

Уеб скрапингът е идеята за извличане на информация от уебсайт и използването й за конкретен случай на употреба.
Да приемем, че се опитвате да извлечете таблица от уеб страница, да я конвертирате в JSON файл и да използвате JSON файла за изграждане на някои вътрешни инструменти. С помощта на уеб скрапинг можете да извлечете данните, които искате, като насочите конкретни елементи в уеб страница. Уеб скрапирането с помощта на Python е много популярен избор, тъй като Python предоставя множество библиотеки като BeautifulSoup или Scrapy за ефективно извличане на данни.
Притежаването на умение за ефективно извличане на данни също е много важно като разработчик или специалист по данни. Тази статия ще ви помогне да разберете как ефективно да скрейпвате уебсайт и да получите необходимото съдържание, за да го манипулирате според вашите нужди. За този урок ще използваме пакета BeautifulSoup. Това е модерен пакет за изчерпване на данни в Python.
Съдържание
Защо да използвате Python за уеб скрапинг?
Python е първият избор за много разработчици, когато създават уеб скрапери. Има много причини, поради които Python е първият избор, но за тази статия нека обсъдим три основни причини, поради които Python се използва за извличане на данни.
Поддръжка на библиотека и общност: Има няколко страхотни библиотеки, като BeautifulSoup, Scrapy, Selenium и др., които предоставят страхотни функции за ефективно изтриване на уеб страници. Той е изградил отлична екосистема за уеб скрапинг, а също и тъй като много разработчици по света вече използват Python, можете бързо да получите помощ, когато сте блокирани.
Автоматизация: Python е известен със своите възможности за автоматизация. Изисква се нещо повече от уеб скрапинг, ако се опитвате да направите сложен инструмент, който разчита на скрапинг. Например, ако искате да изградите инструмент, който проследява цената на артикулите в онлайн магазин, ще трябва да добавите някои възможности за автоматизация, така че да може да проследява курсовете ежедневно и да ги добавя към вашата база данни. Python ви дава възможност да автоматизирате такива процеси с лекота.
Визуализация на данни: Уеб скрапингът се използва широко от специалистите по данни. Учените по данни често трябва да извличат данни от уеб страници. С библиотеки като Pandas, Python прави визуализацията на данни по-лесна от необработени данни.
Библиотеки за уеб скрапинг в Python
Има няколко налични библиотеки в Python за по-лесно извличане на уеб. Нека обсъдим трите най-популярни библиотеки тук.
#1. Красива супа
Една от най-популярните библиотеки за уеб скрапинг. BeautifulSoup помага на разработчиците да скрейпват уеб страници от 2004 г. насам. Предоставя прости методи за навигация, търсене и модифициране на дървото за анализ. Самата Beautifulsoup също прави кодирането за входящи и изходящи данни. Той е добре поддържан и има страхотна общност.
#2. Скрепи
Друга популярна рамка за извличане на данни. Scrapy има повече от 43 000 звезди в GitHub. Може да се използва и за изчерпване на данни от API. Освен това има няколко интересни вградени поддръжка, като изпращане на имейли.
#3. Селен
Selenium не е предимно библиотека за уеб скрапиране. Вместо това, това е пакет за автоматизация на браузъра. Но можем лесно да разширим функционалностите му за копиране на уеб страници. Той използва протокола WebDriver за управление на различни браузъри. Селенът е на пазара вече почти 20 години. Но с помощта на Selenium можете лесно да автоматизирате и изтривате данни от уеб страници.
Предизвикателства с Python Web Scraping
Човек може да се изправи пред много предизвикателства, когато се опитва да изтрие данни от уебсайтове. Има проблеми като бавни мрежи, инструменти против изтриване, блокиране на базата на IP, блокиране на captcha и т.н. Тези проблеми могат да причинят огромни проблеми при опит за изтриване на уебсайт.
Но можете ефективно да заобиколите предизвикателствата, като следвате някои начини. Например, в повечето случаи IP адрес се блокира от уебсайт, когато има повече от определен брой заявки, изпратени в определен интервал от време. За да избегнете блокиране на IP, ще трябва да кодирате своя скрепер, така че да се охлажда след изпращане на заявки.

Разработчиците също са склонни да поставят капани за медени съдове за скрепери. Тези капани обикновено са невидими за голи човешки очи, но могат да бъдат пропълзени от скрепер. Ако скрейпвате уебсайт, който поставя такъв капан на honeypot, ще трябва да кодирате съответно своя скрепер.
Captcha е друг сериозен проблем със скреперите. Повечето уебсайтове в днешно време използват captcha, за да защитят достъпа на бот до техните страници. В такъв случай може да се наложи да използвате програма за решаване на captcha.
Изтриване на уебсайт с Python
Както обсъдихме, ще използваме BeautifulSoup, за да бракуваме уебсайт. В този урок ще вземем историческите данни на Ethereum от Coingecko и ще запазим данните от таблицата като JSON файл. Нека да преминем към изграждането на скрепера.
Първата стъпка е да инсталирате BeautifulSoup и Requests. За този урок ще използвам Pipenv. Pipenv е мениджър на виртуална среда за Python. Можете също да използвате Venv, ако искате, но аз предпочитам Pipenv. Обсъждането на Pipenv е извън обхвата на този урок. Но ако искате да научите как може да се използва Pipenv, следвайте това ръководство. Или, ако искате да разберете виртуалните среди на Python, следвайте това ръководство.
Стартирайте обвивката Pipenv в директорията на вашия проект, като изпълните командата pipenv shell. Той ще стартира подобвивка във вашата виртуална среда. Сега, за да инсталирате BeautifulSoup, изпълнете следната команда:
pipenv install beautifulsoup4
И за инсталиране на заявки изпълнете командата, подобна на горната:
pipenv install requests
След като инсталацията приключи, импортирайте необходимите пакети в основния файл. Създайте файл с име main.py и импортирайте пакетите, както е показано по-долу:
from bs4 import BeautifulSoup import requests import json
Следващата стъпка е да получите съдържанието на страницата с исторически данни и да ги анализирате с помощта на HTML анализатора, наличен в BeautifulSoup.
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel')
soup = BeautifulSoup(r.content, 'html.parser')
В горния код страницата е достъпна чрез метода get, наличен в библиотеката със заявки. След това анализираното съдържание се съхранява в променлива, наречена супа.
Оригиналната част за изстъргване започва сега. Първо, ще трябва да идентифицирате правилно таблицата в DOM. Ако отворите тази страница и я прегледате с помощта на инструментите за разработчици, налични в браузъра, ще видите, че таблицата има тези класове table table-striped text-sm text-lg-normal.
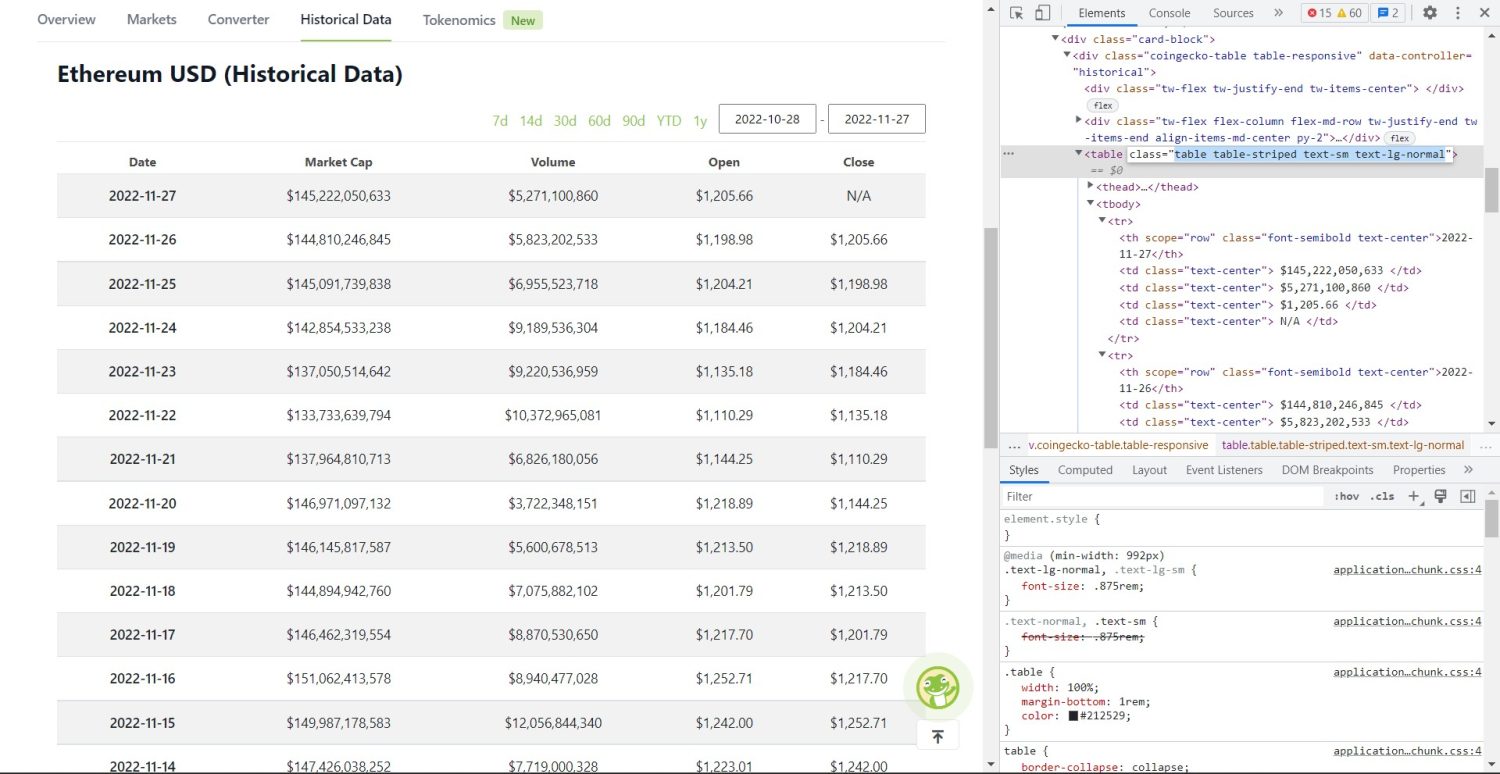 Таблица с исторически данни на Coingecko Ethereum
Таблица с исторически данни на Coingecko Ethereum
За да насочите правилно тази таблица, можете да използвате метода за намиране.
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'})
table_data = table.find_all('tr')
table_headings = []
for th in table_data[0].find_all('th'):
table_headings.append(th.text)
В горния код първо таблицата се намира с помощта на метода soup.find, след което с помощта на метода find_all се търсят всички tr елементи в таблицата. Тези tr елементи се съхраняват в променлива, наречена table_data. Таблицата има няколко елемента за заглавие. Нова променлива, наречена table_headings, се инициализира за запазване на заглавията в списък.
След това се изпълнява for цикъл за първия ред на таблицата. В този ред се търсят всички елементи с th и тяхната текстова стойност се добавя към списъка table_headings. Текстът се извлича чрез текстовия метод. Ако отпечатате променливата table_headings сега, ще можете да видите следния резултат:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']
Следващата стъпка е да изтриете останалите елементи, да генерирате речник за всеки ред и след това да добавите редовете в списък.
for tr in table_data:
th = tr.find_all('th')
td = tr.find_all('td')
data = {}
for i in range(len(td)):
data.update({table_headings[0]: th[0].text})
data.update({table_headings[i+1]: td[i].text.replace('n', '')})
if data.__len__() > 0:
table_details.append(data)
Това е съществената част от кода. За всеки tr в променливата table_data първо се търсят th-ите елементи. Елементите са датата, показана в таблицата. Тези th елементи се съхраняват в променлива th. По същия начин всички td елементи се съхраняват в променливата td.
Инициализира се празен речник. След инициализацията преминаваме през диапазона от td елементи. За всеки ред, първо, актуализираме първото поле на речника с първия елемент от th. Кодовата table_headings[0]: ти[0].text присвоява двойка ключ-стойност от дата и първия елемент.
След инициализиране на първия елемент, останалите елементи се присвояват с помощта на data.update({table_headings[i+1]: td[i].text.replace(‘n’, ”)}). Тук текстът на td елементите първо се извлича с помощта на метода text и след това всички n се заменят с помощта на метода replace. След това стойността се присвоява на i+1-ия елемент от списъка table_headings, тъй като i-тият елемент вече е присвоен.
След това, ако дължината на речника на данните надвишава нула, ние добавяме речника към списъка table_details. Можете да отпечатате списъка table_details, за да проверите. Но ние ще запишем стойностите в JSON файл. Нека да разгледаме кода за това,
with open('table.json', 'w') as f:
json.dump(table_details, f, indent=2)
print('Data saved to json file...')
Тук използваме метода json.dump, за да запишем стойностите в JSON файл, наречен table.json. След като записът приключи, ние отпечатваме Data saved to json файл… в конзолата.
Сега стартирайте файла, като използвате следната команда,
python run main.py
След известно време ще можете да видите текста Data saved to JSON file… в конзолата. Ще видите също нов файл, наречен table.json, в директорията на работните файлове. Файлът ще изглежда подобно на следния JSON файл:
[
{
"Date": "2022-11-27",
"Market Cap": "$145,222,050,633",
"Volume": "$5,271,100,860",
"Open": "$1,205.66",
"Close": "N/A"
},
{
"Date": "2022-11-26",
"Market Cap": "$144,810,246,845",
"Volume": "$5,823,202,533",
"Open": "$1,198.98",
"Close": "$1,205.66"
},
{
"Date": "2022-11-25",
"Market Cap": "$145,091,739,838",
"Volume": "$6,955,523,718",
"Open": "$1,204.21",
"Close": "$1,198.98"
},
// ...
// ...
]
Успешно внедрихте уеб скрепер с помощта на Python. За да видите пълния код, можете да посетите това репо на GitHub.
Заключение
В тази статия се обсъжда как можете да приложите просто изстъргване на Python. Обсъдихме как BeautifulSoup може да се използва за бързо извличане на данни от уебсайта. Обсъдихме и други налични библиотеки и защо Python е първият избор за много разработчици за сканиране на уебсайтове.
Можете също така да разгледате тези рамки за уеб скрапиране.