване на данните от един формат в друг формат. Форматът, в който е записан файлът, трябва да бъде анализиран или преобразуван във файл в различен формат, за да може потребителят да го използва в различни приложения.
- С други думи, процесът означава анализиране на низ или текст и преобразуване в логически компоненти чрез промяна на формата на файла.
- Някои правила на езика Python се използват за изпълнение на тази обща програмна задача. Докато се анализира текст, дадената поредица от текст се разбива на по-малки компоненти.
Какви са причините за разбор на текст?
Причините, поради които текстът трябва да бъде анализиран, са дадени в този раздел и това е предпоставка за знания, преди да знаете как да анализирате текст.
- Всички компютъризирани данни няма да бъдат в един и същ формат и може да се различават в зависимост от различните приложения.
- Форматите на данните варират за различните приложения и несъвместим код би довел до тази грешка.
- Няма индивидуална универсална компютърна програма за избор на данни от всички формати на данни.
Метод 1: Чрез клас DataFrame
Класът DataFrame на езика Python има всички необходими функции за анализиране на текст. Тази вградена библиотека съдържа необходимите кодове за анализиране на данни от произволен формат в друг формат.
Кратко представяне на клас DataFrame
DataFrame Class е богата на функции структура от данни, която се използва като инструмент за анализ на данни. Това е мощен инструмент за анализ на данни, който може да се използва за анализ на данни с минимални усилия.
- Кодът се чете в pandas DataFrame за извършване на анализа на езика Python.
- Класът идва с многобройни пакети, предоставени от pandas, които се използват от анализатори на данни на Python.
- Характеристиката на този клас е абстракция, код, в който вътрешната функционалност на функцията е скрита от потребителите, на библиотеката NumPy. Библиотеката NumPy е библиотека на Python, която обхваща командите и функциите за работа с масиви.
- Класът DataFrame може да се използва за изобразяване на двуизмерен масив с множество индекси на редове и колони. Тези индекси помагат при съхраняването на многоизмерни данни и следователно се наричат MultiIndex. Те трябва да бъдат променени, за да се знае как да се коригира грешката при анализ.
Пандите на езика Python помагат при извършването на операции в стил SQL или бази данни с най-голямо съвършенство, за да се избегне грешка при анализ на текст x. Той също така съдържа някои IO инструменти, които помагат при анализирането на файлове от CSV, MS Excel, JSON, HDF5 и други формати на данни.
Процес на анализиране на текст с помощта на клас DataFrame
За да знаете как да анализирате текст, можете да използвате стандартния процес, като използвате класа DataFrame, даден в този раздел.
- Дешифрирайте формата на данните на входните данни.
- Решете изходните данни на данните като CSV или стойност, разделена със запетая.
- Напишете върху кода примитивен тип данни като list или dict.
Забележка: Писането на кода върху празен DataFrame може да бъде досадно и сложно. Пандите позволяват създаването на данни в класа DataFrame от тези типове данни. Следователно данните в примитивния тип данни могат лесно да бъдат анализирани до необходимия формат на данните.
- Анализирайте данните с помощта на инструмента за анализ на данни, pandas DataFrame, и отпечатайте резултата.
Вариант I: Стандартен формат
Стандартният метод за форматиране на всеки файл с определен формат на данни като CSV е обяснен тук.
- Запазете файла със стойностите на данните локално на вашия компютър. Например, можете да наименувате файла data.txt.
- Импортирайте файла в pandas с конкретно име и импортирайте данните в друга променлива. Например пандите на езика се импортират в името pd в дадения код.
- Импортирането трябва да има пълен код с подробности за името на входния файл, функцията и формата на входния файл.
Забележка: Тук променливата с име res се използва за извършване на функцията за четене на данните във файла data.txt с помощта на панди, импортирани в pd. Форматът на данните на въведения текст е зададен във формат CSV.
- Извикайте посочения тип файл и анализирайте анализирания текст върху отпечатания резултат. Например командата res след изпълнението на командния ред ще помогне при отпечатването на анализирания текст.
Примерен код за процеса, описан по-горе, е даден по-долу и ще ви помогне да разберете как да анализирате текст.
import pandas as pd res = pd.read_csv(‘data.txt’) res
В този случай, ако въведете стойностите на данните във файла data.txt, като напр [1,2,3]то ще бъде анализирано и показано като 1 2 3.
Вариант II: Стрингов метод
Ако текстът, даден на кода, съдържа само низове или буквени знаци, специалните знаци в низа, като запетаи, интервал и т.н., могат да се използват за разделяне и анализ на текста. Процесът е подобен на обичайните вътрешни операции с низове. За да намерите как да поправите грешка при анализиране, трябва да следвате процеса на анализиране на текста с помощта на тази опция, обяснен по-долу.
- Данните се извличат от низа и се отбелязват всички специални знаци, които разделят текста.
Например в кода, даден по-долу, специалните символи в низа my_string, които са, ‘,’ и ‘:’ са идентифицирани. Този процес трябва да се извършва внимателно, за да се избегне грешка при разбор на текст x.
- Текстът в низа се разделя индивидуално въз основа на стойностите и позицията на специалните знаци.
Например, низът се разделя на стойности на текстови данни въз основа на специалните символи, идентифицирани с помощта на командата split.
- Стойностите на данните на низа се отпечатват самостоятелно като анализиран текст. Тук изразът за печат се използва за отпечатване на анализираната стойност на данните на текста.
Примерният код за процеса, описан по-горе, е даден по-долу.
my_string = ‘Names: Tech, computer’
sfinal = [name.strip() for name in my_string.split(‘:’)[1].split(‘,’)]
print(“Names: {}”.format(sfinal))
В този случай резултатът от анализирания низ ще се покаже, както е показано по-долу.
Names: [‘Tech’, ‘computer’]
За да получите по-голяма яснота и да знаете как да анализирате текст, докато използвате низовия текст, се използва for цикъл и кодът се модифицира, както следва.
my_string = ‘Names: Tech, computer’
s1 = my_string.split(‘:’)
s2 = s1[1]
s3 = s2.split(‘,’)
s4 = [name.strip() for name in s3]
for idx, item in enumerate([s1, s2, s3, s4]):
print(“Step {}: {}”.format(idx, item))
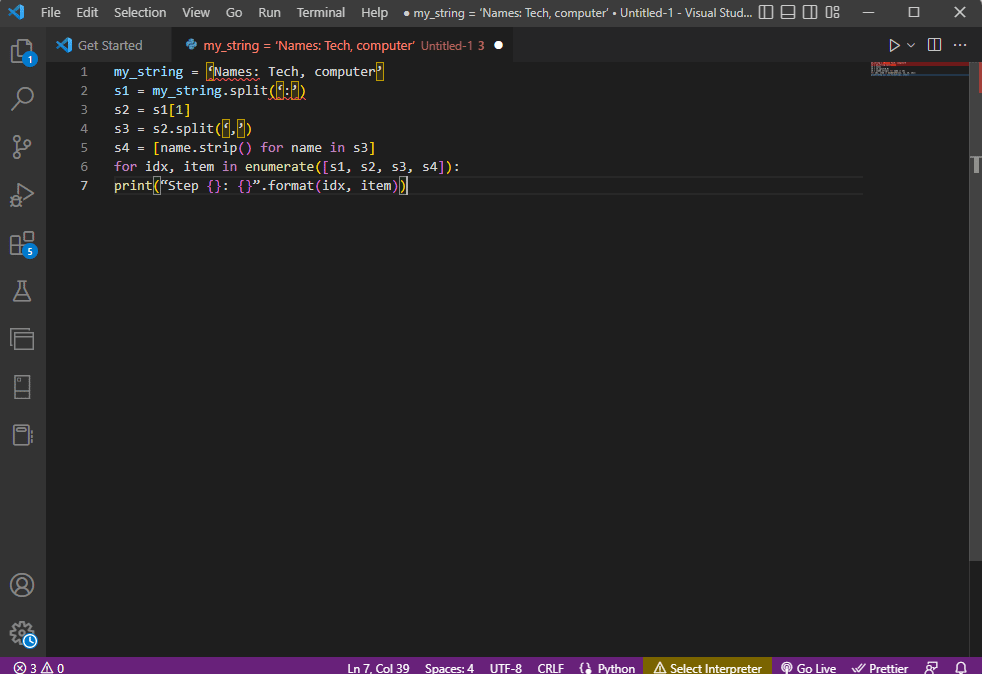
Резултатът от анализирания текст за всяка от тези стъпки се показва, както е дадено по-долу. Можете да забележите, че в Стъпка 0 низът е разделен въз основа на специалния знак: и стойностите на текстовите данни са разделени въз основа на знака в следващите стъпки.
Step 0: [‘Names’, ‘Tech, computer’] Step 1: Tech, computer Step 2: [‘ Tech’, ‘ computer’] Step 3: [‘Tech’, ‘computer’]
Вариант III: Разбор на сложен файл
В повечето случаи файловите данни, които трябва да бъдат анализирани, съдържат различни типове данни и стойности на данни. В този случай може да е трудно да анализирате файла чрез методите, обяснени по-рано.
Характеристиките на анализирането на сложните данни във файла са да накарат стойностите на данните да се показват в табличен формат.
- Заглавието или метаданните на стойностите се отпечатват в горната част на файла,
- Променливите и полетата се отпечатват в изхода в таблична форма и
- Стойностите на данните образуват съставен ключ.
Преди да се задълбочите в изучаването на това как да анализирате текст в този метод, е необходимо да научите няколко основни концепции. Анализът на стойностите на данните се извършва въз основа на регулярни изрази или Regex.
Модели на регулярни изрази
За да знаете как да поправите грешка при анализиране, трябва да се уверите, че моделите на регулярни изрази в изразите са правилни. Кодът за анализиране на стойностите на данните на низовете ще включва често срещаните модели на Regex, изброени по-долу в този раздел.
-
‘d’ : съответства на десетичната цифра в низа,
-
‘s’ : съвпада със знака за интервал,
-
‘w’: съответства на буквено-цифровия знак,
-
‘+’ или ‘*’ : извършва алчно съпоставяне чрез съвпадение на един или повече символи в низовете,
-
‘a-z’ : съответства на групите с малки букви в стойностите на текстовите данни,
-
‘A-Z’ или ‘a-z’ : съответства на групите с главни и малки букви на низа и
-
‘0-9’ : съответства на числовите стойности.
Регулярни изрази
Модулите за регулярен израз са основна част от пакета pandas в езика Python и грешен re може да доведе до грешка при анализ на текст x. Това е малък език, вграден в Python за намиране на низовия модел в израза. Регулярните изрази или Regex са низове със специален синтаксис. Тя позволява на потребителя да съпоставя шаблони в други низове въз основа на стойностите в низовете.
Regex се създава въз основа на типа данни и изискването на израза в низа, като например „Низ = (.*)n. Регулярният израз се използва преди шаблона във всеки израз. Символите, използвани в регулярните изрази, са изброени по-долу и ще ви помогнат да знаете как да анализирате текст.
-
. : за извличане на произволен знак от данните,
-
* : използвайте нула или повече данни от предишния израз,
-
(.*) : за групиране на част от регулярния израз в скобите,
-
n : Създайте нов знак в края на реда в кода,
-
d : създайте кратка интегрална стойност в диапазона от 0 до 9,
-
+ : използвайте една или повече данни от предишния израз и
-
| : създаване на логическо твърдение; използвани за или изрази.
RegexObjects
RegexObject е върната стойност за функцията за компилиране и се използва за връщане на MatchObject, ако изразът съвпада със стойността на съвпадение.
1. MatchObject
Тъй като булевата стойност на MatchObject винаги е True, можете да използвате оператор if, за да идентифицирате положителните съвпадения в обекта. В случай на използване на оператора if, групата, посочена от индекса, се използва за намиране на съвпадението на обекта в израза.
-
group() връща една или повече подгрупи от съвпадение,
-
group(0) връща цялото съвпадение,
-
group(1) връща първата подгрупа в скоби и
- Докато говорим за множество групи, трябва да използваме специфично за Python разширение. Това разширение се използва за указване на името на групата, в която трябва да се намери съвпадението. Конкретното разширение е предоставено в групата в скоби. Например, изразът (?P
regex1) ще се отнася до конкретната група с име group1 и ще проверява за съвпадение в регулярния израз, regex1. За да научите как да коригирате грешка при анализиране, трябва да проверите дали групата е насочена правилно.
2. Методи на MatchObject
Докато намирате как да анализирате текст, е важно да знаете, че MatchObject има два основни метода, както са изброени по-долу. Ако MatchObject бъде намерен в указания израз, той ще върне своя екземпляр, в противен случай ще върне None.
- Методът match(string) се използва за намиране на съвпаденията на низа в началото на регулярния израз и
- Методът search(string) се използва за сканиране през низа, за да се намери местоположението за съвпадение в регулярния израз.
Функции с регулярен израз
Функциите Regex са кодови редове, които се използват за изпълнение на определена функция, както е посочено от потребителя от набора от получени стойности на данни.
Забележка: За да се напишат функциите, необработените низове се използват за регулярните изрази, за да се избегне грешка при анализ на текст x. Това се прави чрез добавяне на долен индекс r преди всеки шаблон в израза.
Общите функции, използвани в изразите, са обяснени по-долу.
1. re.findall()
Тази функция връща всички модели в низа, ако бъде намерено съвпадение, и връща празен списък, ако не бъде намерено съвпадение. Например функцията string = re.findall(‘[aeiou]’, regex_filename) се използва за намиране на гласната в името на файла.
2. re.split()
Тази функция се използва за разделяне на низа в случай на съвпадение с указан символ, като например интервал. В случай че не бъде намерено съвпадение, той връща празен низ.
3. re.sub()
Функцията замества съответстващия текст със съдържанието на дадената заместваща променлива. Противно на други функции, ако не бъде намерен модел, се връща оригиналният низ.
4. re.search()
Една от основните функции, които помагат да научите как да анализирате текст, е функцията за търсене. Помага при търсене на модела в низа и връщане на съвпадащия обект. Ако търсенето не успее да идентифицира съвпадението, не се връща стойност.
5. re.compile(pattern)
Тази функция се използва за компилиране на модели на регулярен израз в RegexObject, който беше обсъден по-рано.
Други изисквания
Изброените изисквания са допълнителна функция, използвана от напреднали програмисти при анализ на данни.
- За визуализиране на регулярния израз се използва regexper и
- За тестване на регулярния израз се използва regex101.
Процес на анализиране на текст
Методът за анализиране на текста в тази сложна опция е описан по-долу.
- Най-важната стъпка е да разберете входния формат, като прочетете съдържанието на файла. Например функциите with open и read() се използват за отваряне и четене на съдържанието на файла с име sample. Примерният файл съдържа съдържанието на файла file.txt; за да научите как да коригирате грешка при анализиране, файлът трябва да бъде прочетен напълно.
- Съдържанието на файла се отпечатва, за да се анализират данните ръчно, за да се открият метаданните на стойностите. Тук функцията print() се използва за отпечатване на съдържанието на примерния файл.
- Необходимите пакети данни за анализиране на текста се импортират в кода и се дава име на класа за по-нататъшно кодиране. Тук се импортират регулярните изрази и пандите.
- Регулярните изрази, необходими за кода, са дефинирани във файла чрез включване на модела на регулярен израз и функцията на регулярен израз. Това позволява на текстовия обект или корпус да вземе кода за анализ на данни.
- За да знаете как да анализирате текст, можете да се обърнете към примерния код, даден тук. Функцията compile() се използва за компилиране на низа от групата stringname1 на файла filename. Функцията за проверка за съвпадения в регулярния израз се използва от командата ief_parse_line(line),
- Анализаторът на редове за кода е написан с помощта на def_parse_file(filepath), в който дефинираната функция проверява за всички съвпадения на регулярен израз в посочената функция. Тук методът regex search() търси ключа rx в името на файла и връща ключа и съвпадението на първия съответстващ регулярен израз. Всеки проблем със стъпката може да доведе до грешка в анализа на текст x.
- Следващата стъпка е да напишете File Parser, като използвате функцията file parser, която е def_parse_file(filepath). Създава се празен списък за събиране на данните от кода, като data = []съвпадението се проверява на всеки ред чрез match = _parse_line(line) и данните за точната стойност се връщат въз основа на типа данни.
- За извличане на числото и стойността за таблицата се използва командния ред.strip().split(‘,’). Командата row{} се използва за създаване на речник с реда от данни. Командата data.append(row) се използва за разбиране на данните и анализирането им в табличен формат.
Командата data = pd.DataFrame(data) се използва за създаване на pandas DataFrame от dict стойностите. Като алтернатива можете да използвате следните команди за съответната цел, както е посочено по-долу.
-
data.set_index([‘string’, ‘integer’]inplace=True), за да зададете индекса на таблицата.
-
data = data.groupby(level=data.index.names).first() за консолидиране и премахване на nans.
-
data = data.apply(pd.to_numeric, errors=’ignore’) за надграждане на резултата от float до целочислена стойност.
Последната стъпка, за да разберете как да анализирате текст, е да тествате анализатора с помощта на израза if, като присвоите стойностите на променливи данни и ги отпечатате с помощта на командата print(data).
Примерният код за обяснението по-горе е даден тук.
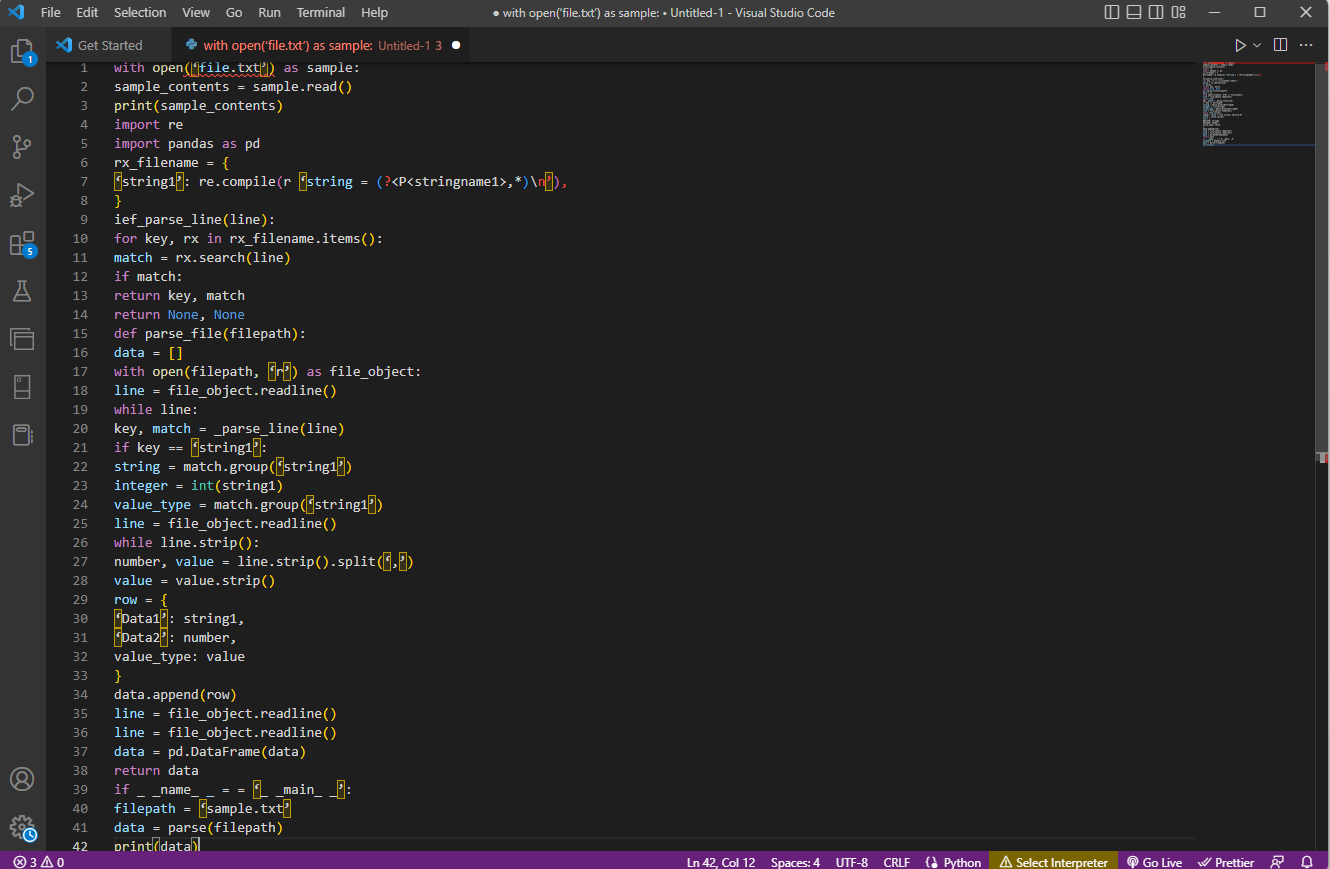
with open(‘file.txt’) as sample:
sample_contents = sample.read()
print(sample_contents)
import re
import pandas as pd
rx_filename = {
‘string1’: re.compile(r ‘string = (?<P<stringname1>,*)n’),
}
ief_parse_line(line):
for key, rx in rx_filename.items():
match = rx.search(line)
if match:
return key, match
return None, None
def parse_file(filepath):
data = []
with open(filepath, ‘r’) as file_object:
line = file_object.readline()
while line:
key, match = _parse_line(line)
if key == ‘string1’:
string = match.group(‘string1’)
integer = int(string1)
value_type = match.group(‘string1’)
line = file_object.readline()
while line.strip():
number, value = line.strip().split(‘,’)
value = value.strip()
row = {
‘Data1’: string1,
‘Data2’: number,
value_type: value
}
data.append(row)
line = file_object.readline()
line = file_object.readline()
data = pd.DataFrame(data)
return data
if _ _name_ _ = = ‘_ _main_ _’:
filepath = ‘sample.txt’
data = parse(filepath)
print(data)
Метод 2: Чрез токенизиране на думи
Процесът на преобразуване на текст или корпус в токени или по-малки части въз основа на определени правила се нарича токенизация. За да научите как да коригирате грешка при анализиране, е важно да анализирате командите за токенизиране на думи в кода. Подобно на регулярния израз, в този метод могат да се създават собствени правила и той помага при задачи за предварителна обработка на текст, като картографиране на части от речта. Освен това в този метод се извършват дейности като намиране и съпоставяне на общи думи, почистване на текст и подготовка на данните за усъвършенствани техники за анализ на текст като анализ на настроението. Ако токенизацията е неправилна, може да възникне грешка в текста за анализ x.
Ntlk библиотека
Процесът използва помощта на популярната библиотека с езикови инструменти, наречена nltk, която има богат набор от функции за изпълнение на много NLP задачи. Те могат да бъдат изтеглени чрез пакетите Pip или Pip Installs. За да знаете как да анализирате текст, можете да използвате основния пакет на дистрибуцията на Anaconda, който включва библиотеката по подразбиране.
Форми на токенизация
Често срещаните форми на този метод са токенизиране на думи и токенизиране на изречения. Благодарение на токена на ниво дума, първият отпечатва една дума само веднъж, докато вторият отпечатва думата на ниво изречение.
Процес на анализиране на текст
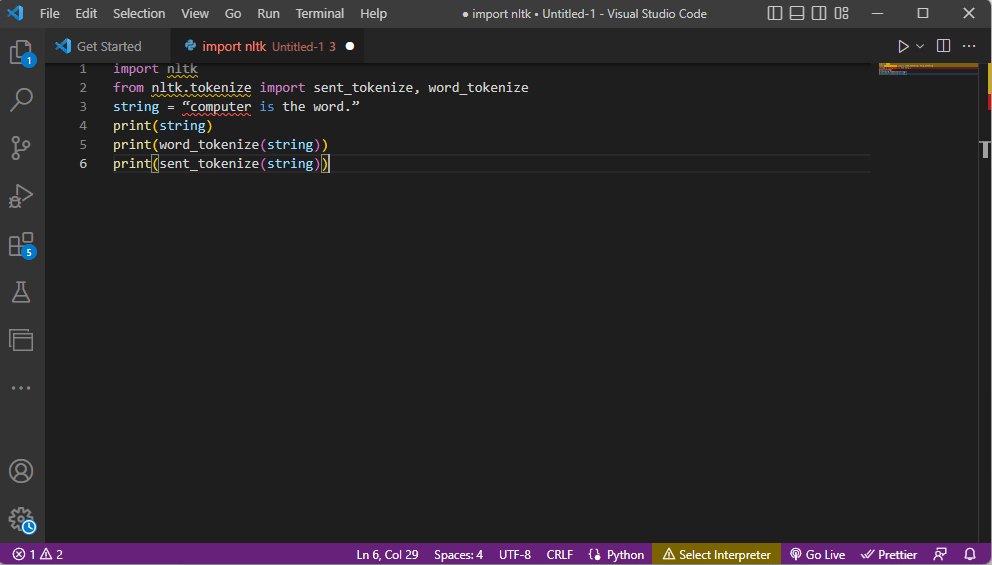
- Библиотеката с инструменти ntlk се импортира и формулярите за токенизиране се импортират от библиотеката.
- Даден е низ и са дадени командите за извършване на токенизацията.
- Докато низът се отпечатва, изходът ще бъде компютърът е думата.
- В случай на токенизиране на думи или word_tokenize(), всяка дума в изречението се отпечатва индивидуално в рамките на “ и се разделя със запетая. Резултатът за командата ще бъде „компютър“, „е“, „на“, „дума“, „.“
- В случай на токенизиране на изречение или sent_tokenize(), отделните изречения се поставят в “ и е разрешено повторение на думата. Изходът за командата ще бъде „компютърът е думата“.
Кодът, обясняващ стъпките за токенизиране по-горе, е даден тук.
import nltk from nltk.tokenize import sent_tokenize, word_tokenize string = “computer is the word.” print(string) print(word_tokenize(string)) print(sent_tokenize(string))
Метод 3: Чрез клас DocParser
Подобно на класа DataFrame, класът DocParser може да се използва за анализиране на текста в кода. Класът ви позволява да извикате функцията за разбор с пътя на файла.
Процес на анализиране на текст
За да знаете как да анализирате текст с помощта на класа DocParser, следвайте инструкциите, дадени по-долу.
- Функцията get_format(filename) се използва за извличане на файловото разширение, връщането му към зададена променлива за функцията и предаването му на следващата функция. Например, p1 = get_format(filename) ще извлече файловото разширение на filename, ще го зададе на променливата p1 и ще го предаде на следващата функция.
- Логическа структура с други функции се конструира с помощта на изразите и функциите if-elif-else.
- Ако файловото разширение е валидно и структурата е логична, функцията get_parser се използва за анализиране на данните в пътя на файла и връщане на низовия обект на потребителя.
Забележка: За да знаете как да поправите грешка при анализиране, тази функция трябва да бъде внедрена правилно.
- Анализът на стойностите на данните се извършва с файловото разширение на файла. Конкретната реализация на класа, която е parse_txt или parse_docx, се използва за генериране на низови обекти от частите на дадения тип файл.
- Анализът може да се извърши за файлове с други четливи разширения като parse_pdf, parse_html и parse_pptx.
- Стойностите на данните и интерфейсът могат да бъдат импортирани в приложения с изрази за импортиране и създаване на обект на DocParser. Това може да стане чрез анализиране на файлове на езика Python, като parse_file.py. Тази операция трябва да се извърши внимателно, за да се избегне грешка при разбор на текст x.
Метод 4: Чрез инструмента за анализ на текст
Текстовият инструмент Parse се използва за извличане на конкретни данни от променливи и картографирането им към други променливи. Това е независимо от всички други инструменти, използвани в дадена задача, а инструментът BPA Platform се използва за консумиране и извеждане на променливи. Използвайте връзката, дадена тук, за достъп до Инструмент за разбор на текст онлайн и използвайте дадените по-рано отговори за това как да анализирате текст.
Метод 5: Чрез TextFieldParser (Visual Basic)
TextFieldParser използва обекти за анализиране и обработка на много големи файлове, които са структурирани и ограничени. Ширината и колоната с текст, като например регистрационни файлове или информация от наследена база данни, могат да се използват в този метод. Методът за анализиране е подобен на повторение на кода върху текстов файл и се използва главно за извличане на полета от текст, подобно на методите за манипулиране на низове. Това се прави, за да се токенизират разделени низове и полета с различни ширини, като се използва дефинираният разделител, като например запетая или табулация.
Функции за разбор на текст
Следните функции могат да се използват за анализиране на текста в този метод.
- За дефиниране на разделител се използва SetDelimiters. Например, командата testReader.SetDelimiters (vbTab) се използва за задаване на разделител като разделител.
- За да зададете ширина на полето на положително цяло число към фиксирана ширина на полето на текстови файлове, можете да използвате командата testReader.SetFieldWidths (цяло число).
- За да тествате типа поле на текста, можете да използвате следната команда testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth.
Методи за намиране на MatchObject
Има два основни метода за намиране на MatchObject в кода или анализирания текст.
- Първият метод е да дефинирате формата и да преминете през файла с помощта на метода ReadFields. Този метод ще помогне при обработката на всеки ред от кода.
- Методът PeekChars се използва за проверка на всяко поле поотделно, преди да го прочете, да дефинира множество формати и да реагира.
И в двата случая, ако дадено поле не съответства на посочения формат, докато се извършва синтактичен анализ или се намира как да се анализира текст, се връща изключение MalformedLineException.
Професионален съвет: Как да анализирате текст чрез MS Excel
Като последен и прост метод за анализ на текста можете да използвате MS Excel приложение като анализатор за създаване на файлове, разделени с разделители и запетая. Това би помогнало при кръстосаната проверка с вашия анализиран резултат и би помогнало да намерите как да поправите грешката при анализа.
1. Изберете стойностите на данните в изходния файл и натиснете едновременно клавишите Ctrl + C, за да копирате файла.
2. Отворете приложението Excel, като използвате лентата за търсене на Windows.
3. Щракнете върху клетката A1 и натиснете едновременно клавишите Ctrl + V, за да поставите копирания текст.
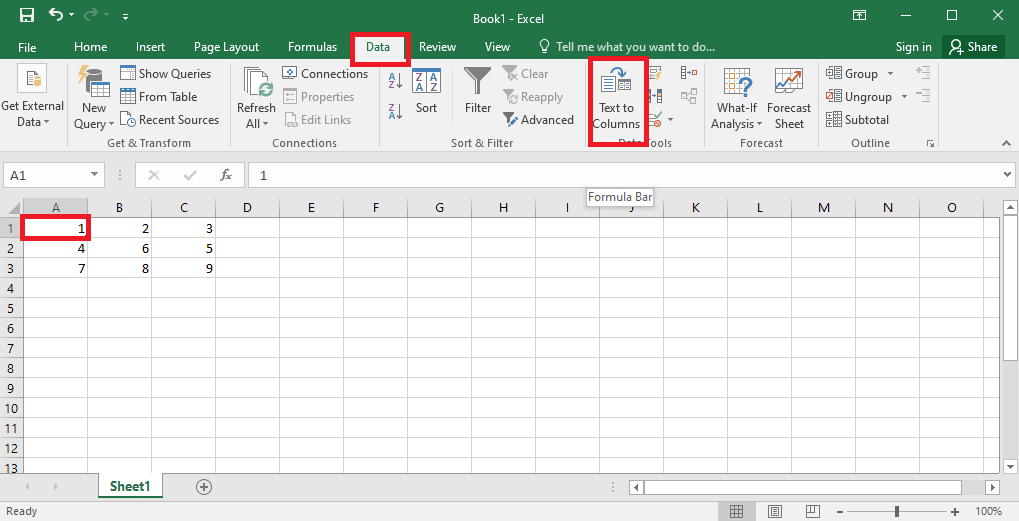
4. Изберете клетката A1, отидете до раздела Данни и щракнете върху опцията Текст към колони в секцията Инструменти за данни.
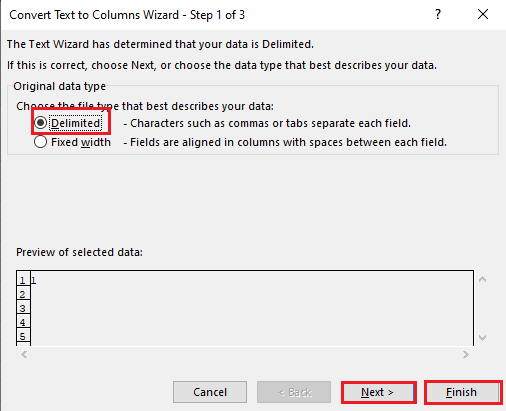
5А. Изберете опцията с разделители, ако като разделител се използва запетая или табулация, и щракнете върху бутоните Напред и Край.
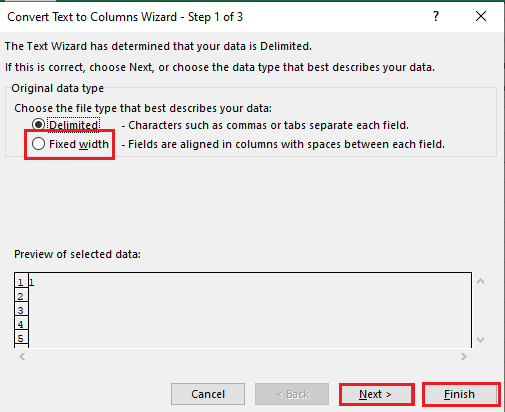
5B. Изберете опцията Фиксирана ширина, задайте стойност за разделителя и щракнете върху бутоните Напред и Край.
Как да коригирате грешка при анализиране
Грешка при синтактичния анализ на текст x може да възникне на устройства с Android като Грешка при синтактичния анализ: Възникна проблем при синтактичния анализ на пакета. Това обикновено се случва, когато приложението не успее да се инсталира от Google Play Store или докато работи с приложение на трета страна.
Текстът за грешка x може да възникне, ако списъкът със символни вектори е цикличен и други функции формират линеен модел за изчисляване на стойностите на данните. Съобщението за грешка е Error in parse(text = x, keep.source = FALSE):
Можете да прочетете статията за това как да коригирате грешка при анализиране на Android, за да научите причините и методите за коригиране на грешката.
Освен решенията в ръководството, можете да опитате следните корекции.
- Повторно изтегляне на .apk файла или възстановяване на името на файла.
- Възстановяване на промените във файла Androidmanifest.xml, ако имате умения за програмиране на експертно ниво.
***
Статията помага в обучението как да анализирате текст и да научите как да поправяте грешка при анализа. Уведомете ни кой метод е помогнал за коригирането на грешката в синтаксиса на текст x и кой метод на анализ е предпочитан. Моля, споделете вашите предложения и запитвания в секцията за коментари по-долу.