

На 1 септември 2020 г. NVIDIA разкри новата си гама графични процесори за игри: серията RTX 3000, базирана на тяхната архитектура Ampere. Ще обсъдим какво е новото, софтуера, задвижван от изкуствен интелект, който идва с него, и всички детайли, които правят това поколение наистина страхотно.
Съдържание
Запознайте се с графичните процесори от серия RTX 3000

Основното съобщение на NVIDIA беше нейните лъскави нови графични процесори, всички изградени върху персонализиран 8 nm производствен процес и всички внасящи значително ускорение както в растеризацията, така и в производителността на проследяване на лъчи.
В долния край на състава е RTX 3070, който струва $499. Това е малко скъпо за най-евтината карта, представена от NVIDIA при първоначалното обявяване, но е абсолютна кражба, след като научите, че надминава съществуващата RTX 2080 Ti, най-добрата карта, която редовно се продаваше на дребно над $1400. Въпреки това, след обявяването на NVIDIA, цената за продажба на трета страна спадна, като голям брой от тях бяха панически продадени в eBay за под $600.
Към обявяването няма солидни бенчмаркове, така че не е ясно дали картата наистина е обективно „по-добра“ от 2080 Ti, или дали NVIDIA изкривява малко маркетинга. Изпълняваните бенчмаркове бяха на 4K и вероятно имаше включен RTX, което може да направи разликата да изглежда по-голяма, отколкото ще бъде в чисто растеризирани игри, тъй като базираната на Ampere серия 3000 ще се представи над два пъти по-добре при проследяване на лъчи от Turing. Но тъй като трасирането на лъчи сега е нещо, което не вреди много на производителността и се поддържа в последното поколение конзоли, е основна търговска точка да работи толкова бързо, колкото флагманът на последното поколение за почти една трета от цената.
Също така не е ясно дали цената ще остане такава. Дизайните на трети страни редовно добавят най-малко $50 към цената и с това колко голямо ще бъде търсенето, няма да е изненадващо да го видите да се продава за $600 през октомври 2020 г.
Точно над това е RTX 3080 на $699, което би трябвало да е два пъти по-бързо от RTX 2080 и да е с около 25-30% по-бързо от 3080.
След това, в горния край, новият флагман е RTX 3090, което е комично огромно. NVIDIA е добре запозната и го нарича „BFGPU“, което според компанията означава „Big Ferocious GPU“.

NVIDIA не показа никакви директни показатели за производителност, но компанията показа, че работи с 8K игри при 60 FPS, което е сериозно впечатляващо. Разбира се, NVIDIA почти сигурно използва DLSS, за да достигне тази марка, но 8K игрите са 8K игри.
Разбира се, в крайна сметка ще има 3060 и други вариации на по-бюджетно ориентирани карти, но те обикновено идват по-късно.
За да охлади нещата, NVIDIA се нуждаеше от обновен дизайн на охладителя. 3080 е оценен за 320 вата, което е доста високо, така че NVIDIA е избрала дизайн с двоен вентилатор, но вместо двата вентилатора vwinf, поставени отдолу, NVIDIA е поставила вентилатор в горния край, където обикновено се намира задната плоча. Вентилаторът насочва въздуха нагоре към охладителя на процесора и горната част на корпуса.

Съдейки по това колко производителност може да бъде повлияна от лошия въздушен поток в кутията, това е напълно логично. Въпреки това, платката е много тясна поради това, което вероятно ще се отрази на продажните цени на трети страни.
DLSS: Софтуерно предимство
Проследяването на лъчи не е единственото предимство на тези нови карти. Наистина, всичко е малко хак – сериите RTX 2000 и 3000 не са много по-добри в извършването на реално проследяване на лъчи, в сравнение с по-старите поколения карти. Трасирането на лъчи на пълна сцена в 3D софтуер като Blender обикновено отнема няколко секунди или дори минути на кадър, така че грубата сила за под 10 милисекунди не може да се говори.
Разбира се, има специален хардуер за извършване на изчисления на лъчи, наречени RT ядра, но до голяма степен NVIDIA избра различен подход. NVIDIA подобри алгоритмите за намаляване на шума, които позволяват на графичните процесори да изобразяват много евтин единичен проход, който изглежда ужасен, и някак си – чрез магията на AI – да го превърне в нещо, което геймърът иска да види. Когато се комбинира с традиционни техники, базирани на растеризация, това създава приятно изживяване, подсилено от ефекти за проследяване на лъчи.

Въпреки това, за да направи това бързо, NVIDIA добави специфични за AI процесорни ядра, наречени Tensor ядра. Те обработват цялата математика, необходима за стартиране на модели за машинно обучение, и го правят много бързо. Общо са промяна на играта за AI в пространството на облачния сървър, тъй като AI се използва широко от много компании.
Освен обезшумяването, основното използване на ядрата Tensor за геймърите се нарича DLSS или супер извадка за дълбоко обучение. Той приема рамка с ниско качество и я повишава до напълно естествено качество. Това по същество означава, че можете да играете с 1080p ниво на кадри, докато гледате 4K картина.
Това също помага за ефективността на проследяване на лъчи доста –бенчмаркове от PCMag покажете RTX 2080 Super работещ Control с ултра качество, с всички настройки за проследяване на лъчи, настроени на макс. При 4K се бори само с 19 FPS, но с включен DLSS получава много по-добри 54 FPS. DLSS е безплатна производителност за NVIDIA, възможна благодарение на тензорните ядра на Turing и Ampere. Всяка игра, която го поддържа и е ограничена от GPU, може да види сериозни ускорения само от софтуер.
DLSS не е нова и беше обявена като функция, когато серия RTX 2000 стартира преди две години. По това време той се поддържаше от много малко игри, тъй като изискваше NVIDIA да обучава и настройва модел за машинно обучение за всяка отделна игра.
Въпреки това, през това време NVIDIA го пренаписа напълно, наричайки новата версия DLSS 2.0. Това е API с общо предназначение, което означава, че всеки разработчик може да го внедри и вече се използва от повечето големи издания. Вместо да работи върху един кадър, той приема векторни данни за движение от предишния кадър, подобно на TAA. Резултатът е много по-рязък от DLSS 1.0 и в някои случаи всъщност изглежда по-добре и по-рязко дори от естествената разделителна способност, така че няма много причина да не го включвате.
Има една уловка – когато превключвате изцяло сцени, както в катсцените, DLSS 2.0 трябва да изобрази първия кадър с 50% качество, докато чака данните за вектора на движение. Това може да доведе до малък спад в качеството за няколко милисекунди. Но 99% от всичко, което гледате, ще бъде изобразено правилно и повечето хора не го забелязват на практика.
Ampere Architecture: Създаден за AI
Амперът е бърз. Сериозно бързо, особено при изчисления на AI. RT ядрото е 1,7 пъти по-бързо от Тюринг, а новото ядро Tensor е 2,7 пъти по-бързо от Тюринг. Комбинацията от двете е истински скок на поколенията в производителността на проследяването на лъчите.

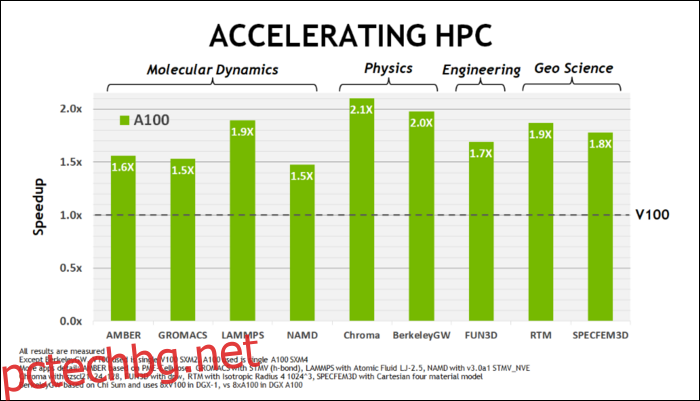
По-рано този май, NVIDIA пусна графичния процесор Ampere A100, GPU в центъра за данни, предназначен за работа с AI. С него те подробно описаха много от това, което прави Ampere толкова по-бърз. За центрове за данни и високопроизводителни изчислителни натоварвания, Ampere като цяло е около 1,7 пъти по-бърз от Turing. За AI обучение е до 6 пъти по-бързо.
С Ampere NVIDIA използва нов числов формат, предназначен да замени индустриалния стандарт „Floating-Point 32“ или FP32 при някои работни натоварвания. Под капака всяко число, което вашият компютър обработва, заема предварително определен брой битове в паметта, независимо дали това е 8 бита, 16 бита, 32, 64 или дори по-голям. Числата, които са по-големи, са по-трудни за обработка, така че ако можете да използвате по-малък размер, ще имате по-малко за хрускане.
FP32 съхранява 32-битово десетично число и използва 8 бита за диапазона на числото (колко голямо или малко може да бъде) и 23 бита за прецизност. Твърдението на NVIDIA е, че тези 23 прецизни бита не са напълно необходими за много AI натоварвания и можете да получите подобни резултати и много по-добра производителност само от 10 от тях. Намаляването на размера до само 19 бита, вместо до 32, прави голяма разлика в много изчисления.
Този нов формат се нарича Tensor Float 32, а тензорните ядра в A100 са оптимизирани за работа със странния формат. Това е, наред със свиването на матрицата и увеличаването на броя на ядрото, как те получават огромното 6x ускорение при обучението на AI.

В допълнение към новия формат на числата, Ampere вижда значително ускоряване на производителността при специфични изчисления, като FP32 и FP64. Те не означават директно повече FPS за лаиците, но са част от това, което го прави почти три пъти по-бърз като цяло при операциите на Tensor.

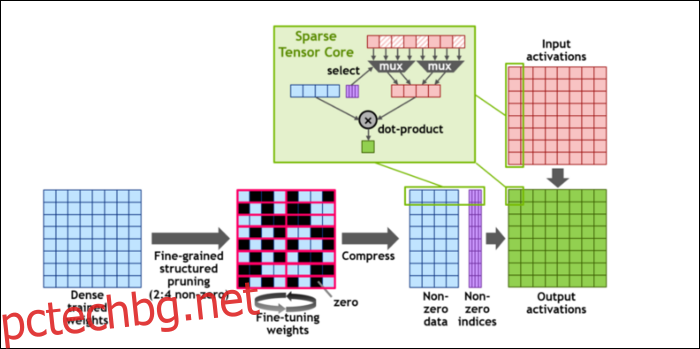
След това, за да ускорят още повече изчисленията, те въведоха концепцията за фино-зърнеста структурирана рядкост, което е много фантастична дума за доста проста концепция. Невронните мрежи работят с големи списъци от числа, наречени тегла, които влияят на крайния резултат. Колкото повече числа трябва да хрускате, толкова по-бавно ще бъде.
Въпреки това, не всички от тези числа са всъщност полезни. Някои от тях са буквално нулеви и по принцип могат да бъдат изхвърлени, което води до огромни ускорения, когато можете да хрускате повече числа едновременно. Sparsity по същество компресира числата, което отнема по-малко усилия за извършване на изчисления. Новото „Sparse Tensor Core“ е създадено за работа с компресирани данни.
Въпреки промените, NVIDIA казва, че това изобщо не трябва да влияе забележимо върху точността на обучените модели.
За изчисления на Sparse INT8, един от най-малките формати на числата, пиковата производителност на един графичен процесор A100 е над 1,25 PetaFLOPs, удивително висок брой. Разбира се, това е само при хрускане на един конкретен вид число, но въпреки това е впечатляващо.