
Apache Kafka и RabbitMQ са два широко използвани брокера за съобщения, които позволяват отделянето на обмена на съобщения между приложенията. Кои са най-важните им характеристики и какво ги прави различни един от друг? Да преминем към понятията.
Съдържание
RabbitMQ
RabbitMQ е приложение за брокер на съобщения с отворен код за комуникация и обмен на съобщения между страните. Тъй като е разработен в Erlang, той е много лек и ефективен. Езикът Erlang е разработен от Ericson с фокус върху разпределените системи.
Смята се за по-традиционен брокер за съобщения. Базира се на модела издател-абонат, въпреки че може да третира комуникацията синхронно или асинхронно, в зависимост от това какво е зададено в конфигурацията. Той също така осигурява доставката и поръчката на съобщения между производителите и потребителите.
Поддържа протоколи AMQP, STOMP, MQTT, HTTP и уеб сокет. Три модела за обмен на съобщения: тема, fanout и директен:
- Директен и индивидуален обмен по тема или тема [topic]
- Всички потребители, свързани към опашката, получават [fanout] съобщение
- Всеки потребител получава изпратено съобщение [direct]
Следните са компонентите на RabbitMQ:
производители
Производителите са приложения, които създават и изпращат съобщения до RabbitMQ. Те могат да бъдат всяко приложение, което може да се свърже с RabbitMQ и да публикува съобщения.
Потребители
Потребителите са приложения, които получават и обработват съобщения от RabbitMQ. Те могат да бъдат всяко приложение, което може да се свърже с RabbitMQ и да се абонира за съобщения.
Борси
Борсите отговарят за получаването на съобщения от производителите и насочването им към съответните опашки. Има няколко вида обмен, включително директен обмен, обмен на разклонения, обмен на теми и заглавки, всеки със собствени правила за маршрутизиране.
Опашки
Опашките са мястото, където се съхраняват съобщенията, докато не бъдат консумирани от потребителите. Те се създават от приложения или автоматично от RabbitMQ, когато съобщение е публикувано в обмен.
Подвързии
Обвързванията определят връзката между борси и опашки. Те определят правилата за маршрутизиране на съобщенията, които се използват от борсите за маршрутизиране на съобщения до съответните опашки.
Архитектура на RabbitMQ
RabbitMQ използва модел на изтегляне за доставка на съобщения. При този модел потребителите активно изискват съобщенията на брокера. Съобщенията се публикуват на борси, отговорни за маршрутизирането на съобщения до съответните опашки въз основа на ключове за маршрутизиране.
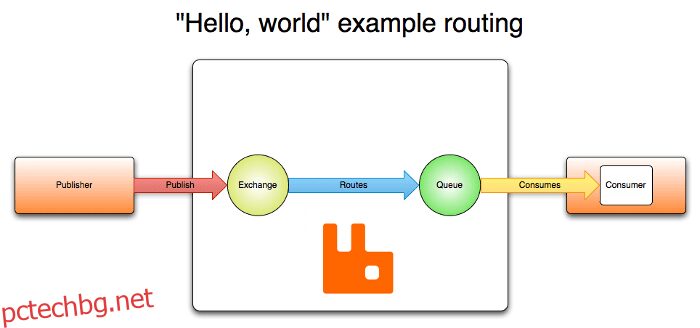
Архитектурата на RabbitMQ се основава на клиент-сървър архитектура и се състои от няколко компонента, които работят заедно, за да осигурят надеждна и мащабируема платформа за съобщения. Концепцията AMQP предвижда компонентите Exchanges, Queues, Bindings, както и Publishers и Subscribers. Издателите публикуват съобщения на борси.
Борсите приемат тези съобщения и ги разпределят в 0 до n опашки въз основа на определени правила (обвързвания). След това съобщенията, съхранени в опашките, могат да бъдат извлечени от потребителите. В опростена форма управлението на съобщения се извършва в RabbitMQ, както следва:
 Източник на изображението: VMware
Източник на изображението: VMware
- Издателите изпращат съобщения за обмен;
- Exchange изпраща съобщения до опашки и други обмени;
- Когато се получи съобщение, RabbitMQ изпраща потвърждения на подателите;
- Потребителите поддържат постоянни TCP връзки към RabbitMQ и декларират коя опашка получават;
- RabbitMQ насочва съобщения към потребителите;
- Потребителите изпращат потвърждения за успех или грешка за получаване на съобщението;
- При успешно получаване съобщението се премахва от опашката.
Апаш Кафка
Apache Kafka е разпределено решение за съобщения с отворен код, разработено от LinkedIn в Scala. Той е в състояние да обработва съобщения и да ги съхранява с модел издател-абонат с висока мащабируемост и производителност.

За да съхранявате получените събития или съобщения, разпределете темите между възлите, като използвате дялове. Той съчетава както модели на издател-абонат, така и модели на опашка от съобщения и също така отговаря за осигуряването на реда на съобщенията за всеки потребител.
Kafka е специализирана във висока пропускателна способност на данни и ниска латентност за обработка на потоци от данни в реално време. Това се постига чрез избягване на твърде много логика от страна на сървъра (брокера), както и някои специални подробности за изпълнението.
Например Kafka изобщо не използва RAM и записва данни веднага във файловата система на сървъра. Тъй като всички данни се записват последователно, се постига производителност при четене и запис, която е сравнима с тази на RAM.
Това са основните концепции на Kafka, които я правят мащабируема, производителна и устойчива на грешки:
Тема
Темата е начин за етикетиране или категоризиране на съобщение; представете си килер с 10 чекмеджета; всяко чекмедже може да бъде тема, а килерът е платформата Apache Kafka, така че в допълнение към категоризирането на групираните съобщения, друга по-добра аналогия за темата би била поставена в релационни бази данни.
Продуцент
Продуцентът или продуцентът е този, който се свързва с платформа за съобщения и изпраща едно или повече съобщения по конкретна тема.
Консуматор
Потребителят е човекът, който се свързва с платформа за съобщения и приема едно или повече съобщения на конкретна тема.
Брокер
Концепцията за брокер в платформата Kafka не е нищо повече от практически самият Kafka и той е този, който управлява темите и определя начина на съхранение на съобщения, логове и т.н.
Клъстер
Клъстерът е набор от брокери, които комуникират помежду си или не за по-добра мащабируемост и толерантност към грешки.
Лог файл
Всяка тема съхранява своите записи във формат на журнал, тоест по структуриран и последователен начин; следователно регистрационният файл е файлът, който съдържа информацията за дадена тема.
Прегради
Разделите са разделителният слой на съобщенията в дадена тема; това разделяне гарантира еластичността, устойчивостта на грешки и мащабируемостта на Apache Kafka, така че всяка тема може да има множество дялове на различни места.
Архитектурата на Апач Кафка
Kafka се основава на push модел за доставка на съобщения. Използвайки този модел, съобщенията в Kafka се изпращат активно до потребителите. Съобщенията се публикуват в теми, които се разделят и разпределят между различни брокери в клъстера.
След това потребителите могат да се абонират за една или повече теми и да получават съобщения, когато се създават по тези теми.
В Кафка всяка тема е разделена на един или повече дяла. Именно в раздела завършват събитията.
Ако в клъстера има повече от един брокер, тогава дяловете ще бъдат разпределени равномерно между всички брокери (доколкото е възможно), което ще позволи мащабиране на натоварването при писане и четене в една тема към няколко брокера наведнъж. Тъй като е клъстер, той работи с помощта на ZooKeeper за синхронизация.
Получава магазини и разпространява записи. Записът е данни, генерирани от някакъв системен възел, който може да бъде събитие или информация. Изпраща се до клъстера и клъстерът го съхранява в раздел на тема.
Всеки запис има отместване на последователност и потребителят може да контролира отместването, което консумира. По този начин, ако има нужда от повторна обработка на темата, това може да се направи въз основа на отместването.
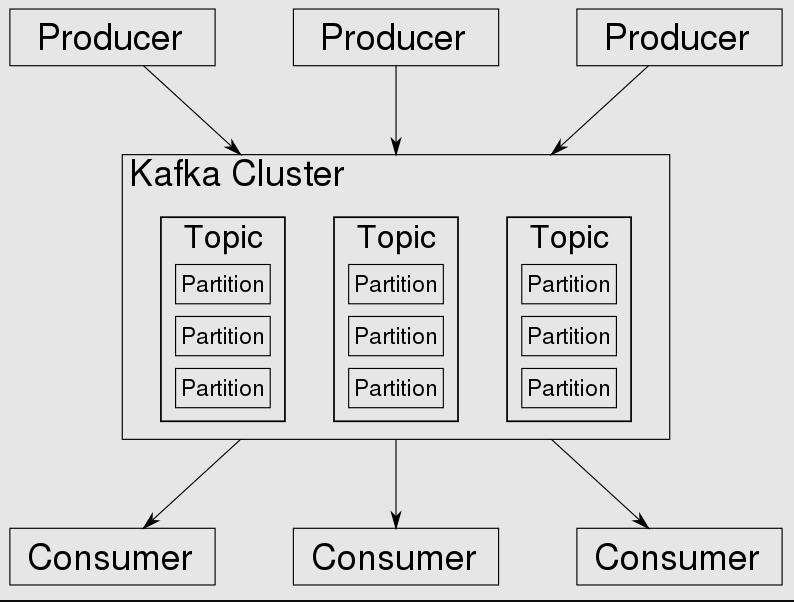 Източник на изображението: Wikipedia
Източник на изображението: Wikipedia
Логиката, като например управлението на ID на последното прочетено съобщение на потребител или решението за това в кой дял се записват новопостъпилите данни, е изцяло прехвърлено към клиента (производител или потребител).
В допълнение към понятията за производител и потребител, съществуват и понятията за тема, разделяне и репликация.
Темата описва категория съобщения. Kafka постига толерантност към грешки чрез репликиране на данните в тема и мащабиране чрез разделяне на темата между множество сървъри.
RabbitMQ срещу Kafka
Основните разлики между Apache Kafka и RabbitMQ се дължат на фундаментално различни модели за доставка на съобщения, внедрени в тези системи.
По-специално, Apache Kafka работи на принципа на издърпване (издърпване), когато потребителите сами получават съобщенията, от които се нуждаят от темата.
RabbitMQ, от друга страна, прилага push модела, като изпраща необходимите съобщения до получателите. Като такъв Kafka се различава от RabbitMQ по следните начини:
#1. Архитектура
Една от най-големите разлики между RabbitMQ и Kafka е разликата в архитектурата. RabbitMQ използва традиционна архитектура на опашка от съобщения, базирана на брокер, докато Kafka използва архитектура на разпределена стрийминг платформа.
Освен това RabbitMQ използва модел за доставка на съобщения, базиран на изтегляне, докато Kafka използва модел, базиран на натискане.
#2. Запазване на съобщения
RabbitMQ поставя съобщението в опашката FIFO (First Input – First Output) и следи статуса на това съобщение в опашката, а Kafka добавя съобщението към дневника (записва на диска), оставяйки получателя да се погрижи за получаването на необходимите информация от темата.
RabbitMQ изтрива съобщението, след като е било доставено на получателя, докато Kafka съхранява съобщението, докато не бъде планирано да изчисти дневника.
Така Kafka запазва текущото и всички предишни състояния на системата и може да се използва като надежден източник на исторически данни, за разлика от RabbitMQ.
#3. Балансиране на натоварването
Благодарение на модела на изтегляне за доставка на съобщения, RabbitMQ намалява латентността. Въпреки това е възможно получателите да препълнят, ако съобщенията пристигнат на опашката по-бързо, отколкото могат да ги обработят.
Тъй като в RabbitMQ всеки получател иска/качва различен брой съобщения, разпределението на работата може да стане неравномерно, което ще доведе до забавяне и загуба на реда на съобщенията по време на обработката.
За да предотврати това, всеки RabbitMQ приемник конфигурира лимит за предварително извличане, лимит за броя на натрупаните непотвърдени съобщения. В Kafka балансирането на натоварването се извършва автоматично чрез преразпределяне на получателите между раздели (дял) на темата.
#4. Маршрутизиране
RabbitMQ включва четири начина за насочване към различни борси за опашка, което позволява мощен и гъвкав набор от модели за съобщения. Kafka прилага само един начин за запис на съобщения на диск без маршрутизиране.
#5. Подреждане на съобщения
RabbitMQ ви позволява да поддържате относителен ред в произволни набори (групи) от събития, а Apache Kafka предоставя лесен начин за поддържане на подреждане с мащабируемост чрез писане на съобщения последователно в репликиран журнал (тема).
FeatureRabbitMQKafka ArchitectureЗаписва съобщения на диск, прикачен към брокераРазпределена платформа за стрийминг АрхитектураМодел на доставка Pull-базиранPush-базиранЗапазване на съобщенияНе може да записва съобщенияПоддържа поръчки чрез писане в темаБалансиране на натоварването Конфигурира лимит за предварително извличанеИзвършва се автоматично МаршрутизиранеВключва 4 начина за маршрутизиранеИма само 1 начин за маршрутизиране на съобщения Съобщение ПодрежданеПозволява записи за поддържане на поръчки в групи от Основни към темата Външни процеси Не изисква Изисква стартиране на екземпляр на Zookeeper Приставки Няколко приставки Има ограничена поддръжка на приставки
RabbitMQ и Kafka са широко използвани системи за съобщения, всяка със своите силни страни и случаи на употреба. RabbitMQ е гъвкава, надеждна и мащабируема система за съобщения, която се отличава с опашка за съобщения, което я прави идеален избор за приложения, които изискват надеждна и гъвкава доставка на съобщения.
От друга страна, Kafka е разпределена стрийминг платформа, която е предназначена за високопроизводителна обработка в реално време на големи обеми данни, което я прави чудесен избор за приложения, които изискват обработка и анализ на данни в реално време.
Основни случаи на използване на RabbitMQ:
Е-търговия

RabbitMQ се използва в приложения за електронна търговия за управление на потока от данни между различни системи, като управление на инвентара, обработка на поръчки и обработка на плащания. Той може да обработва големи обеми съобщения и да гарантира, че те се доставят надеждно и в правилния ред.
Здравеопазване
В здравната индустрия RabbitMQ се използва за обмен на данни между различни системи, като електронни здравни досиета (EHR), медицински устройства и системи за подпомагане на клинични решения. Може да помогне за подобряване на грижите за пациентите и намаляване на грешките, като гарантира, че правилната информация е налична в точното време.
Финансови услуги
RabbitMQ позволява обмен на съобщения в реално време между системи, като платформи за търговия, системи за управление на риска и шлюзове за плащане. Може да помогне да се гарантира, че транзакциите се обработват бързо и сигурно.
IoT системи
RabbitMQ се използва в IoT системи за управление на потока от данни между различни устройства и сензори. Може да помогне да се гарантира, че данните се доставят сигурно и ефективно, дори в среди с ограничена честотна лента и прекъсваща връзка.
Kafka е разпределена стрийминг платформа, предназначена да обработва големи обеми данни в реално време.
Основни случаи на използване на Kafka
Анализи в реално време

Kafka се използва в аналитични приложения в реално време за обработка и анализ на данни, докато се генерират, което позволява на бизнеса да взема решения въз основа на актуална информация. Той може да обработва големи обеми данни и да се мащабира, за да отговори на нуждите дори на най-взискателните приложения.
Агрегиране на регистрационни файлове
Kafka може да събира регистрационни файлове от различни системи и приложения, което позволява на бизнеса да наблюдава и отстранява проблеми в реално време. Може да се използва и за съхраняване на регистрационни файлове за дългосрочен анализ и докладване.
Машинно обучение
Kafka се използва в приложения за машинно обучение за поточно предаване на данни към модели в реално време, което позволява на бизнеса да прави прогнози и да предприема действия въз основа на актуална информация. Може да помогне за подобряване на точността и ефективността на моделите за машинно обучение.
Моето мнение както за RabbitMQ, така и за Kafka
Недостатъкът на широките и разнообразни възможности на RabbitMQ за гъвкаво управление на опашките със съобщения е увеличеното потребление на ресурси и съответно влошаване на производителността при повишени натоварвания. Тъй като това е режимът на работа за сложни системи, в повечето случаи Apache Kafka е най-добрият инструмент за управление на съобщения.
Например, в случай на събиране и агрегиране на много събития от десетки системи и услуги, като се вземат предвид тяхната гео-резервация, клиентски показатели, регистрационни файлове и анализи, с перспективата за увеличаване на източниците на информация, ще предпочета да използвам Kafka, обаче, ако сте в ситуация, в която просто се нуждаете от бързи съобщения, RabbitMQ ще свърши добре работата!
Можете също да прочетете как да инсталирате Apache Kafka в Windows и Linux.