
Статистиката на Forbes гласи, че до 90% от световните организации използват Big Data analytics, за да създават своите инвестиционни отчети.
С нарастващата популярност на Big Data, следователно има скок на възможностите за работа в Hadoop повече от преди.
Ето защо, за да ви помогнем да получите тази роля на Hadoop експерт, можете да използвате тези въпроси и отговори за интервю, които сме събрали за вас в тази статия, за да ви помогнем да преминете през интервюто.
Може би познаването на факти като диапазон на заплатите, които правят ролите в Hadoop и Big Data доходоносни, ще ви мотивира да преминете това интервю, нали? 🤔
- Според indeed.com, базиран в САЩ Big Data Hadoop разработчик получава средна заплата от $144 000.
- Според itjobswatch.co.uk средната заплата на разработчиците на Big Data Hadoop е £66 750.
- В Индия източникът на indeed.com заявява, че те биха спечелили средна заплата от ₹ 16 00 000.
Доходоносно, не мислите ли? Сега, нека скочим, за да научим за Hadoop.
Съдържание
Какво е Hadoop?
Hadoop е популярна рамка, написана на Java, която използва програмни модели за обработка, съхраняване и анализиране на големи набори от данни.
По подразбиране неговият дизайн позволява мащабиране от един сървър до множество машини, които предлагат локално изчисление и съхранение. Освен това способността му да открива и обработва повреди на приложния слой, което води до услуги с висока достъпност, прави Hadoop доста надежден.
Нека преминем направо към често задаваните въпроси за интервю с Hadoop и техните правилни отговори.
Въпроси и отговори за интервюто на Hadoop
Какво представлява единицата за съхранение в Hadoop?
Отговор: Устройството за съхранение на Hadoop се нарича Hadoop Distributed File System (HDFS).
Как се различава мрежовото хранилище от разпределената файлова система Hadoop?
Отговор: HDFS, което е основното хранилище на Hadoop, е разпределена файлова система, която съхранява масивни файлове, използвайки стандартен хардуер. От друга страна, NAS е сървър за съхранение на компютърни данни на ниво файл, който предоставя хетерогенни клиентски групи с достъп до данните.
Докато съхранението на данни в NAS е на специален хардуер, HDFS разпределя блоковете с данни между всички машини в рамките на Hadoop клъстера.
NAS използва устройства за съхранение от висок клас, което е доста скъпо, докато стандартният хардуер, използван в HDFS, е рентабилен.
NAS отделно съхранява данни от изчисления, което го прави неподходящ за MapReduce. Напротив, дизайнът на HDFS му позволява да работи с рамката MapReduce. Изчисленията се преместват към данните в рамката MapReduce вместо данните към изчисленията.
Обяснете MapReduce в Hadoop и Shuffling
Отговор: MapReduce се отнася до две отделни задачи, които Hadoop програмите изпълняват, за да осигурят голяма мащабируемост в стотици до хиляди сървъри в рамките на Hadoop клъстер. Разбъркването, от друга страна, прехвърля изхода на картата от Mappers към необходимия Reducer в MapReduce.
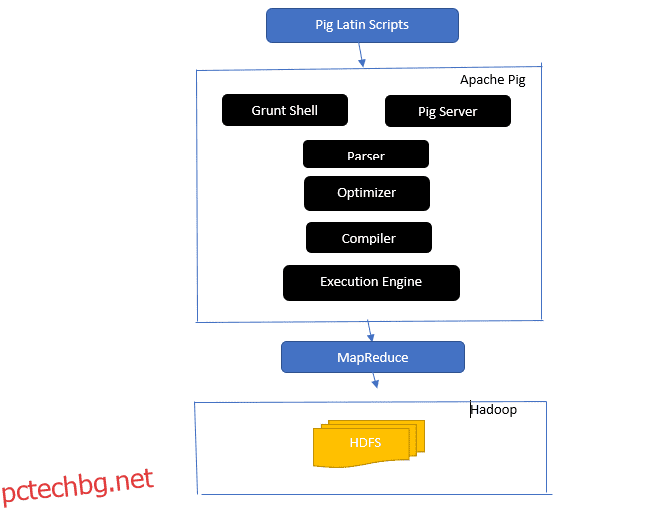
Надникнете в архитектурата на Apache Pig
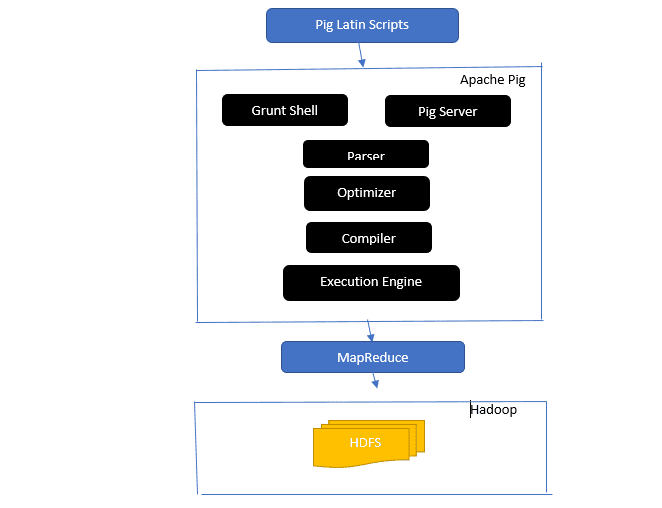 Архитектурата на Apache Pig
Архитектурата на Apache Pig
Отговор: Архитектурата на Apache Pig има интерпретатор на Pig Latin, който обработва и анализира големи набори от данни, използвайки скриптове на Pig Latin.
Apache pig също се състои от набори от набори от данни, върху които се извършват операции с данни като присъединяване, зареждане, филтриране, сортиране и групиране.
Езикът Pig Latin използва механизми за изпълнение като Grant shells, UDFs и вградени за писане на Pig скриптове, които изпълняват необходимите задачи.
Pig улеснява работата на програмистите, като преобразува тези писмени скриптове в серия задания на Map-Reduce.
Архитектурните компоненти на Apache Pig включват:
- Парсер – Той обработва скриптовете на Pig, като проверява синтаксиса на скрипта и извършва проверка на типа. Изходът на анализатора представлява изразите и логическите оператори на Pig Latin и се нарича DAG (насочена ациклична графика).
- Оптимизатор – Оптимизаторът прилага логически оптимизации като проекция и натискане на DAG.
- Компилатор – компилира оптимизирания логически план от оптимизатора в поредица от задания на MapReduce.
- Механизъм за изпълнение – Това е мястото, където се извършва окончателното изпълнение на задачите MapReduce в желания изход.
- Режим на изпълнение – Режимите на изпълнение в Apache pig включват главно локален и Map Reduce.
Отговор: Услугата Metastore в Local Metastore работи в същата JVM като Hive, но се свързва с база данни, работеща в отделен процес на същата или отдалечена машина. От друга страна, Metastore в Remote Metastore работи в своята JVM отделно от JVM на услугата Hive.
Какви са петте V на Big Data?
Отговор: Тези пет V означават основните характеристики на Big Data. Те включват:
- Стойност: Големите данни се стремят да осигурят значителни ползи от високата възвръщаемост на инвестициите (ROI) за организация, която използва големи данни в своите операции с данни. Големите данни носят тази стойност от своите прозрения и разпознаване на модели, което води до по-силни връзки с клиентите и по-ефективни операции, наред с други предимства.
- Разнообразие: Това представлява хетерогенността на вида на събраните типове данни. Различните формати включват CSV, видео, аудио и др.
- Обем: Това определя значителното количество и размер на данните, управлявани и анализирани от дадена организация. Тези данни показват експоненциален растеж.
- Скорост: Това е експоненциалната скорост на нарастване на данните.
- Верност: Верността се отнася до това колко „несигурни“ или „неточни“ налични данни се дължат на това, че данните са непълни или непоследователни.
Обяснете различните типове данни на латиница за прасе.
Отговор: Типовете данни в Pig Latin включват атомарни типове данни и сложни типове данни.
Атомните типове данни са основните типове данни, използвани във всеки друг език. Те включват следното:
- Int – Този тип данни дефинира 32-битово цяло число със знак. Пример: 13
- Long – Long дефинира 64-битово цяло число. Пример: 10л
- Float – Дефинира 32-битова плаваща запетая със знак. Пример: 2,5F
- Double – Дефинира 64-битова плаваща запетая със знак. Пример: 23.4
- Boolean – Дефинира булева стойност. Включва: Вярно/Невярно
- Дата и час – Дефинира стойност за дата и час. Пример: 1980-01-01T00:00.00.000+00:00
Сложните типове данни включват:
- Карта – Картата се отнася до набор от двойки ключ-стойност. Пример: [‘color’#’yellow’, ‘number’#3]
- Чанта – Това е колекция от набор от кортежи и използва символа „{}“. Пример: {(Хенри, 32), (Кити, 47)}
- Кортеж – Кортежът дефинира подреден набор от полета. Пример : (Възраст, 33)
Какво представляват Apache Oozie и Apache ZooKeeper?
Отговор: Apache Oozie е планировчик на Hadoop, който отговаря за планирането и обвързването на Hadoop задачи заедно като единна логическа работа.
Apache Zookeeper, от друга страна, координира с различни услуги в разпределена среда. Спестява време на разработчиците, като просто излага прости услуги като синхронизиране, групиране, поддръжка на конфигурацията и именуване. Apache Zookeeper също така предоставя готова поддръжка за опашка и избор на лидер.
Каква е ролята на Combiner, RecordReader и Partitioner в операция MapReduce?
Отговор: Комбинаторът действа като мини редуктор. Той получава и работи с данни от задачи за карта и след това предава изхода на данните към фазата на редуктора.
RecordHeader комуникира с InputSplit и преобразува данните в двойки ключ-стойност, за да може картографът да ги прочете по подходящ начин.
Разделителят е отговорен за определянето на броя редуцирани задачи, необходими за обобщаване на данни и потвърждаване на начина, по който изходните данни на комбинатора се изпращат към редуктора. Partitioner също контролира разделянето на ключовете на междинните изходи на картата.
Споменете различни дистрибуции на Hadoop, специфични за доставчика.
Отговор: Различните доставчици, които разширяват възможностите на Hadoop, включват:
- IBM Open платформа.
- Cloudera CDH Hadoop разпространение
- MapR Hadoop разпространение
- Amazon Elastic MapReduce
- Платформа за данни Hortonworks (HDP)
- Основен пакет с големи данни
- Datastax Enterprise Analytics
- HDInsight на Microsoft Azure – базирано на облак Hadoop разпространение.
Защо HDFS е устойчив на грешки?
Отговор: HDFS репликира данни на различни DataNodes, което го прави устойчив на грешки. Съхраняването на данните в различни възли позволява извличане от други възли, когато един режим се срине.
Правете разлика между федерация и висока наличност.
Отговор: HDFS Federation предлага толерантност към грешки, която позволява непрекъснат поток от данни в един възел, когато друг се срине. От друга страна, високата наличност ще изисква две отделни машини, конфигуриращи активния NameNode и вторичния NameNode на първата и втората машина поотделно.
Федерацията може да има неограничен брой несвързани NameNodes, докато при висока наличност са налични само два свързани NameNodes, активен и резервен, които работят непрекъснато.
NameNodes във федерацията споделят пул от метаданни, като всеки NameNode има свой специален пул. При High Availability обаче активните NameNodes се изпълняват всеки един по един, докато NameNodes в режим на готовност остават неактивни и актуализират своите метаданни само от време на време.
Как да намерите състоянието на блоковете и изправността на файловата система?
Отговор: Използвате командата hdfs fsck / както на ниво root потребител, така и на отделна директория, за да проверите изправното състояние на HDFS файловата система.
Използвана команда HDFS fsck:
hdfs fsck / -files --blocks –locations> dfs-fsck.log
Описание на командата:
- -files: Отпечатайте файловете, които проверявате.
- –locations: Отпечатва местоположенията на всички блокове, докато проверява.
Команда за проверка на състоянието на блоковете:
hdfs fsck <path> -files -blocks
: Започва проверките от предадения тук път. - – блокове: Отпечатва файловите блокове по време на проверка
Кога използвате командите rmadmin-refreshNodes и dfsadmin-refreshNodes?
Отговор: Тези две команди са полезни при опресняване на информацията за възела по време на пускане в експлоатация или когато пускането в експлоатация на възела е завършено.
Командата dfsadmin-refreshNodes изпълнява HDFS клиента и опреснява конфигурацията на възела на NameNode. Командата rmadmin-refreshNodes, от друга страна, изпълнява административните задачи на ResourceManager.
Какво е контролен пункт?
Отговор: Контролна точка е операция, която обединява последните промени на файловата система с най-новия FSImage, така че регистрационните файлове за редактиране да останат достатъчно малки, за да ускорят процеса на стартиране на NameNode. Контролната точка се появява във вторичния възел с имена.
Защо използваме HDFS за приложения с големи набори от данни?
Отговор: HDFS предоставя DataNode и NameNode архитектура, която имплементира разпределена файлова система.
Тези две архитектури осигуряват високоефективен достъп до данни през силно мащабируеми клъстери на Hadoop. Неговият NameNode съхранява метаданните на файловата система в RAM, което води до количеството памет, ограничаващо броя на файловете на HDFS файловата система.
Какво прави командата ‘jps’?
Отговор: Командата Java Virtual Machine Process Status (JPS) проверява дали конкретни Hadoop демони, включително NodeManager, DataNode, NameNode и ResourceManager, работят или не. Тази команда е необходима за изпълнение от корена, за да провери работните възли в хоста.
Какво е „Спекулативно изпълнение“ в Hadoop?
Отговор: Това е процес, при който главният възел в Hadoop, вместо да коригира открити бавни задачи, стартира различен екземпляр на същата задача като резервна задача (спекулативна задача) на друг възел. Спекулативното изпълнение спестява много време, особено в среда с интензивно работно натоварване.
Назовете трите режима, в които Hadoop може да работи.
Отговор: Трите основни възела, на които работи Hadoop, включват:
- Самостоятелният възел е режимът по подразбиране, който изпълнява услугите на Hadoop, използвайки локалната файлова система и един Java процес.
- Псевдо-разпределеният възел изпълнява всички услуги на Hadoop, като използва едно внедряване на Hadoop.
- Напълно разпределеният възел изпълнява главни и подчинени услуги на Hadoop, използвайки отделни възли.
Какво е СДС?
Отговор: UDF (дефинирани от потребителя функции) ви позволява да кодирате вашите персонализирани функции, които можете да използвате за обработка на стойности на колони по време на заявка на Impala.
Какво е DistCp?
Отговор: DistCp или Distributed Copy, накратко, е полезен инструмент за голямо вътрешно или вътрешно клъстерно копиране на данни. Използвайки MapReduce, DistCp ефективно прилага разпределеното копие на голямо количество данни, наред с други задачи като обработка на грешки, възстановяване и докладване.
Отговор: Hive metastore е услуга, която съхранява метаданни на Apache Hive за таблиците на Hive в релационна база данни като MySQL. Той предоставя API на услугата metastore, която позволява центов достъп до метаданните.
Определете RDD.
Отговор: RDD, което означава Resilient Distributed Datasets, е структурата на данните на Spark и неизменна разпределена колекция от вашите елементи от данни, която изчислява на различните клъстерни възли.
Как местните библиотеки могат да бъдат включени в YARN Jobs?
Отговор: Можете да приложите това или чрез -Djava.library. опция за път в командата или като зададете LD+LIBRARY_PATH в .bashrc файл, като използвате следния формат:
<property> <name>mapreduce.map.env</name> <value>LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/my/libs</value> </property>
Обяснете „WAL“ в HBase.
Отговор: Write Ahead Log (WAL) е протокол за възстановяване, който записва промените в данните на MemStore в HBase във файлово-базирано хранилище. WAL възстановява тези данни, ако RegionalServer се срине или преди да изчисти MemStore.
Дали YARN е заместител на Hadoop MapReduce?
Отговор: Не, YARN не е заместител на Hadoop MapReduce. Вместо това мощна технология, наречена Hadoop 2.0 или MapReduce 2, поддържа MapReduce.
Каква е разликата между ORDER BY и SORT BY в HIVE?
Отговор: Докато и двете команди извличат данни по сортиран начин в Hive, резултатите от използването на SORT BY може да бъдат подредени само частично.
Освен това SORT BY изисква редуктор за подреждане на редовете. Тези редуктори, необходими за крайния резултат, също могат да бъдат множество. В този случай крайният резултат може да бъде частично подреден.
От друга страна, ORDER BY изисква само един редуктор за общ ред в изхода. Можете също да използвате ключовата дума LIMIT, която намалява общото време за сортиране.
Каква е разликата между Spark и Hadoop?
Отговор: Въпреки че и Hadoop, и Spark са рамки за разпределена обработка, ключовата им разлика е тяхната обработка. Когато Hadoop е ефективен за пакетна обработка, Spark е ефективен за обработка на данни в реално време.
Освен това Hadoop основно чете и записва файлове в HDFS, докато Spark използва концепцията Resilient Distributed Dataset за обработка на данни в RAM.
Въз основа на тяхната латентност, Hadoop е изчислителна рамка с висока латентност без интерактивен режим за обработка на данни, докато Spark е изчислителна рамка с ниска латентност, която обработва данни интерактивно.
Сравнете Sqoop и Flume.
Отговор: Sqoop и Flume са Hadoop инструменти, които събират данни, събрани от различни източници и зареждат данните в HDFS.
- Sqoop (SQL-to-Hadoop) извлича структурирани данни от бази данни, включително Teradata, MySQL, Oracle и др., докато Flume е полезен за извличане на неструктурирани данни от източници на бази данни и зареждането им в HDFS.
- По отношение на задвижвани събития, Flume се управлява от събития, докато Sqoop не се задвижва от събития.
- Sqoop използва архитектура, базирана на конектори, където конекторите знаят как да се свържат с различен източник на данни. Flume използва архитектура, базирана на агенти, като написаният код е агентът, който отговаря за извличането на данните.
- Поради разпределения характер на Flume, той може лесно да събира и обобщава данни. Sqoop е полезен за паралелен трансфер на данни, което води до това, че изходът е в множество файлове.
Обяснете BloomMapFile.
Отговор: BloomMapFile е клас, разширяващ класа MapFile и използва динамични филтри за разцвет, които предоставят бърз тест за членство за ключове.
Избройте разликите между HiveQL и PigLatin.
Отговор: Докато HiveQL е декларативен език, подобен на SQL, PigLatin е процедурен език за поток от данни на високо ниво.
Какво е почистване на данни?
Отговор: Почистването на данни е ключов процес за премахване или коригиране на идентифицирани грешки в данните, които включват неправилни, непълни, повредени, дублирани и неправилно форматирани данни в набор от данни.
Този процес има за цел да подобри качеството на данните и да предостави по-точна, последователна и надеждна информация, необходима за ефективно вземане на решения в организацията.
Заключение💃
С текущото нарастване на възможностите за работа в Big data и Hadoop може да искате да подобрите шансовете си да влезете. Въпросите и отговорите за интервю с Hadoop в тази статия ще ви помогнат да се справите с това предстоящо интервю.
След това можете да разгледате добри ресурси, за да научите Big Data и Hadoop.
Най-добър късмет! 👍