
Google JAX или Just After Execution е рамка, разработена от Google за ускоряване на задачите за машинно обучение.
Можете да го считате за библиотека за Python, която помага за по-бързо изпълнение на задачи, научни изчисления, трансформации на функции, дълбоко обучение, невронни мрежи и много други.
Съдържание
Относно Google JAX
Най-фундаменталният изчислителен пакет в Python е пакетът NumPy, който има всички функции като агрегации, векторни операции, линейна алгебра, манипулации с n-измерни масиви и матрици и много други разширени функции.
Какво ще стане, ако можем допълнително да ускорим изчисленията, извършвани с помощта на NumPy – особено за огромни набори от данни?
Имаме ли нещо, което може да работи еднакво добре на различни типове процесори като GPU или TPU, без никакви промени в кода?
Какво ще кажете, ако системата може да извършва трансформации на композируеми функции автоматично и по-ефективно?
Google JAX е библиотека (или рамка, както се казва в Wikipedia), която прави точно това и може би много повече. Той е създаден, за да оптимизира производителността и ефективно да изпълнява задачи за машинно обучение (ML) и дълбоко обучение. Google JAX предоставя следните функции за трансформация, които го правят уникален от другите ML библиотеки и помагат при напреднали научни изчисления за дълбоко обучение и невронни мрежи:
- Автоматична диференциация
- Автоматична векторизация
- Автоматично паралелизиране
- Компилация точно навреме (JIT).
Уникалните функции на Google JAX
Всички трансформации използват XLA (ускорена линейна алгебра) за по-висока производителност и оптимизиране на паметта. XLA е специфична за домейн оптимизираща компилираща машина, която изпълнява линейна алгебра и ускорява моделите TensorFlow. Използването на XLA върху вашия код на Python не изисква значителни промени в кода!
Нека разгледаме подробно всяка от тези функции.
Характеристики на Google JAX
Google JAX идва с важни функции за композируема трансформация за подобряване на производителността и по-ефективно изпълнение на задачи за дълбоко обучение. Например автоматично диференциране за получаване на градиента на функция и намиране на производни от всякакъв ред. По същия начин, автоматично паралелизиране и JIT за изпълнение на множество задачи паралелно. Тези трансформации са ключови за приложения като роботика, игри и дори изследвания.
Композируема трансформационна функция е чиста функция, която трансформира набор от данни в друга форма. Те се наричат композируеми, тъй като са самостоятелни (т.е. тези функции нямат зависимости с останалата част от програмата) и са без състояние (т.е. един и същ вход винаги ще води до същия изход).
Y(x) = T: (f(x))
В горното уравнение f(x) е оригиналната функция, към която се прилага трансформация. Y(x) е резултатната функция след прилагане на трансформацията.
Например, ако имате функция с име ‘total_bill_amt’ и искате резултатът като функционална трансформация, можете просто да използвате трансформацията, която желаете, да кажем градиент (град):
град_обща_сметка = град(обща_сметка_сума)
Чрез трансформиране на числени функции с помощта на функции като grad(), можем лесно да получим техните производни от по-висок порядък, които можем да използваме широко в алгоритми за оптимизиране на задълбочено обучение като градиентно спускане, като по този начин правим алгоритмите по-бързи и по-ефективни. По същия начин, като използваме jit(), можем да компилираме програми на Python точно навреме (мързеливо).
#1. Автоматична диференциация
Python използва функцията autograd за автоматично разграничаване на NumPy и родния код на Python. JAX използва модифицирана версия на autograd (т.е. град) и комбинира XLA (ускорена линейна алгебра), за да извърши автоматично диференциране и да намери производни от произволен ред за GPU (графични процесори) и TPU (тензорни процесори).]
Кратка бележка за TPU, GPU и CPU: CPU или централния процесор управлява всички операции на компютъра. GPU е допълнителен процесор, който подобрява изчислителната мощност и изпълнява операции от висок клас. TPU е мощно устройство, специално разработено за сложни и тежки работни натоварвания като AI и алгоритми за дълбоко обучение.
По същия начин като функцията autograd, която може да диференцира чрез цикли, рекурсии, разклонения и т.н., JAX използва функцията grad() за градиенти в обратен режим (обратно разпространение). Също така можем да диференцираме функция към произволен ред, използвайки grad:
град(град(град(грех θ))) (1.0)
Автоматично диференциране от по-висок порядък
Както споменахме преди, grad е доста полезен при намирането на частни производни на функция. Можем да използваме частична производна, за да изчислим градиентното спускане на функция на разходите по отношение на параметрите на невронната мрежа в дълбокото обучение, за да минимизираме загубите.
Изчисляване на частична производна
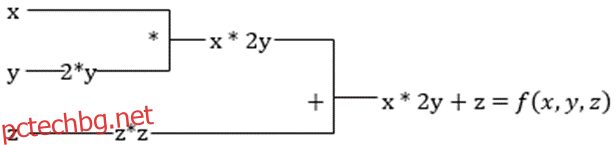
Да предположим, че една функция има множество променливи x, y и z. Намирането на производната на една променлива чрез запазване на другите променливи постоянни се нарича частична производна. Да предположим, че имаме функция,
f(x,y,z) = x + 2y + z2
Пример за показване на частична производна
Частната производна на x ще бъде ∂f/∂x, което ни казва как една функция се променя за променлива, когато другите са постоянни. Ако направим това ръчно, трябва да напишем програма за диференциране, да я приложим за всяка променлива и след това да изчислим градиентното спускане. Това би се превърнало в сложна и отнемаща време работа за множество променливи.
Автоматичното диференциране разбива функцията на набор от елементарни операции, като +, -, *, / или sin, cos, tan, exp и т.н., и след това прилага верижното правило за изчисляване на производната. Можем да направим това както в режим напред, така и в режим назад.
Това не е! Всички тези изчисления се случват толкова бързо (добре, помислете за милион изчисления, подобни на горните, и времето, което може да отнеме!). XLA се грижи за скоростта и производителността.
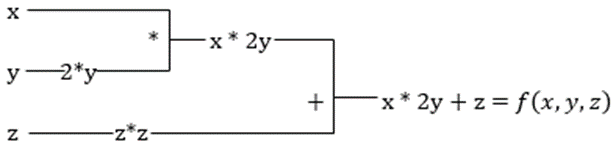
#2. Ускорена линейна алгебра
Нека вземем предишното уравнение. Без XLA, изчислението ще отнеме три (или повече) ядра, където всяко ядро ще изпълнява по-малка задача. Например,
Ядро k1 –> x * 2y (умножение)
k2 –> x * 2y + z (събиране)
k3 –> Намаляване
Ако същата задача се изпълнява от XLA, едно ядро се грижи за всички междинни операции, като ги слива. Междинните резултати от елементарни операции се предават поточно, вместо да се съхраняват в паметта, като по този начин се спестява памет и се повишава скоростта.
#3. Компилация точно навреме
JAX вътрешно използва XLA компилатора, за да увеличи скоростта на изпълнение. XLA може да увеличи скоростта на CPU, GPU и TPU. Всичко това е възможно чрез изпълнение на JIT код. За да използваме това, можем да използваме jit чрез импортиране:
from jax import jit def my_function(x): …………some lines of code my_function_jit = jit(my_function)
Друг начин е чрез декориране на jit върху дефиницията на функцията:
@jit def my_function(x): …………some lines of code
Този код е много по-бърз, защото трансформацията ще върне компилираната версия на кода на извикващия, вместо да използва интерпретатора на Python. Това е особено полезно за векторни входове, като масиви и матрици.
Същото важи и за всички съществуващи функции на Python. Например функции от пакета NumPy. В този случай трябва да импортираме jax.numpy като jnp, а не като NumPy:
import jax import jax.numpy as jnp x = jnp.array([[1,2,3,4], [5,6,7,8]])
След като направите това, основният обект на JAX масив, наречен DeviceArray, замества стандартния масив NumPy. DeviceArray е мързелив – стойностите се съхраняват в ускорителя, докато са необходими. Това също означава, че програмата JAX не чака резултатите да се върнат към извикващата (Python) програма, като по този начин следва асинхронно изпращане.
#4. Автоматична векторизация (vmap)
В един типичен свят на машинно обучение имаме набори от данни с милион или повече точки от данни. Най-вероятно ще извършим някои изчисления или манипулации върху всяка или повечето от тези точки от данни – което отнема много време и памет! Например, ако искате да намерите квадрата на всяка от точките от данни в набора от данни, първото нещо, за което ще се сетите, е да създадете цикъл и да вземете квадрата една по една – argh!
Ако създадем тези точки като вектори, можем да направим всички квадрати наведнъж, като извършим векторни или матрични манипулации върху точките с данни с нашия любим NumPy. И ако вашата програма може да направи това автоматично – можете ли да поискате нещо повече? Точно това прави JAX! Той може автоматично да векторизира всички ваши точки от данни, така че да можете лесно да извършвате всякакви операции върху тях – което прави вашите алгоритми много по-бързи и по-ефективни.
JAX използва функцията vmap за автоматично векторизиране. Разгледайте следния масив:
x = jnp.array([1,2,3,4,5,6,7,8,9,10]) y = jnp.square(x)
Правейки само горното, методът square ще се изпълни за всяка точка в масива. Но ако направите следното:
vmap(jnp.square(x))
Квадратът на метода ще се изпълни само веднъж, тъй като точките от данни сега се векторизират автоматично с помощта на метода vmap преди изпълнение на функцията, а цикълът се изтласква надолу към елементарното ниво на работа – което води до матрично умножение, а не скаларно умножение, като по този начин дава по-добра производителност .
#5. SPMD програмиране (pmap)
SPMD – или Програмирането на множество данни с една програма е от съществено значение в контексти на задълбочено обучение – често бихте приложили едни и същи функции върху различни набори от данни, намиращи се на множество GPU или TPU. JAX има функция, наречена помпа, която позволява паралелно програмиране на множество графични процесори или всеки ускорител. Подобно на JIT, програмите, използващи pmap, ще бъдат компилирани от XLA и изпълнени едновременно във всички системи. Това автоматично паралелизиране работи както за предни, така и за обратни изчисления.
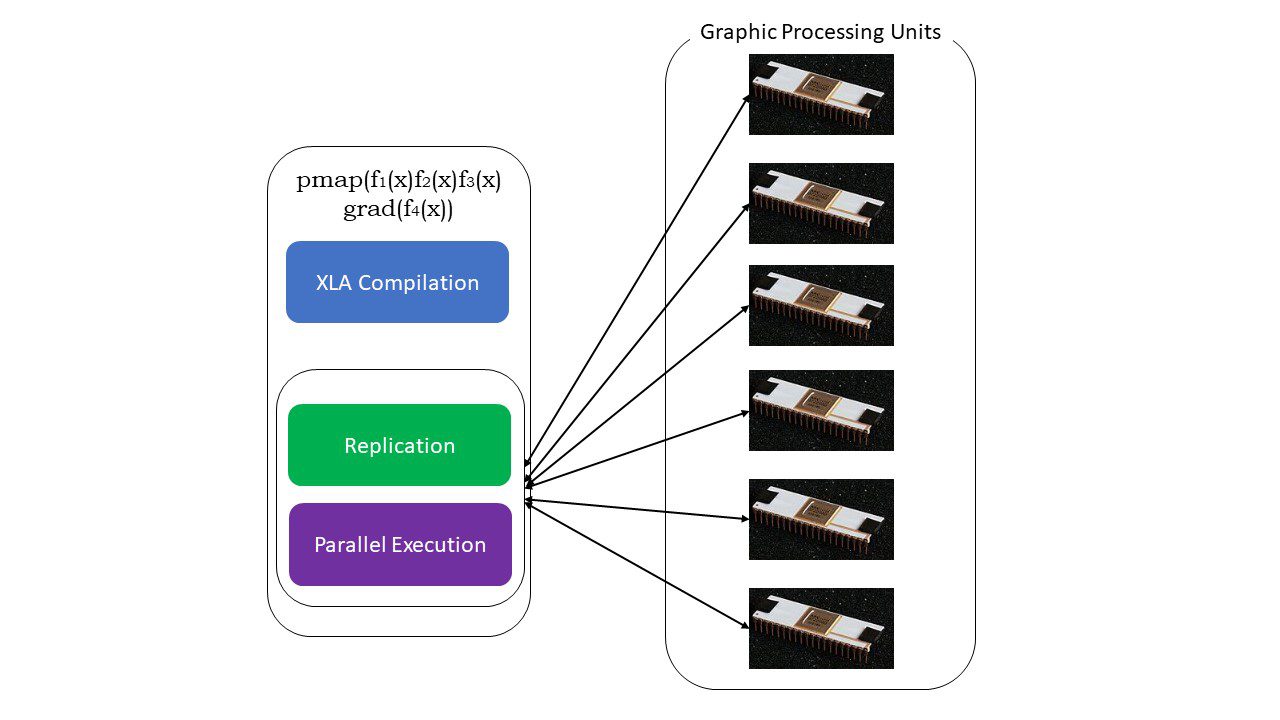 Как работи pmap
Как работи pmap
Можем също да приложим множество трансформации наведнъж в произволен ред върху всяка функция като:
pmap(vmap(jit(град (f(x)))))
Множество композируеми трансформации
Ограничения на Google JAX
Разработчиците на Google JAX са помислили добре за ускоряване на алгоритмите за задълбочено обучение, като същевременно въвеждат всички тези страхотни трансформации. Функциите и пакетите за научно изчисление са в съответствие с NumPy, така че не е нужно да се притеснявате за кривата на обучение. JAX обаче има следните ограничения:
- Google JAX все още е в ранните етапи на разработка и въпреки че основната му цел е оптимизиране на производителността, той не предоставя голяма полза за CPU изчисленията. NumPy изглежда се представя по-добре и използването на JAX може само да увеличи режийните разходи.
- JAX все още е в своето проучване или в начален етап и се нуждае от по-фина настройка, за да достигне инфраструктурните стандарти на рамки като TensorFlow, които са по-утвърдени и имат повече предварително дефинирани модели, проекти с отворен код и учебни материали.
- Към момента JAX не поддържа операционна система Windows – ще ви трябва виртуална машина, за да работи.
- JAX работи само върху чисти функции – такива, които нямат странични ефекти. За функции със странични ефекти JAX може да не е добър вариант.
Как да инсталирате JAX във вашата Python среда
Ако имате настройка на Python на вашата система и искате да стартирате JAX на вашата локална машина (CPU), използвайте следните команди:
pip install --upgrade pip pip install --upgrade "jax[cpu]"
Ако искате да стартирате Google JAX на GPU или TPU, следвайте инструкциите, дадени на GitHub JAX страница. За да настроите Python, посетете официални изтегляния на python страница.
Заключение
Google JAX е страхотен за писане на ефективни алгоритми за дълбоко обучение, роботика и изследвания. Въпреки ограниченията, той се използва широко с други рамки като Haiku, Flax и много други. Ще можете да оцените какво прави JAX, когато изпълнявате програми и да видите разликите във времето при изпълнение на код с и без JAX. Можете да започнете, като прочетете официална документация на Google JAXкоето е доста изчерпателно.