

Amazon Glue набира популярност, тъй като много компании започнаха да използват управлявани услуги за интегриране на данни.
ETL е процес, който прехвърля данни от изходна база данни към хранилище за данни. ETL е сложен и труден за прилагане за всички корпоративни данни поради своята сложност. Amazon представи AWS Glue, за да се справи с този проблем.
ETL разработчиците и инженерите на данни използват Glue за изграждане, наблюдение и изпълнение на ETL работни потоци.
Съдържание
Какво е AWS лепило?
AWS Glue, услуга за интегриране на данни без сървър, улеснява намирането, подготовката, преместването и интегрирането на данни от множество източници. Това е полезно за машинно обучение (ML) и анализи.
Това драстично намалява времето, необходимо за подготовка на данните за анализ. Той автоматично намира и изброява данните, генерира Scala или Python код за предаване на данните от източника и зарежда и преобразува заданието според времевите събития.
Това позволява гъвкаво планиране и създава среда на Apache Spark, която може да бъде мащабирана за целево зареждане на данни. Освен това AWS Glue осигурява комплексно наблюдение и промяна на потока от данни. AWS Glue е услуга без сървър, която опростява сложните операции на разработката на приложения.
Той позволява бързо интегриране на множество валидни данни. Освен това бързо разгражда и разрешава данните.
За какво се използва AWS Glue?
Важно е да знаете най-добрите места за използване на Amazon Glue. Това са само няколко примера за употреби на AWS Glue, които трябва да имате предвид.
- Glue е инструмент, който ви позволява да изпълнявате заявки без сървър в езерата с данни на Amazon S3. Amazon Glue е страхотен инструмент, за да започнете. Той прави всички ваши данни достъпни в един интерфейс, което ви позволява да ги анализирате, без да се налага да ги премествате.
- Amazon Glue може да се използва за разбиране на вашите активи с данни. Amazon Glue ви улеснява да търсите различни набори от данни на AWS с помощта на каталога с данни. Можете също така да запазвате данни в множество AWS услуги, като използвате каталога с данни, като същевременно имате последователен изглед.
- Glue може да бъде полезен при изграждане на ETL работни потоци, управлявани от събития. Можете да изпълнявате вашите ETL операции от Amazon S3, като извиквате вашите Glue ETL задачи чрез AWS Lambda услуга.
- AWS Glue може също да се използва за почистване, проверка, форматиране и организиране на данни за съхранение в езеро с данни или склад.
Какви са компонентите на AWS лепилото?
По-долу са основните компоненти на AWS Glue:
- Каталог с данни: Този каталог с данни съдържа метаданни и структурата на данните.
- База данни: Това е ключът към достъпа и създаването на базата данни за източници и цели.
- Таблица: Създайте една или няколко таблици в базата данни, които могат да се използват както от целта, така и от източника.
- Робот и класификатор: Роботът извлича данни от източника чрез използване на вградени или персонализирани класификации. Той създава/използва предварително дефинирани таблици с метаданни в каталога с данни.
- Работа: Това е работата на бизнес логиката за изпълнение на ETL задача. Тази бизнес логика е написана вътрешно от Apache Spark с помощта на езици Python и Scala.
- Тригер: ETL тригерът е устройство, което инициира изпълнението на ETL задание при поискване или в определен момент.
- Крайна точка за разработка: Това създава среда, в която скриптът за работа на ETL се тества, разработва и отстранява грешки.
Предимства на лепилото AWS
Това са ползите от използването му на вашето работно място или в организация.
- AWS Glue сканира всички налични данни с робот.
- Окончателно обработените данни могат да се съхраняват на много места (Amazon RDS и Amazon Redshift, Amazon S3 и др.
- Това е облачна услуга. Няма нужда да харчите пари за локални инфраструктури.
- Тъй като това е ETL без сървър, това е рентабилен избор.
- Бързо е. Веднага ви дава Python/Scala ETL кода.
Основни характеристики на AWS Glue?
Amazon Glue разполага с всички функции, от които се нуждаете, за да интегрирате данни, за да можете да получите по-добри прозрения и да използвате знанията си, за да постигнете нов напредък за минути вместо за месеци. Ето някои от функциите, които трябва да знаете.
- Интерфейс с плъзгане и пускане: Редакторът на работа с плъзгане и пускане ви позволява да създадете ETL процес. AWS Glue незабавно ще изгради кода, необходим за извличане, конвертиране и качване на данните.
- Автоматично откриване на схема: За да създадете роботи, които се свързват с различни източници на данни, можете да използвате услугата Glue. Той организира данни и извлича подходяща информация. След това тези данни могат да се използват за наблюдение на ETL процеси от ETL задачи.
- График на работата: Лепилото може да се използва при поискване или според планиран график. Планировчикът може да се използва за изграждане на сложни ETL конвейери, установявайки зависимости между задачите.
- Генериране на код: Glue Elastic Views ви позволява лесно да създавате материализирани изгледи, които комбинират и репликират данни от различни източници на данни, без да се налага да пишете собствен код.
- Вградено машинно обучение: Glue идва с вградена функция за машинно обучение, наречена „FindMatches“. Той дедупликира записи, които не са перфектни копия един на друг.
- Крайни точки за разработчици: Ако искате активно да разработвате вашия ETL код, Glue предоставя крайни точки за разработчици, които ви позволяват да модифицирате, отстранявате грешки и тествате кода, който създава.
- Glue DataBrew: Това е инструмент за подготовка на данни, който може да се използва от анализатори на данни и специалисти по данни, за да им помогне да изчистят и нормализират данните. Той използва активния и визуален интерфейс на Glue DataBrew.
Как работи AWS Glue Pricing?
AWS Glue начислява почасова такса, която се таксува на секунда за роботи (откриване на данните) и ETL задачи (обработка и зареждане на данните). За достъп и съхранение на метаданни в AWS Glue Data Catalog се начислява проста месечна такса.
Amazon Glue започва от $0,44. Можете да избирате от четири плана:
- ETL задачи, крайни точки за разработка и други ETL задачи се предлагат на $0,44
- Интерактивните сесии на Crawlers се предлагат на $0,44
- Задачите на DataBrew започват от $0,48
- Месечното съхранение и заявките към каталога с данни струват $1,00
AWS не предлага безплатен Glue план. Всеки час ще струва $0,44 на DPU. Средно ще ви струва $21 на ден. Цените могат да варират в зависимост от това къде живеете.
Стъпки за настройка на AWS лепило
Каталогът с данни може да се използва за бързо намиране и търсене на множество AWS набори от данни, без да се налага да премествате данните. След като данните бъдат каталогизирани, те са незабавно достъпни за заявка и търсене с помощта на Amazon Athena и Amazon EMR.
Справка: https://aws.amazon.com/glue/
- Amazon Redshift, Amazon S3, Amazon RDS и бази данни на Amazon EC2 – Открийте вашите данни, съхранявайте метаданни и използвайте AWS Glue Data Catalog, за да ги откриете
- AWS Glue Data Catalog – Управлявайте данни с каталога с данни, действащ като централно хранилище за метаданни
- AWS Glue ETL – Четете и записвайте метаданни във вашия каталог с данни
- Amazon Athena и Amazon Redshift, Amazon EMR, Amazon ETL – Вземете каталога с данни за ETL, анализи и др.
Как да настроя AWS лепило?
Първо, влезте в конзолата за управление на AWS и отворете конзолата IAM. Кликнете върху Създаване на роля. След това за тип роля намерете Glue и изберете Permissions.
Избирам AWSGlueServiceRole за общи разрешения на AWS Glue Studio и AWS Glue и управляваната от AWS политика AmazonS3FullAccess за достъп до ресурси на Amazon S3.
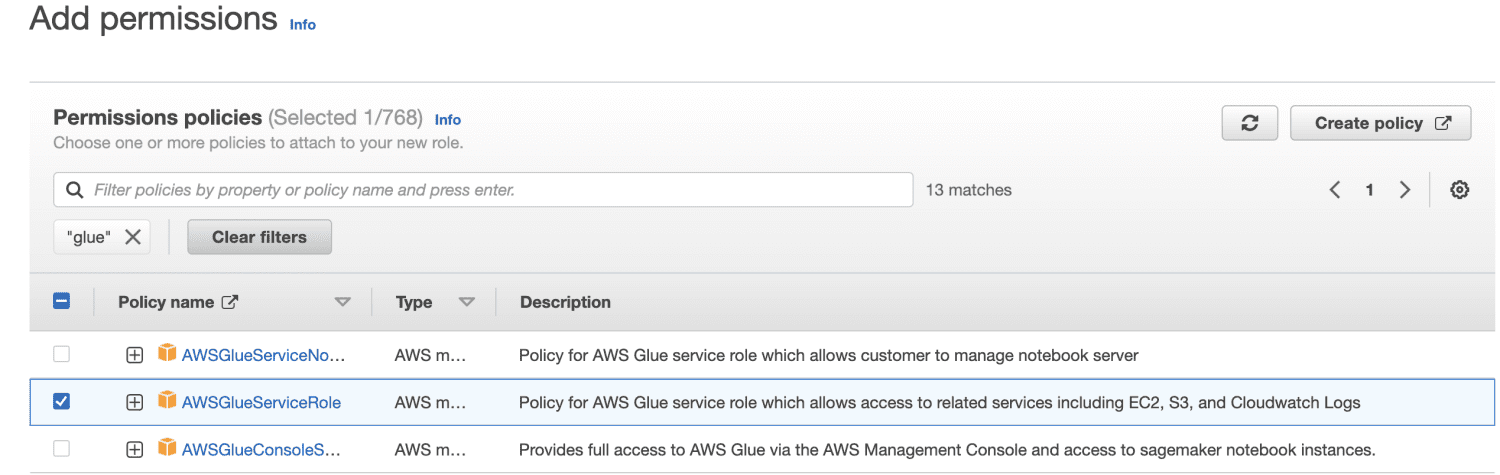
Въведете име на роля.
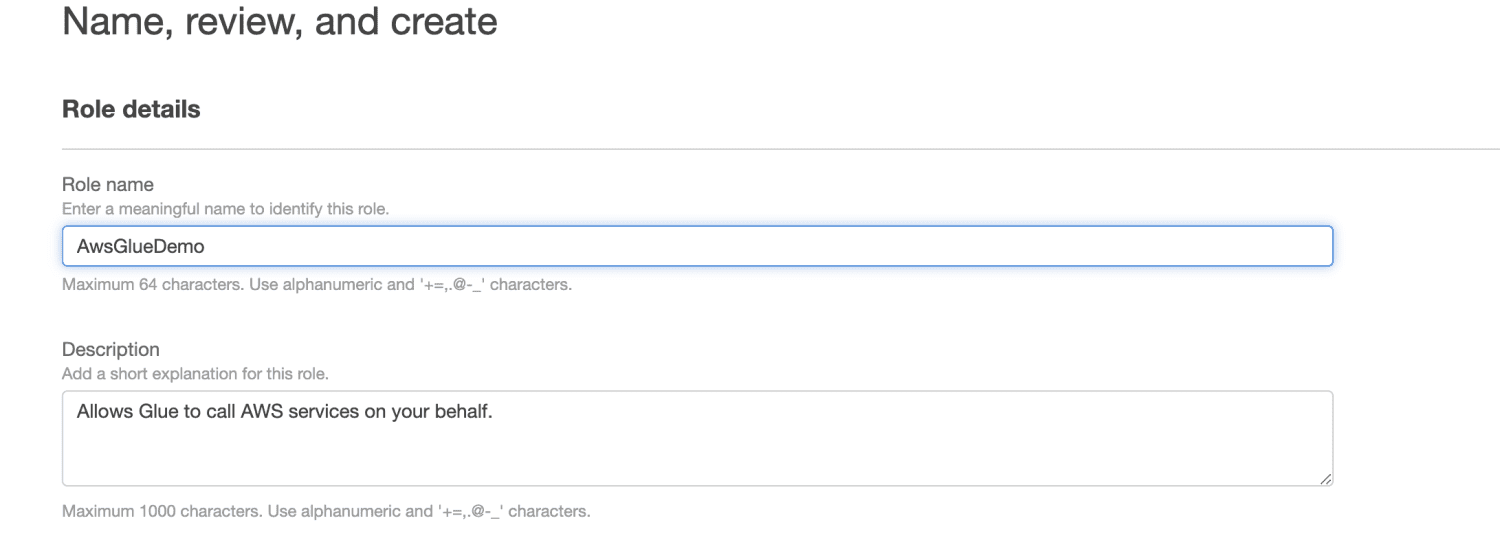
Кликнете върху Създаване на роля.
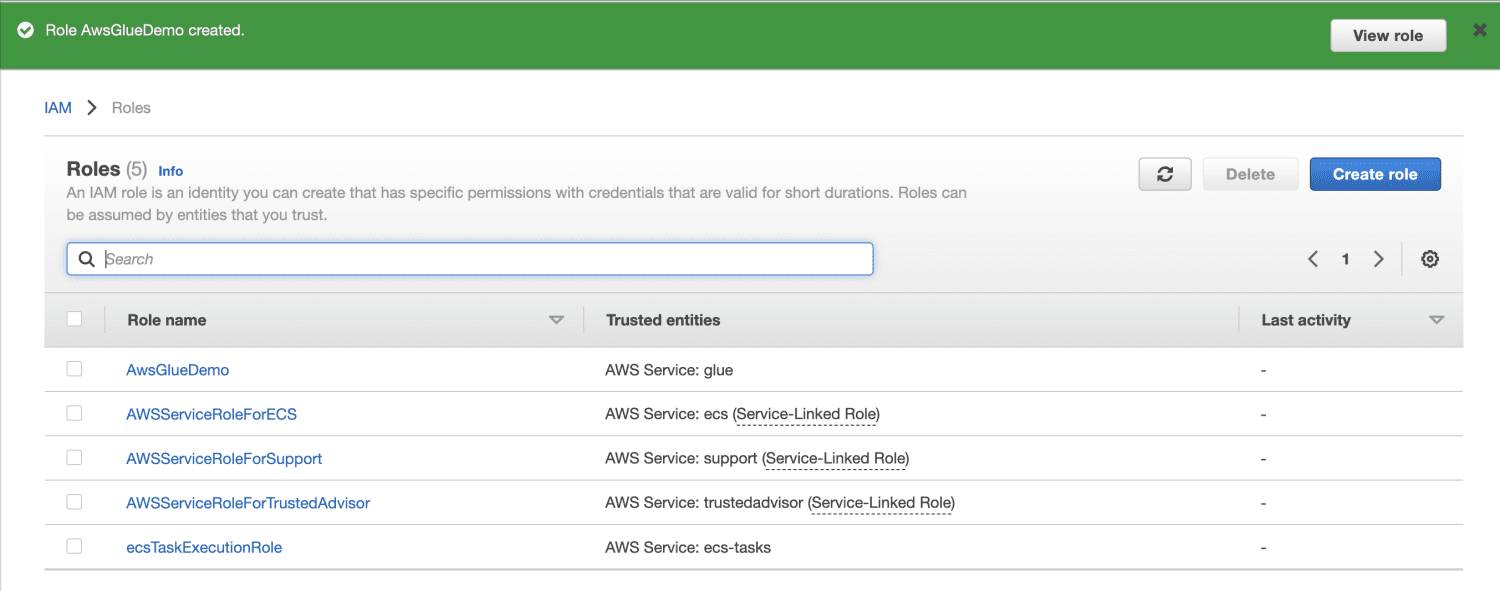
Създайте кофа на Amazon S3.
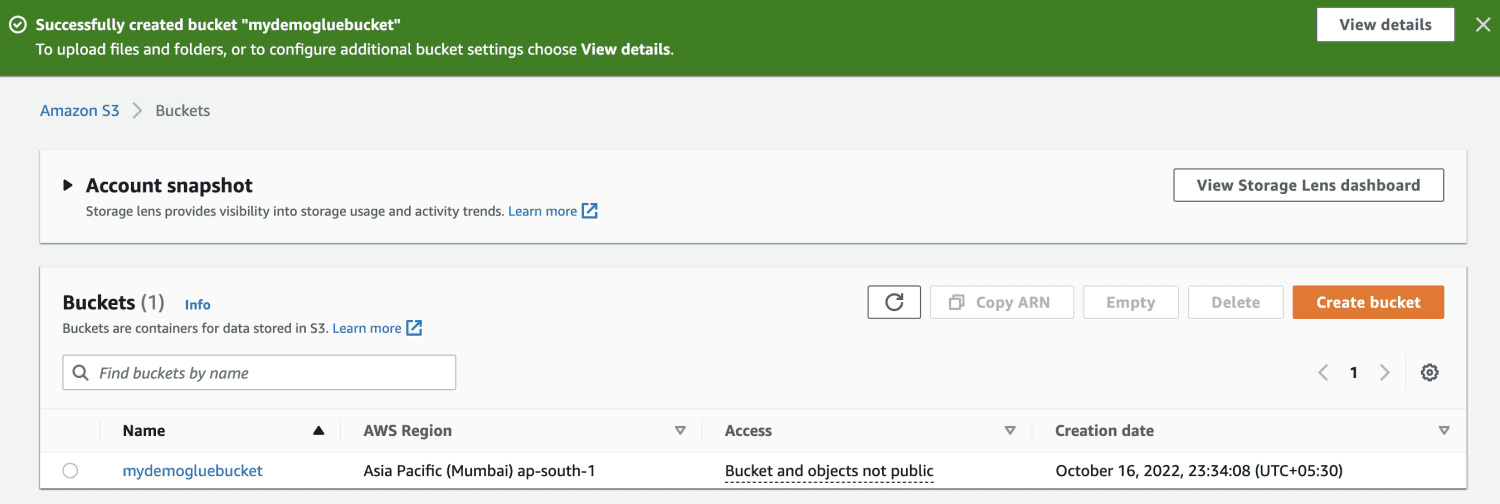
Създайте папка в кофата S3.
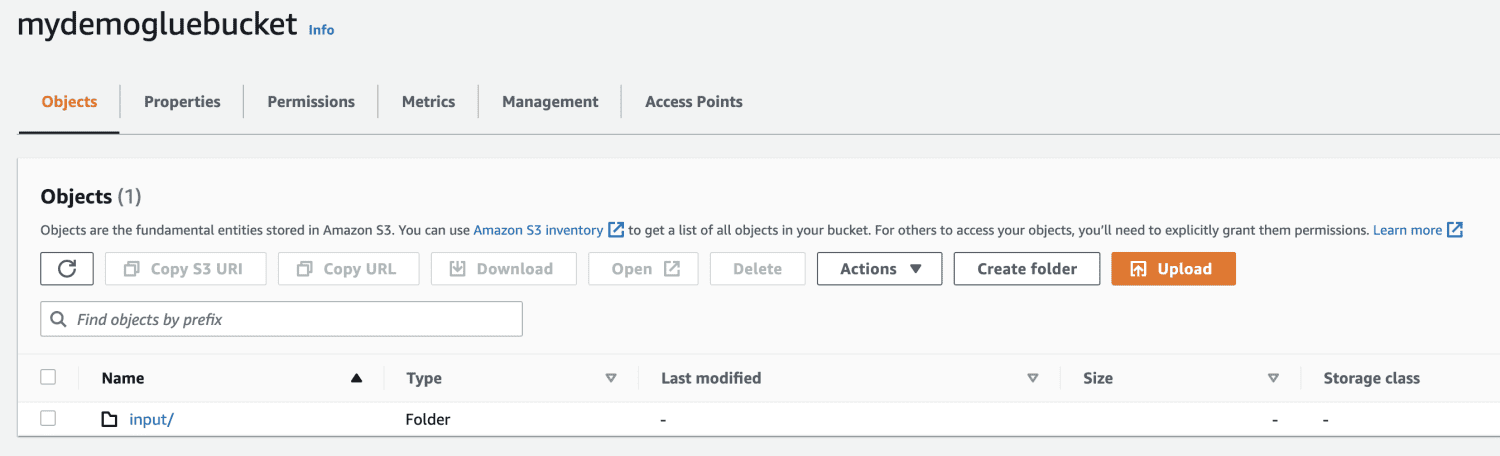
Изберете файла за качване.
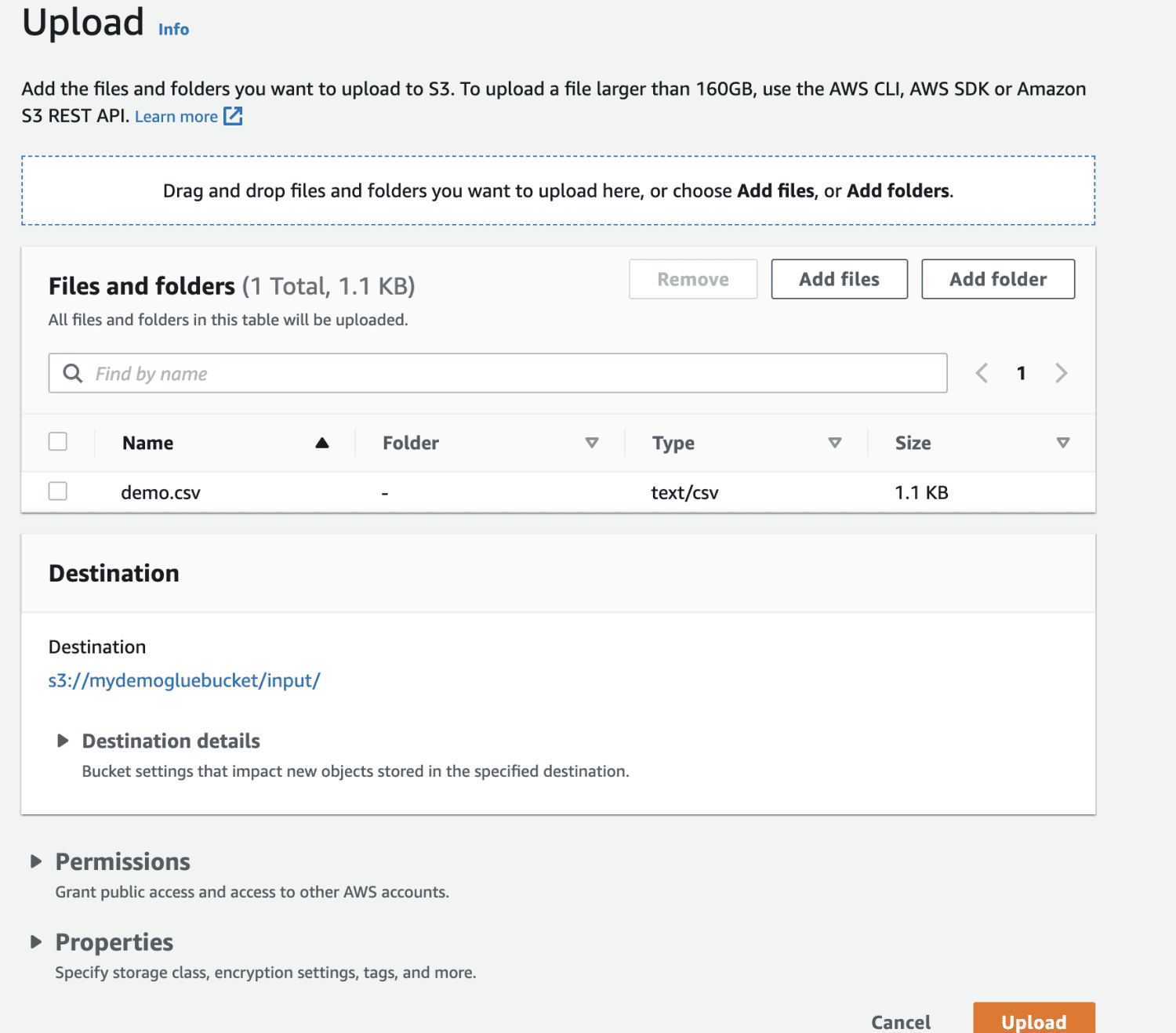
Накрая качете файла в кофата.
След това отворете AWS Glue от конзолата за управление на AWS и създайте база данни.
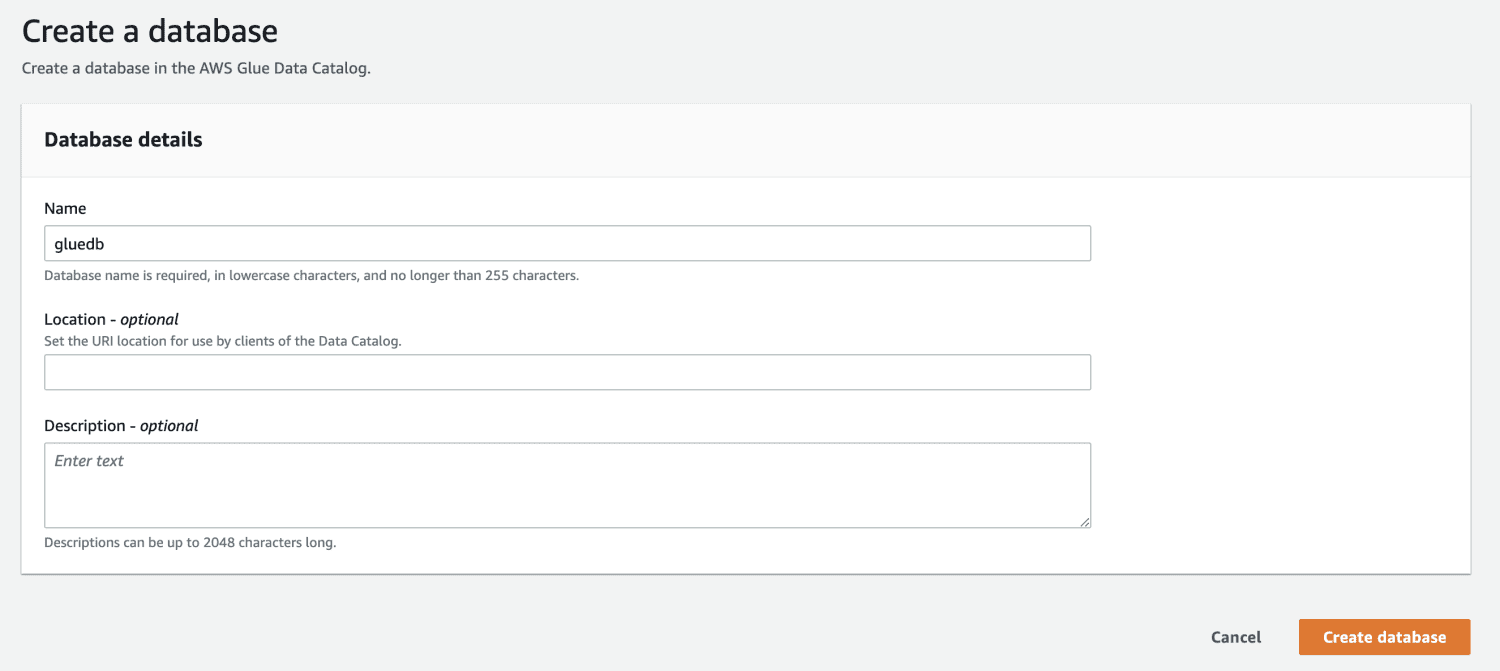
Сега, когато имате база данни в AWS Glue, създайте робот.
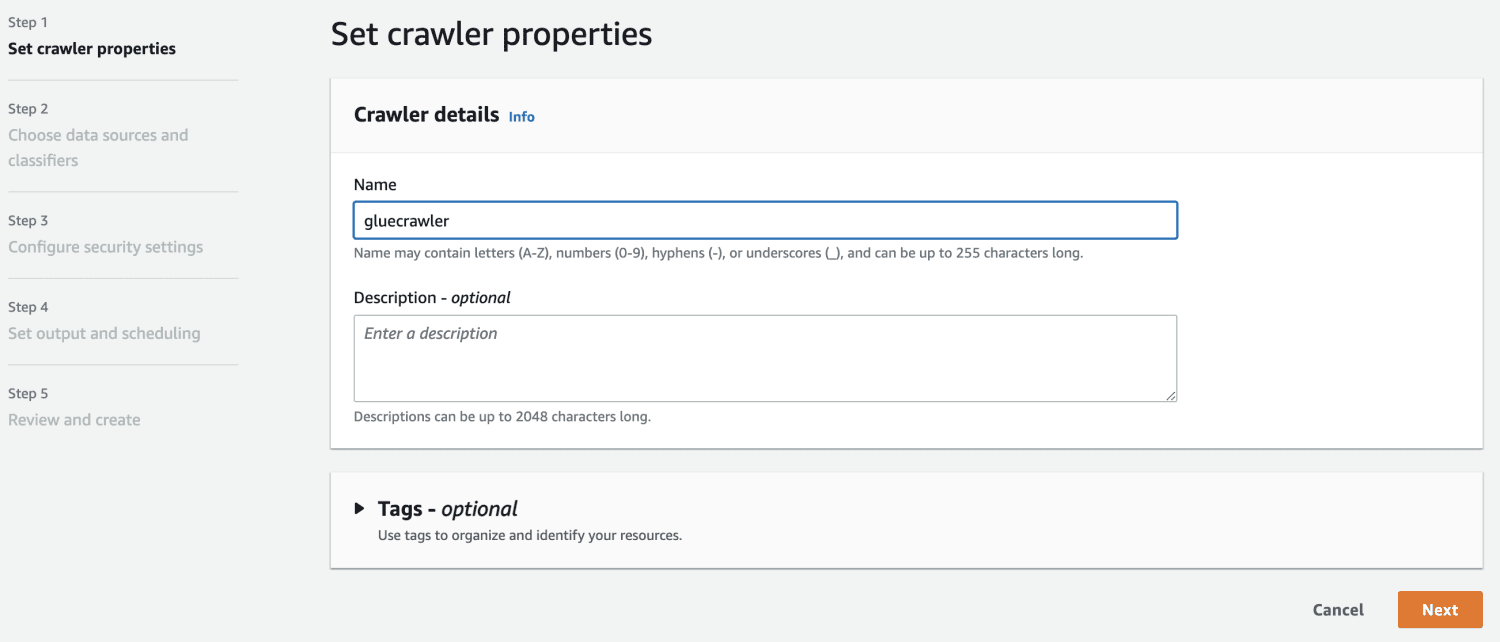
В източника на данни изберете кофата S3, която сте създали.
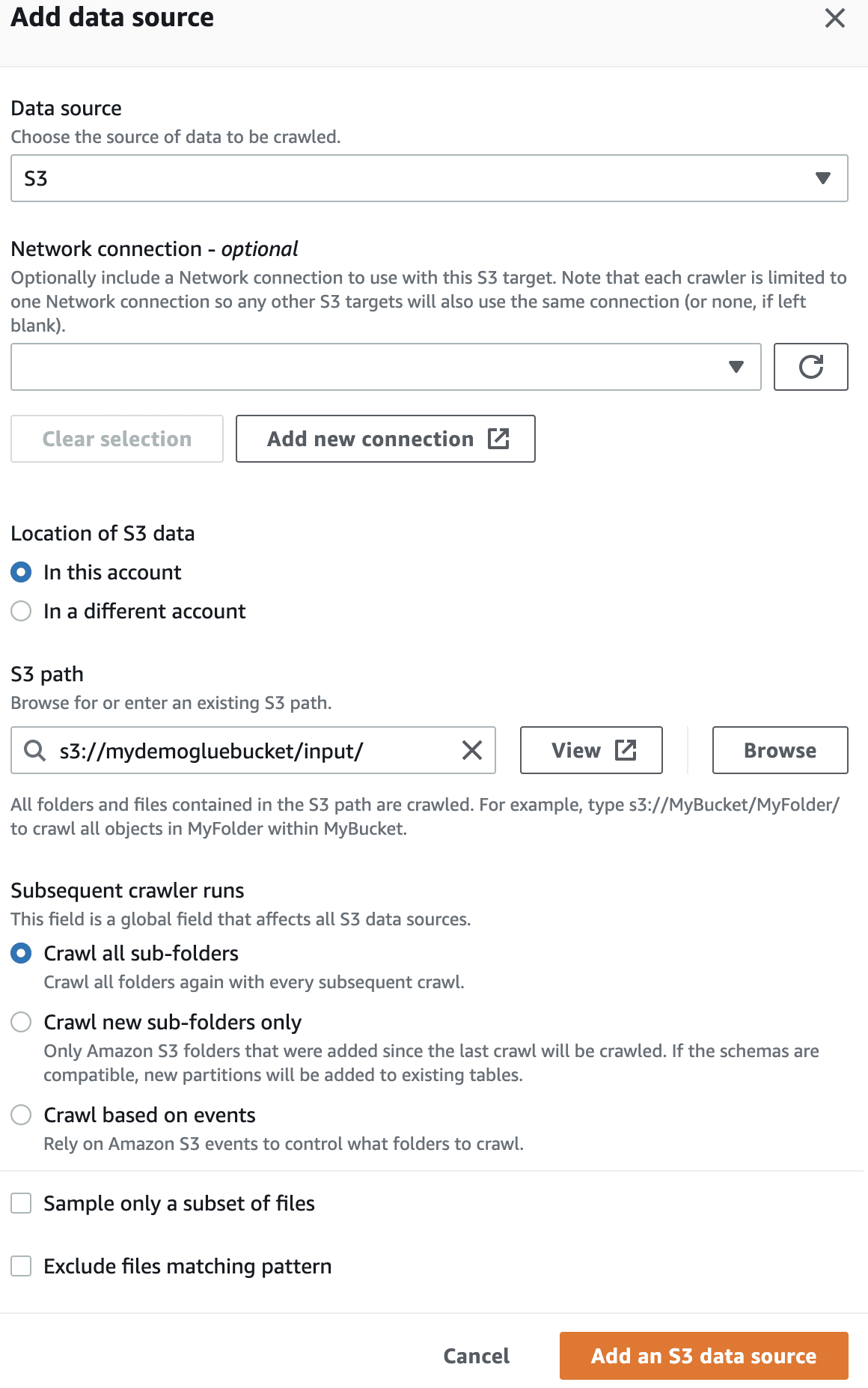
След това изберете IaM ролята за AWS Glue, която създадохте в началото.
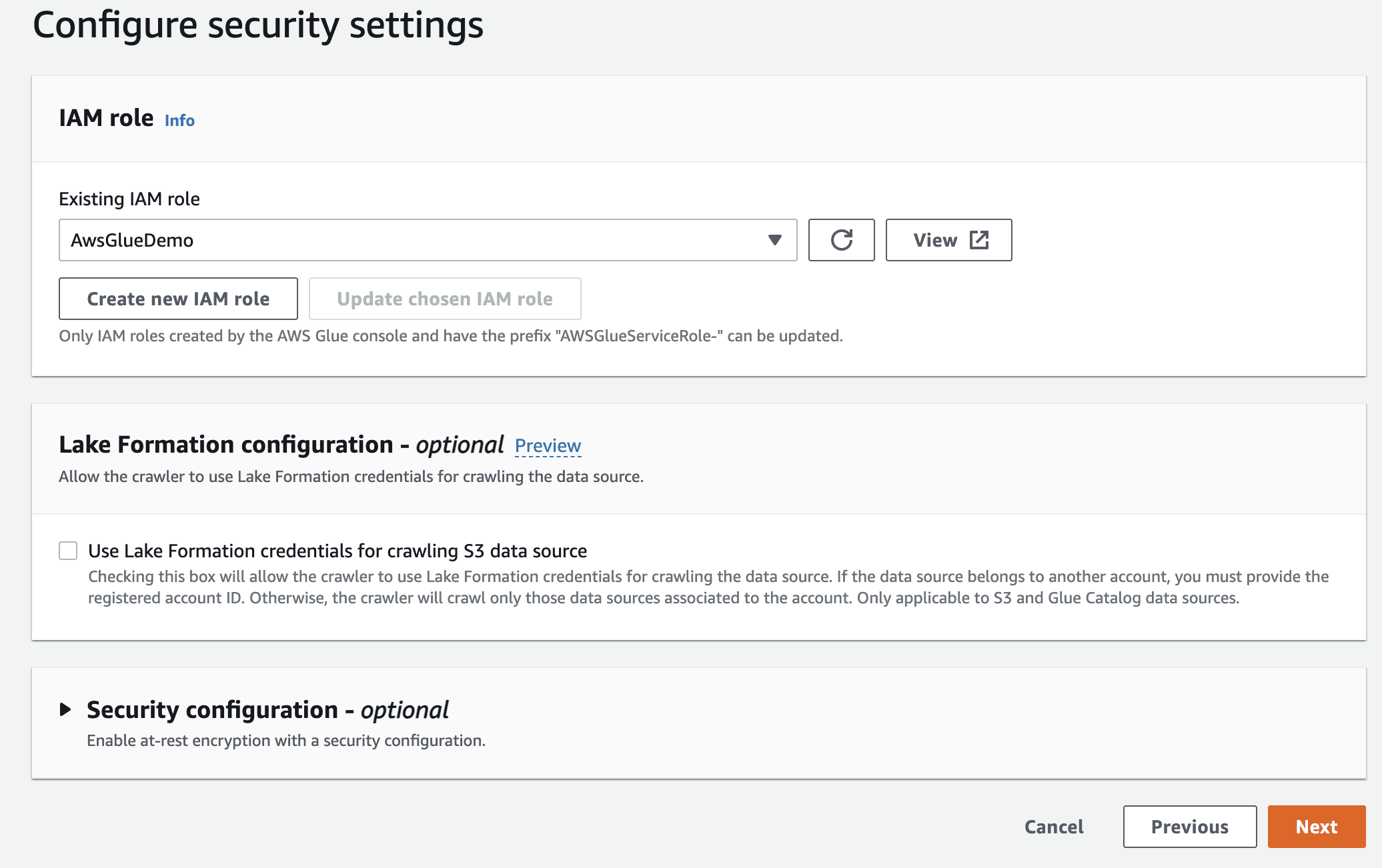
Накрая в изхода изберете gluedb, който сте създали.
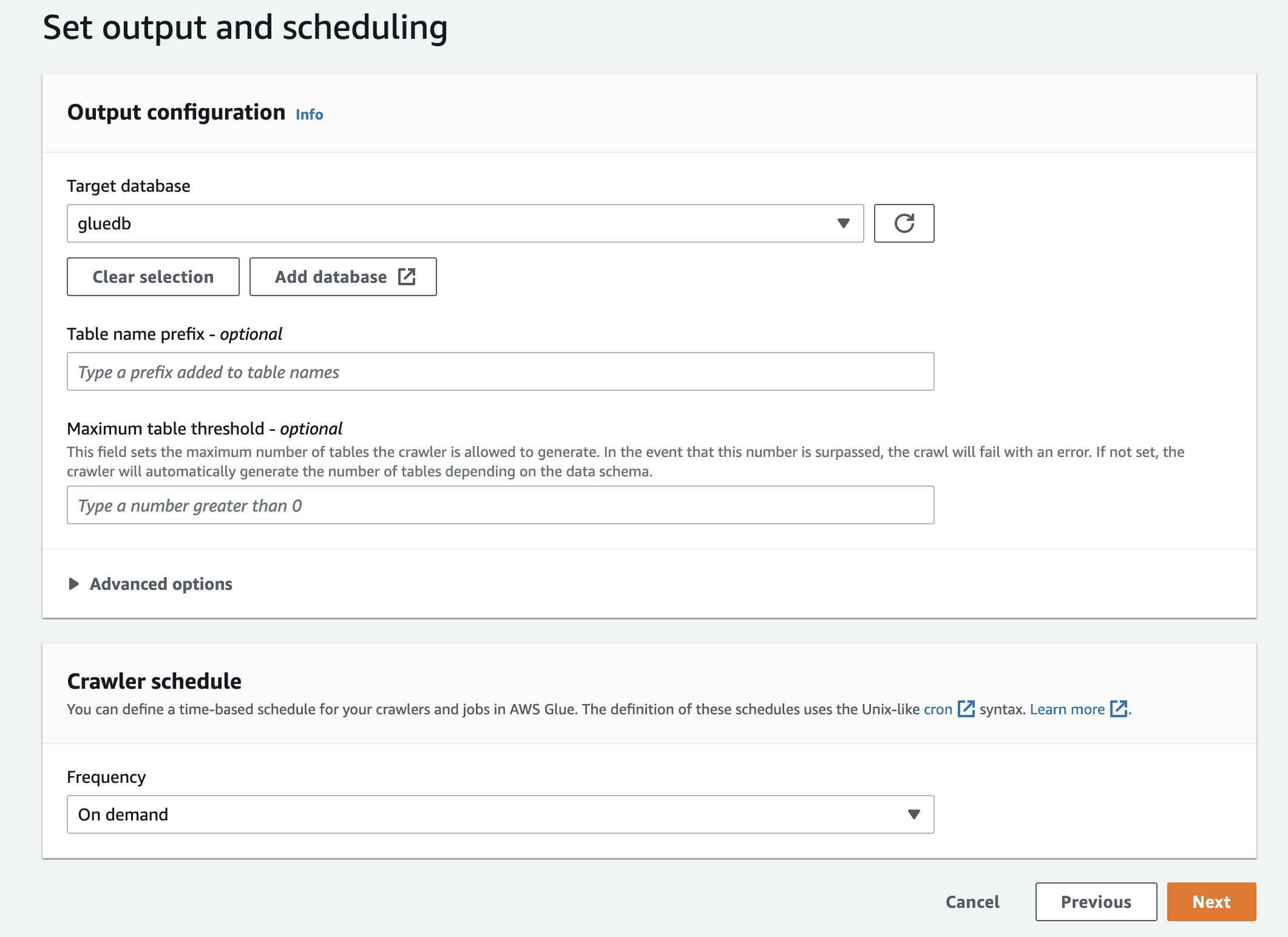
Прегледайте всички настройки и създайте робота.
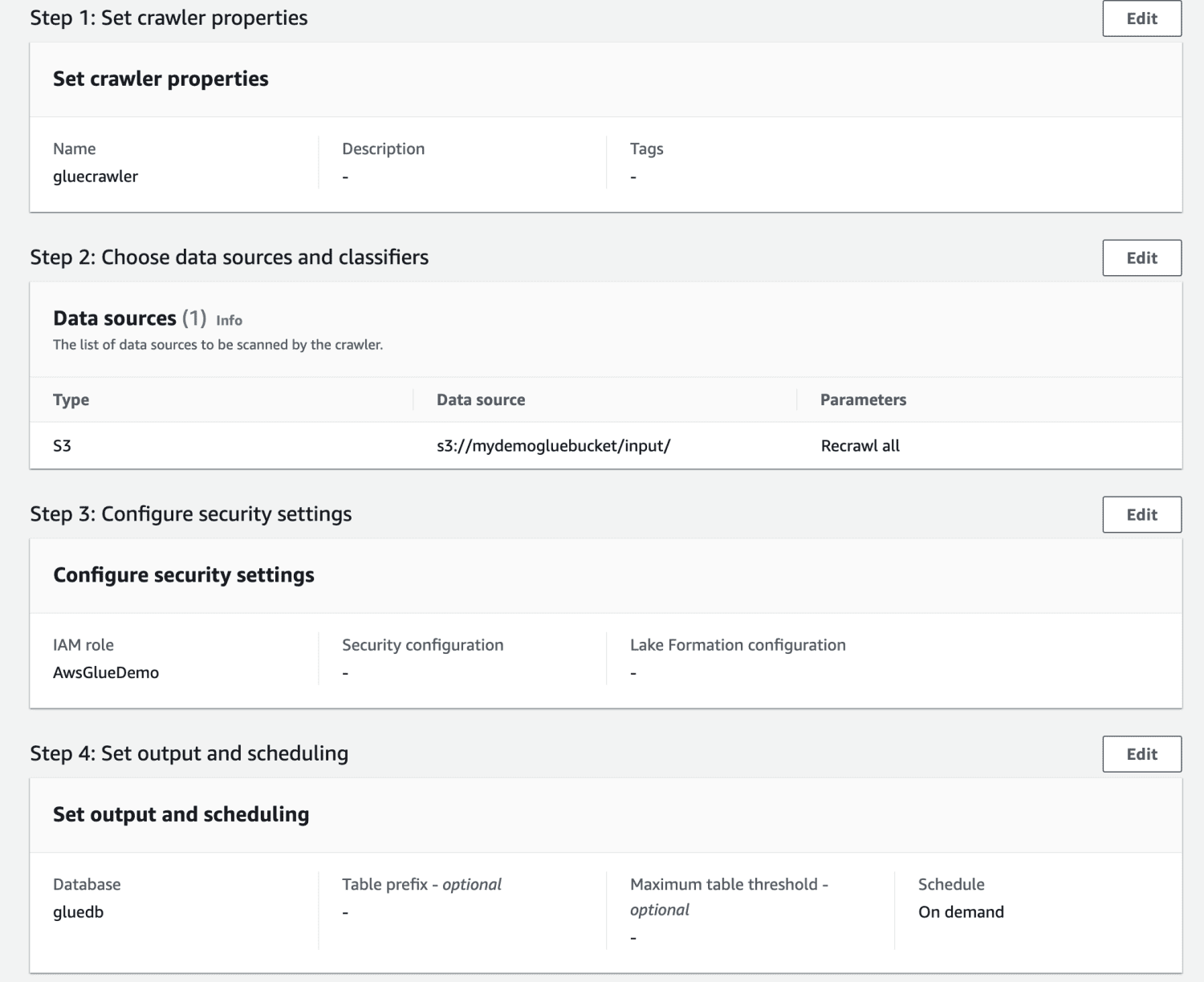
След като роботът бъде създаден, изберете го и щракнете върху Изпълнение. След известно време ще получите готов статус.
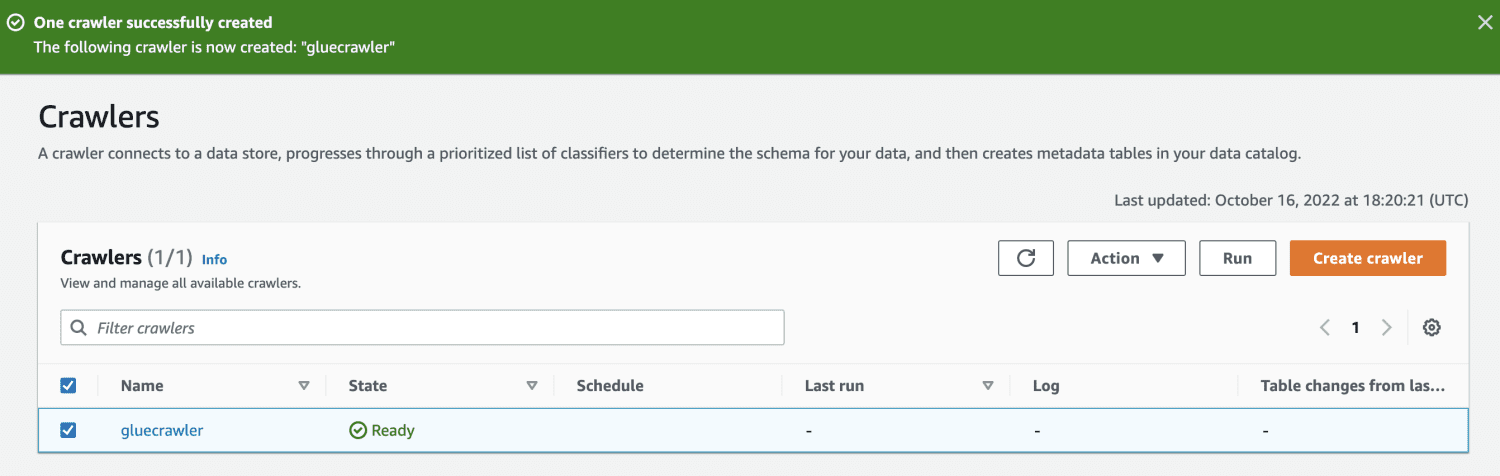
Чрез стартиране на робота базата данни ще получи таблица с всички данни от CSV файла.
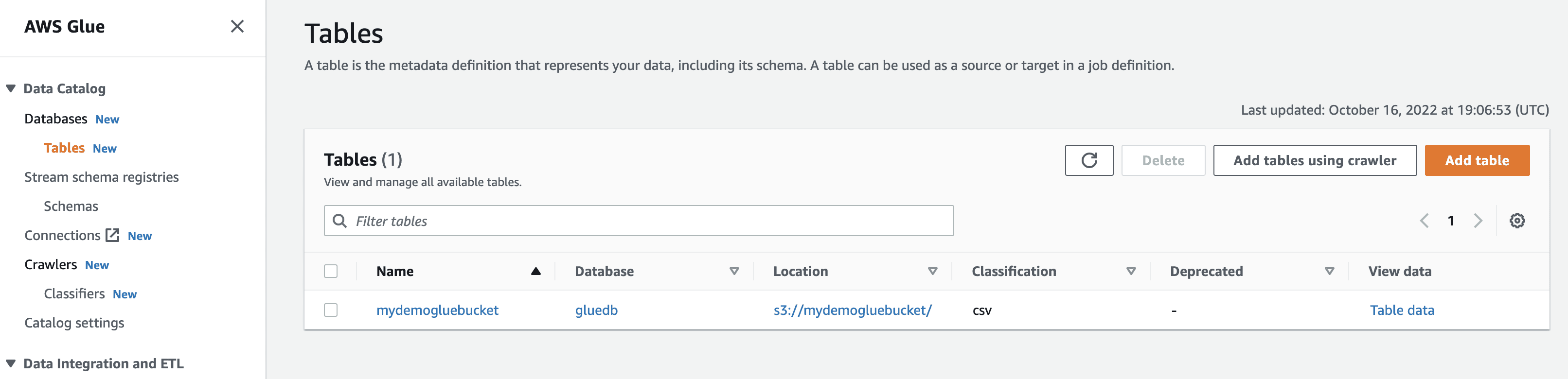
Когато щракнете върху преглед на данните, ще бъдете отведени до Amazon Athena (редактор на заявки). Когато изпълните заявката, можете да видите данните от таблицата.
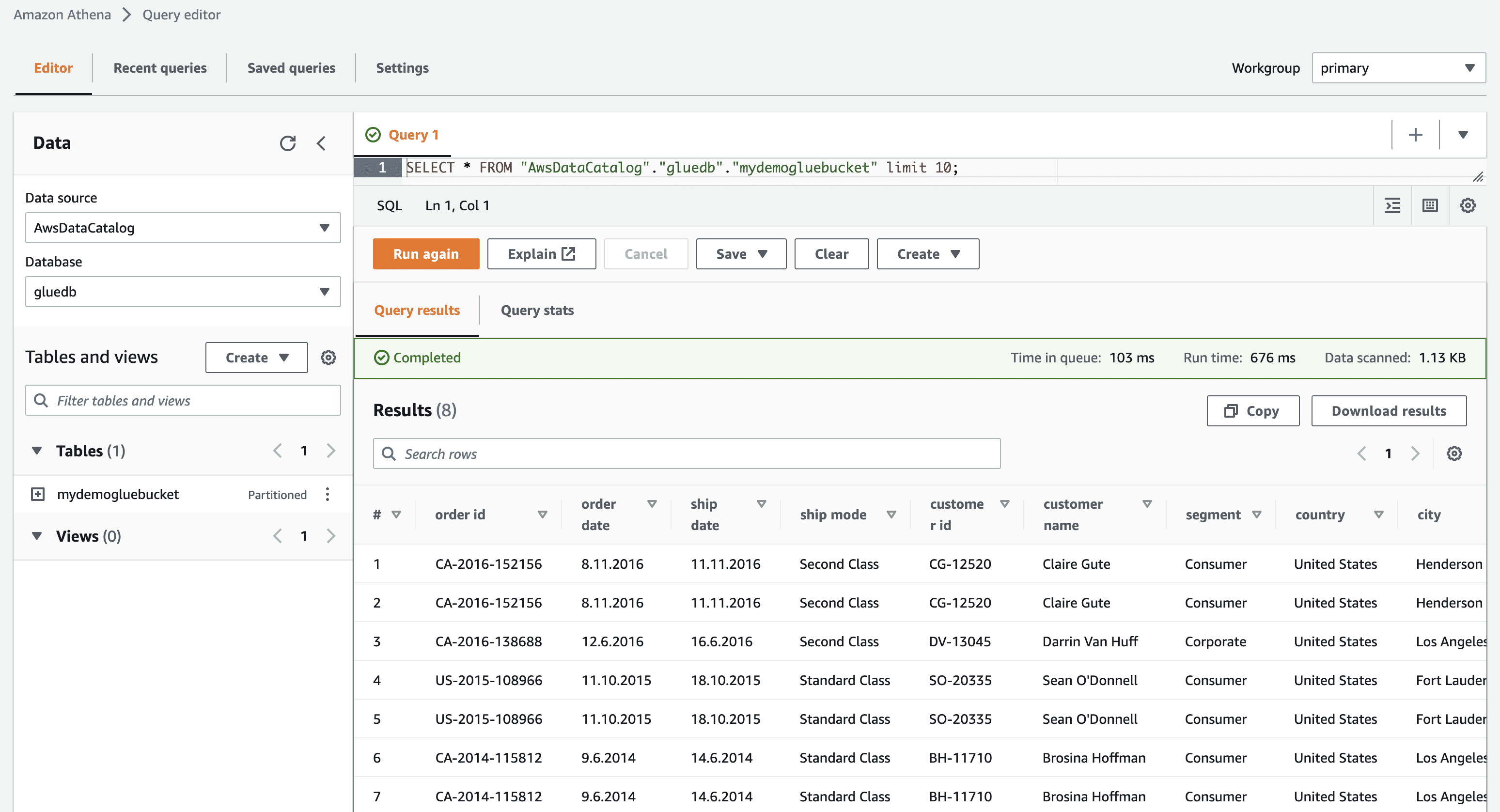
Сега можете успешно да използвате този AWS Glue робот във всяка ETL работа.
Какво е AWS Glue Databrew?
AWS Glue DataBrew позволява на потребителите да нормализират и почистват данни, без да пишат никакъв код. DataBrew може да намали времето, необходимо за подготовка на данни за машинно обучение и анализи с до 80 процента в сравнение с подготовката на данни, разработена по поръчка.
Има над 250 предварително направени трансформации на данни, които могат да се използват за автоматизиране на задачи за подготовка на данни, като филтриране на аномалии, коригиране на невалидни стойности и конвертиране на данни в стандартни формати.
DataBrew улеснява изследователите на данни, бизнес анализаторите и инженерите да си сътрудничат за извличане на прозрения от необработени данни. DataBrew е без сървър, така че не е необходимо да управлявате инфраструктура или да създавате клъстери, за да изследвате и трансформирате необработени данни на стойност терабайти.
Функции на DataBrew за предприятия
Подготовка на визуализирани данни
DataBrew е различен начин за преглед на данни, които обикновено се разглеждат в колонни бази данни като буквено-цифрови числа. DataBrew визуализира всички заредени източници на данни, за да ви помогне да разберете връзките и йерархията на данните.
250+ автоматизации за подготовка на данни
От учените по данни се очаква да следват различни повтарящи се изолирани работни потоци като част от тяхната работа. Тези работни потоци и процеси са моделирани от AWS като модулни модули за език и данни. Тази библиотека включва действия, които могат да се използват от крайните потребители.
Data Lineage
Подобно на регистрационните файлове за одит, които се използват за проследяване на активността на клиента в ИТ мрежата на ИТ мрежата, линията на данни ви позволява да проследявате дейностите по трансформиране на данни в AWS DataBrew. Тази информация включва източника на данни, приложените трансформации и изходните данни, включително целевото местоположение.
Картографиране на данни
Databrew ви позволява да намерите съвпадащи полета в два източника на данни. След като съвпадащите полета бъдат идентифицирани, те могат да бъдат заредени в схема.
AWS Glue DataBrew: Предимства
По-долу са характеристиките на AWS Glue DataBrew:
- По-ниска бариера за въвеждане за подготовка на данни
- Автоматизирано генериране на профил на данни
- Автоматизирайте 250+ процеса на подготовка на данни
- Интелигентни предписващи предложения
Алтернативи на лепилото AWS
Въздушно течение
Airflow принадлежи към раздела Workflow Manager на технологичния стек. Това е инструмент с отворен код, който поддържа GitHub stars, GitHub forks и други функции. Airflow ви позволява да създавате работни потоци с помощта на насочени ациклични диаграми (DAG). Планировчикът на въздушния поток изпълнява вашите задачи, като използва масив от работници и следвайки посочените зависимости.
Матилион

Matillion ETL, ETL/ELT инструмент, е проектиран изрично за платформи за облачни бази данни като Amazon Redshift и Google BigQuery. Това е модерен базиран на браузър потребителски интерфейс с мощни ETL/ELT възможности за натискане надолу. Можете да започнете да работите за минути с бърза настройка.
Стич
Stitch е ETL услуга с отворен код, която свързва множество източници на данни и репликира данни към предпочитани дестинации. Използва се много лесно, тъй като не са ви необходими познания по кодиране, за да премествате данни между източници и дестинации в Stitch. Той е лесен за използване, има приятелски GUI и е бърз.
Stitch не ви позволява да изберете предварително направено табло за управление, за разлика от други ETL инструменти. Вместо това трябва да интегрирате вашите данни в отворените хранилища за данни, които сте избрали като дестинация. Може да е трудно да се ориентирате в инвентара.
Алтерикс

Alteryx е платформа за автоматизация на анализи, която подпомага подготовката и смесването на събирането на данни. Тези данни могат да се използват за ускоряване на процесите и предоставяне на представа за бизнеса. Тъй като това е инструмент за плъзгане и пускане, нямате нужда от познания по програмиране. Alteryx е чудесно място за съвети и отговори от професионалисти в индустрията.
Заключение
И така, това беше всичко за AWS Glue, което е облачно базирано решение, което ви позволява да работите с ETL тръбопроводи. За да обобщим, процесът на взаимодействие с потребителя на AWS Glue се състои от три фази. За да създадете каталог с данни, първо използвате програми за обхождане на данни. След това създавате ETL кода, изискван от тръбопровода за данни на AWS. Накрая се създава ETL графикът. Надявам се, че този блог ви даде добър преглед на Amazon Glue.
Можете също така да разгледате най-добрите съвети за осигуряване на съхранение на AWS S3.