
Ако сте нов в анализа на големи данни, множеството инструменти на apache може да са на вашия радар; Въпреки това, наборът от различни инструменти може да стане объркващ и на моменти непосилен.
Тази публикация ще разреши това объркване и ще обясни какво представляват Apache Hive и Impala и какво ги прави различни един от друг!
Съдържание
Apache Hive
Apache Hive е SQL интерфейс за достъп до данни за платформата Apache Hadoop. Hive ви позволява да правите заявки, да събирате и анализирате данни с помощта на SQL синтаксис.
Схема за достъп за четене се използва за данни във файловата система HDFS, което ви позволява да третирате данните като с обикновена таблица или релационна СУБД. HiveQL заявките се превеждат в Java код за задания на MapReduce.
Заявките за Hive са написани на езика за заявки HiveQL, който е базиран на езика SQL, но няма пълна поддръжка за стандарта SQL-92.
Този език обаче позволява на програмистите да използват своите заявки, когато е неудобно или неефективно да използват функциите на HiveQL. HiveQL може да бъде разширен с дефинирани от потребителя скаларни функции (UDF), агрегации (UDAF кодове) и таблични функции (UDTF).
Как работи Apache Hive
Apache Hive превежда програми, написани на език HiveQL (близък до SQL) в една или повече задачи на MapReduce, Apache Tez или Apache Spark. Това са три изпълнителни машини, които могат да бъдат стартирани на Hadoop. След това Apache Hive организира данните в масив за файла на разпределената файлова система Hadoop (HDFS), за да изпълнява заданията на клъстер, за да произведе отговор.
Таблиците на Apache Hive са подобни на релационните бази данни и единиците данни са организирани от най-значимата единица до най-подробната. Базите данни са масиви, съставени от дялове, които отново могат да бъдат разделени на „кофи“.
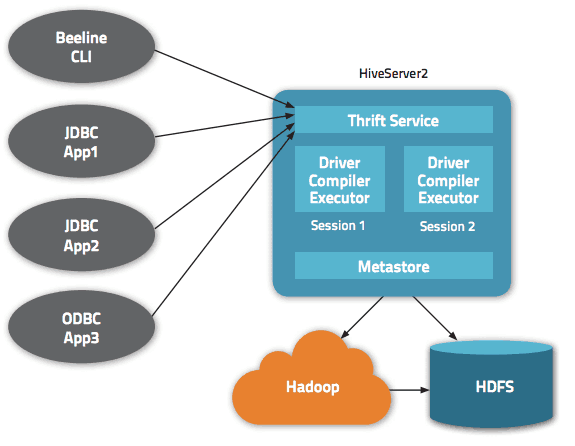
Данните са достъпни чрез HiveQL. Във всяка база данни данните са номерирани и всяка таблица съответства на HDFS директория.
В рамките на архитектурата на Apache Hive са налични множество интерфейси, като например уеб интерфейс, CLI или външни клиенти.
Наистина, сървърът „Apache Hive Thrift“ позволява на отдалечени клиенти да изпращат команди и заявки към Apache Hive, използвайки различни езици за програмиране. Централната директория на Apache Hive е „metastore“, съдържащ цялата информация.
Двигателят, който кара Hive да работи, се нарича „драйвер“. Той обединява компилатор и оптимизатор, за да определи оптималния план за изпълнение.
И накрая, сигурността се осигурява от Hadoop. Следователно той разчита на Kerberos за взаимно удостоверяване между клиента и сървъра. Разрешението за новосъздадени файлове в Apache Hive се диктува от HDFS, което позволява потребителско, групово или друго разрешение.
Характеристики на Hive
- Поддържа изчислителния двигател на Hadoop и Spark
- Използва HDFS и работи като склад за данни.
- Използва MapReduce и поддържа ETL
- Благодарение на HDFS, той има толерантност към грешки, подобна на Hadoop
Apache Hive: Предимства
Apache Hive е идеално решение за заявки и анализ на данни. Това прави възможно получаването на качествени прозрения, осигурявайки конкурентно предимство и улеснявайки реагирането на пазарното търсене.
Сред основните предимства на Apache Hive можем да споменем лекотата на използване, свързана с неговия „удобен за SQL“ език. В допълнение, той ускорява първоначалното вмъкване на данни, тъй като не е необходимо данните да се четат или номерират от диск във формата на вътрешна база данни.
Знаейки, че данните се съхраняват в HDFS, е възможно съхраняването на големи набори от данни до стотици петабайта данни в Apache Hive. Това решение е много по-мащабируемо от традиционната база данни. Знаейки, че това е облачна услуга, Apache Hive позволява на потребителите бързо да стартират виртуални сървъри въз основа на колебания в натоварванията (т.е. задачи).
Сигурността също е аспект, при който Hive се представя по-добре, със способността си да възпроизвежда критични за възстановяване натоварвания в случай на проблем. И накрая, работният капацитет е несравним, тъй като може да изпълни до 100 000 заявки на час.
Apache Impala
Apache Impala е машина за масивни паралелни SQL заявки за интерактивно изпълнение на SQL заявки върху данни, съхранявани в Apache Hadoop, написана на C++ и разпространявана под лиценза Apache 2.0.
Impala се нарича още MPP (Massively Parallel Processing) двигател, разпределена СУБД и дори стекова база данни SQL-на-Hadoop.

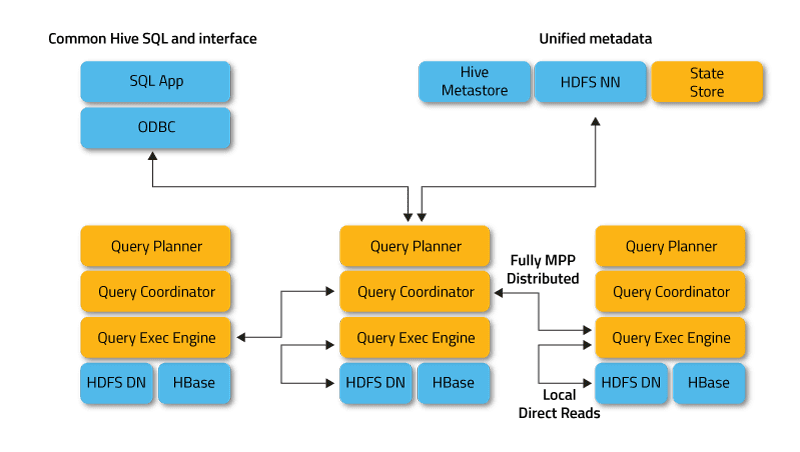
Impala работи в разпределен режим, където екземплярите на процеси се изпълняват на различни клъстерни възли, като получават, планират и координират клиентски заявки. В този случай е възможно паралелно изпълнение на фрагменти от SQL заявката.
Клиентите са потребители и приложения, които изпращат SQL заявки срещу данни, съхранявани в Apache Hadoop (HBase и HDFS) или Amazon S3. Взаимодействието с Impala се осъществява чрез уеб интерфейса HUE (Hadoop User Experience), ODBC, JDBC и обвивката на командния ред на Impala Shell.
Impala зависи инфраструктурно от друг популярен инструмент SQL-on-Hadoop, Apache Hive, използвайки своето хранилище за метаданни. По-специално, Hive Metastore позволява на Impala да знае за наличността и структурата на базите данни.
При създаване, модифициране и изтриване на обекти на схема или зареждане на данни в таблици чрез SQL изрази, съответните промени в метаданните се разпространяват автоматично до всички възли на Impala с помощта на специализирана директория.
Ключовите компоненти на Impala са следните изпълними файлове:
- Impalad или Impala daemon е системна услуга, която планира и изпълнява заявки за HDFS, HBase и Amazon S3 данни. Един impalad процес се изпълнява на всеки клъстерен възел.
- Statestore е услуга за именуване, която следи местоположението и състоянието на всички екземпляри на impalad в клъстера. Едно копие на тази системна услуга се изпълнява на всеки възел и главния сървър (Name Node).
- Каталогът е услуга за координиране на метаданни, която разпространява промени от Impala DDL и DML изрази до всички засегнати възли на Impala, така че новите таблици или новозаредените данни да са незабавно видими за всеки възел в клъстера. Препоръчително е един екземпляр на Catalog да се изпълнява на същия клъстерен хост като Statestored демона.
Как работи Apache Impala
Impala, подобно на Apache Hive, използва подобен декларативен език за заявки, Hive Query Language (HiveQL), който е подмножество на SQL92, вместо SQL.
Действителното изпълнение на заявката в Impala е както следва:
Клиентското приложение изпраща SQL заявка, като се свързва към всеки impalad чрез стандартизирани ODBC или JDBC интерфейси на драйвери. Свързаният импалад става координатор на текущата заявка.
SQL заявката се анализира, за да се определят задачите за impalad екземплярите в клъстера; след това се изгражда оптималният план за изпълнение на заявката.
Impalad има директен достъп до HDFS и HBase, като използва локални екземпляри на системни услуги за предоставяне на данни. За разлика от Apache Hive, такова директно взаимодействие значително спестява време за изпълнение на заявката, тъй като междинните резултати не се запазват.
В отговор всеки демон връща данни на координиращия импалад, изпращайки резултатите обратно на клиента.
Характеристики на Impala
- Поддръжка за обработка в паметта в реално време
- Удобен за SQL
- Поддържа системи за съхранение като HDFS, Apache HBase и Amazon S3
- Поддържа интеграция с BI инструменти като Pentaho и Tableau
- Използва синтаксис на HiveQL
Apache Impala: Предимства
Impala избягва евентуални допълнителни разходи при стартиране, тъй като всички процеси на системни демони се стартират директно по време на зареждане. Това значително спестява време за изпълнение на заявката. Допълнително увеличение на скоростта на Impala е, защото този SQL инструмент за Hadoop, за разлика от Hive, не съхранява междинни резултати и има директен достъп до HDFS или HBase.
Освен това Impala генерира програмен код по време на изпълнение, а не при компилация, както прави Hive. Страничен ефект от високоскоростната работа на Impala обаче е намалената надеждност.
По-конкретно, ако възелът за данни падне по време на изпълнение на SQL заявка, екземплярът на Impala ще се рестартира и Hive ще продължи да поддържа връзка с източника на данни, осигурявайки толерантност към грешки.
Други предимства на Impala включват вградена поддръжка за защитен мрежов протокол за удостоверяване Kerberos, приоритизиране и възможност за управление на опашката от заявки и поддръжка на популярни формати за големи данни като LZO, Avro, RCFile, Parquet и Sequence.
Кошер срещу Импала: Прилики
Hive и Impala се разпространяват свободно под лиценза на Apache Software Foundation и се отнасят до SQL инструменти за работа с данни, съхранявани в Hadoop клъстер. В допълнение, те също използват HDFS разпределена файлова система.
Impala и Hive изпълняват различни задачи с общ фокус върху SQL обработката на големи данни, съхранявани в Apache Hadoop клъстер. Impala предоставя интерфейс, подобен на SQL, който ви позволява да четете и пишете Hive таблици, като по този начин позволява лесен обмен на данни.
В същото време Impala прави SQL операциите на Hadoop доста бързи и ефективни, което позволява използването на тази СУБД в изследователски проекти за анализ на големи данни. Когато е възможно, Impala работи със съществуваща инфраструктура на Apache Hive, която вече се използва за изпълнение на дълготрайни пакетни SQL заявки.
Освен това Impala съхранява своите дефиниции на таблици в metastore, традиционна MySQL или PostgreSQL база данни, т.е. на същото място, където Hive съхранява подобни данни. Той позволява на Impala да има достъп до Hive таблици, стига всички колони да използват поддържаните от Impala типове данни, файлови формати и кодеци за компресиране.
Кошер срещу Импала: Разлики

Програмен език
Hive е написан на Java, докато Impala е написан на C++. Въпреки това, Impala също използва някои базирани на Java Hive UDF.
Случаи на употреба
Инженерите по данни използват Hive в ETL процеси (Extract, Transform, Load), например, за дълготрайни пакетни задания върху големи набори от данни, например в агрегатори за пътуване и информационни системи за летища. От своя страна Impala е предназначена главно за анализатори и специалисти по данни и се използва главно в задачи като бизнес разузнаване.
производителност
Impala изпълнява SQL заявки в реално време, докато Hive се характеризира с ниска скорост на обработка на данни. С прости SQL заявки Impala може да работи 6-69 пъти по-бързо от Hive. Но Hive се справя по-добре със сложни заявки.
Закъснение/производителност
Пропускателната способност на Hive е значително по-висока от тази на Impala. Функцията LLAP (Live Long and Process), която позволява кеширане на заявки в паметта, дава на Hive добра производителност на ниско ниво.
LLAP включва дългосрочни системни услуги (демони), които ви позволяват директно да взаимодействате с HDFS възли за данни и да замените тясно интегрираната DAG структура на заявката (насочена ациклична графика) – графичен модел, използван активно в изчисленията с големи данни.
Толерантност към грешки
Hive е устойчива на грешки система, която запазва всички междинни резултати. Това също влияе положително на скалируемостта, но води до намаляване на скоростта на обработка на данни. От своя страна Impala не може да се нарече устойчива на грешки платформа, защото е по-обвързана с паметта.
Преобразуване на код
Hive генерира изрази за заявки по време на компилиране, докато Impala ги генерира по време на изпълнение. Hive се характеризира с проблем със „студен старт“ при първото стартиране на приложението; заявките се преобразуват бавно поради необходимостта от установяване на връзка с източника на данни.
Impala няма този вид стартови разходи. Необходимите системни услуги (демони) за обработка на SQL заявки се стартират по време на зареждане, което ускорява работата.
Поддръжка за съхранение
Impala поддържа формати LZO, Avro и Parquet, докато Hive работи с обикновен текст и ORC. И двата обаче поддържат форматите RCFIle и Sequence.
Apache HiveApache ImpalaLanguage JavaC++ Случаи на използванеИнженеринг на данниАнализ и анализ на производителностВисока за прости заявки Сравнително ниска латентностПовече латентност поради кеширанеПо-малко латентна толерантност към грешкиПо-толерантна поради MapReduceПо-малко толерантна поради MPPConversionБавна поради студен стартПо-бързо преобразуване Поддръжка за съхранениеPlain Text и ORCLZO, Avro, Parquet
Заключителни думи
Hive и Impala не се конкурират, а по-скоро ефективно се допълват. Въпреки че има значителни разлики между двете, има и доста общи неща и изборът на едното пред другото зависи от данните и конкретните изисквания на проекта.
Можете също така да изследвате непосредствените сравнения между Hadoop и Spark.
.