
Научете всичко, което трябва да знаете за проучвателния анализ на данни, критичен процес, използван за откриване на тенденции и модели и обобщаване на набори от данни с помощта на статистически обобщения и графични представяния.
Като всеки проект, проектът за наука за данни е дълъг процес, който изисква време, добра организация и стриктно спазване на няколко стъпки. Проучвателният анализ на данни (EDA) е една от най-важните стъпки в този процес.
Затова в тази статия ще разгледаме накратко какво представлява проучвателният анализ на данни и как можете да го извършите с R!
Съдържание
Какво е проучвателен анализ на данни?
Проучвателният анализ на данни разглежда и изучава характеристиките на набор от данни, преди да бъде подаден към приложение, независимо дали е изключително бизнес, статистическо или машинно обучение.
Това обобщение на естеството на информацията и нейните основни особености обикновено се прави чрез визуални методи, като графични изображения и таблици. Практиката се провежда предварително именно за да се оцени потенциалът на тези данни, които ще получат по-комплексна обработка в бъдеще.
Следователно EDA позволява:
- Формулирайте хипотези за използването на тази информация;
- Разгледайте скритите детайли в структурата на данните;
- Идентифицирайте липсващи стойности, извънредни стойности или необичайно поведение;
- Открийте тенденциите и съответните променливи като цяло;
- Изхвърлете неуместни променливи или променливи, свързани с други;
- Определете формалното моделиране, което ще се използва.
Каква е разликата между описателен и проучвателен анализ на данни?
Има два вида анализ на данни, описателен анализ и проучвателен анализ на данни, които вървят ръка за ръка, въпреки че имат различни цели.
Докато първият се фокусира върху описание на поведението на променливи, например средна стойност, медиана, режим и т.н.
Проучвателният анализ има за цел да идентифицира връзките между променливите, да извлече предварителни прозрения и да насочи моделирането към най-често срещаните парадигми на машинно обучение: класификация, регресия и групиране.
Като цяло и двете могат да се занимават с графично представяне; обаче, само проучвателният анализ се стреми да донесе прозрения, които могат да бъдат предприети, т.е. прозрения, които провокират действия от страна на вземащия решение.
И накрая, докато проучвателният анализ на данни се стреми да решава проблеми и да предлага решения, които ще ръководят стъпките на моделиране, описателният анализ, както подсказва името му, цели само да създаде подробно описание на въпросния набор от данни.
Описателен анализПроучвателен анализ на данниАнализира поведениетоАнализира поведението и връзката Осигурява обобщение Води до спецификация и действия Организира данните в таблици и графикиОрганизира данните в таблици и графикиНяма значителна обяснителна силаИма значителна обяснителна сила
Някои случаи на практическа употреба на EDA
#1. Дигитален маркетинг
Дигиталният маркетинг еволюира от творчески процес в процес, управляван от данни. Маркетинговите организации използват проучвателен анализ на данни, за да определят резултатите от кампаниите или усилията и да насочват потребителските инвестиции и решения за насочване.
Демографските проучвания, сегментирането на клиентите и други техники позволяват на търговците да използват големи количества потребителски покупки, проучвания и панелни данни, за да разберат и комуникират стратегически маркетинг.
Уеб проучвателният анализ позволява на маркетолозите да събират информация на ниво сесия за взаимодействия на уебсайт. Google Analytics е пример за безплатен и популярен инструмент за анализ, използван от търговците за тази цел.
Проучвателните техники, често използвани в маркетинга, включват моделиране на маркетингов микс, анализи на ценообразуването и промоцията, оптимизиране на продажбите и проучвателен анализ на клиентите, например сегментиране.
#2. Проучвателен портфолио анализ
Често срещано приложение на проучвателния анализ на данни е проучвателният анализ на портфейла. Банка или кредитна агенция има колекция от сметки с различна стойност и риск.
Сметките може да се различават в зависимост от социалния статус на притежателя (богат, средна класа, беден и т.н.), географското местоположение, нетната стойност и много други фактори. Заемодателят трябва да балансира възвръщаемостта на заема с риска от неизпълнение за всеки заем. След това възниква въпросът как да се оцени портфолиото като цяло.
Най-нискорисковият заем може да е за много богати хора, но има много ограничен брой богати хора. От друга страна, много бедни хора могат да дават заеми, но с по-голям риск.
Решението за проучвателен анализ на данни може да комбинира анализ на времеви редове с много други проблеми, за да реши кога да заема пари на тези различни сегменти кредитополучатели или процентът на заемане. Лихвата се начислява на членовете на сегмент от портфолио за покриване на загуби между членовете на този сегмент.
#3. Проучвателен анализ на риска
Прогностичните модели в банкирането се разработват, за да осигурят сигурност относно оценките на риска за отделните клиенти. Кредитните рейтинги са предназначени да предскажат престъпното поведение на дадено лице и се използват широко за оценка на кредитоспособността на всеки кандидат.
В допълнение, анализът на риска се извършва в научния свят и застрахователната индустрия. Също така се използва широко във финансови институции като компании за портали за онлайн плащания, за да се анализира дали дадена транзакция е истинска или измамна.
За тази цел те използват историята на транзакциите на клиента. По-често се използва при покупки с кредитна карта; когато има внезапен скок в обема на клиентските транзакции, клиентът получава повикване за потвърждение, ако е инициирал транзакцията. Това също помага за намаляване на загубите поради такива обстоятелства.
Проучвателен анализ на данни с R
Първото нещо, което трябва да извършите EDA с R, е да изтеглите R base и R Studio (IDE), последвано от инсталиране и зареждане на следните пакети:
#Installing Packages
install.packages("dplyr")
install.packages("ggplot2")
install.packages("magrittr")
install.packages("tsibble")
install.packages("forecast")
install.packages("skimr")
#Loading Packages
library(dplyr)
library(ggplot2)
library(magrittr)
library(tsibble)
library(forecast)
library(skimr)
За този урок ще използваме набор от икономически данни, който е вграден с R и предоставя годишни данни за икономическите показатели на икономиката на САЩ и ще променим името му на econ за по-лесно:
econ <- ggplot2::economics
За да извършим описателния анализ, ще използваме пакета skimr, който изчислява тези статистики по прост и добре представен начин:
#Descriptive Analysis skimr::skim(econ)

Можете също да използвате функцията за обобщение за описателен анализ:
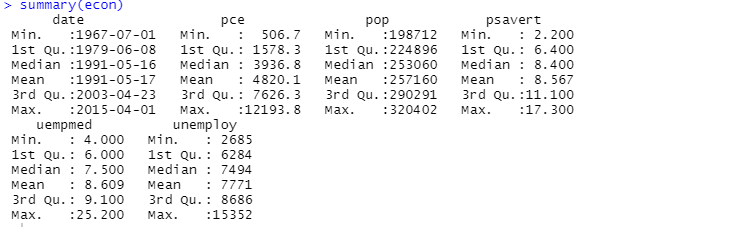
Тук описателният анализ показва 547 реда и 6 колони в набора от данни. Минималната стойност е за 1967-07-01, а максималната е за 2015-04-01. По същия начин той също показва средната стойност и стандартното отклонение.
Сега имате основна представа какво има вътре в набора от данни econ. Нека начертаем хистограма на променливата uempmed, за да разгледаме по-добре данните:
#Histogram of Unemployment econ %>% ggplot2::ggplot() + ggplot2::aes(x = uempmed) + ggplot2::geom_histogram() + labs(x = "Unemployment", title = "Monthly Unemployment Rate in US between 1967 to 2015")
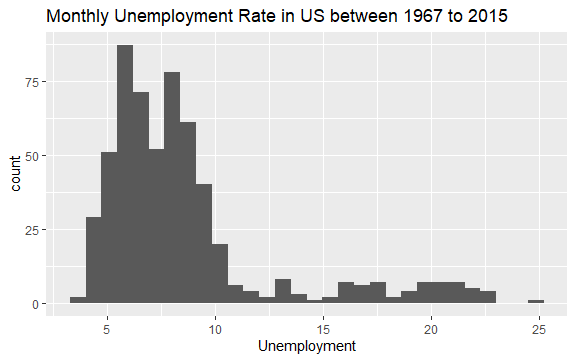
Разпределението на хистограмата показва, че тя има удължена опашка вдясно; това означава, че вероятно има няколко наблюдения на тази променлива с по-„екстремни“ стойности. Възниква въпросът: в какъв период са се случили тези стойности и каква е тенденцията на променливата?
Най-прекият начин за идентифициране на тенденцията на променлива е чрез линейна графика. По-долу генерираме линейна графика и добавяме изглаждаща линия:
#Line Graph of Unemployment econ %>% ggplot2::autoplot(uempmed) + ggplot2::geom_smooth()
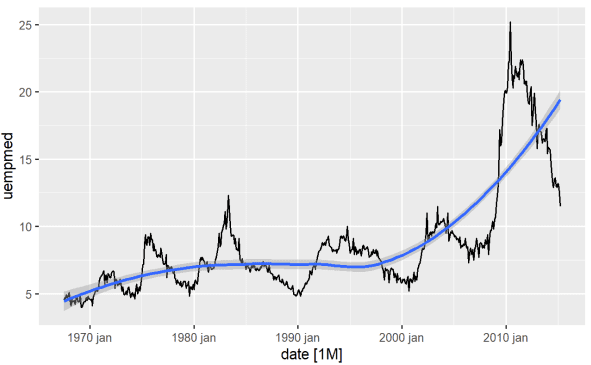
Използвайки тази графика, можем да установим, че в най-новия период, в последните наблюдения от 2010 г., има тенденция за нарастване на безработицата, надминавайки историята, наблюдавана през предходните десетилетия.
Друг важен момент, особено в контекста на иконометричното моделиране, е стационарността на серията; тоест средната стойност и дисперсията постоянни ли са във времето?
Когато тези предположения не са верни за дадена променлива, ние казваме, че серията има единичен корен (нестационарен), така че ударите, които променливата търпи, генерират постоянен ефект.
Изглежда, че случаят е бил такъв за въпросната променлива, продължителността на безработицата. Видяхме, че колебанията на променливата са се променили значително, което има силни последици, свързани с икономическите теории, които се занимават с цикли. Но, излизайки от теорията, как на практика да проверим дали променливата е стационарна?
Прогнозният пакет има отлична функция, позволяваща прилагането на тестове, като ADF, KPSS и други, които вече връщат броя на разликите, необходими за стационарността на серията:
#Using ADF test for checking stationarity forecast::ndiffs( x = econ$uempmed, test = "adf")

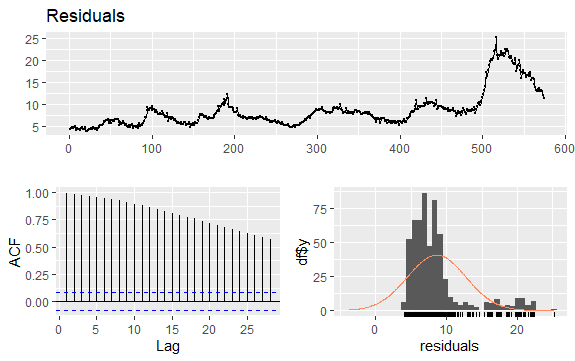
Тук p-стойността, по-голяма от 0,05, показва, че данните са нестационарни.
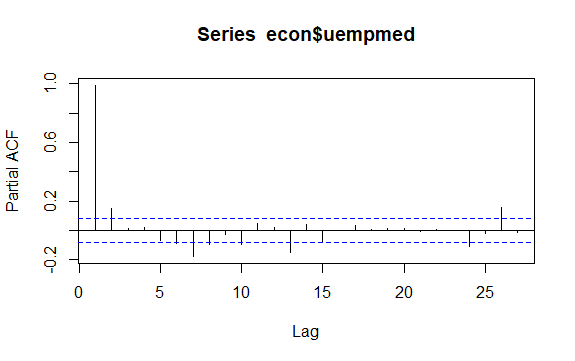
Друг важен въпрос при времевите редове е идентифицирането на възможните корелации (линейната връзка) между изостаналите стойности на серията. Корелограмите ACF и PACF помагат за идентифицирането му.
Тъй като серията няма сезонност, но има определена тенденция, първоначалните автокорелации са склонни да бъдат големи и положителни, тъй като близките във времето наблюдения също са близки по стойност.
По този начин автокорелационната функция (ACF) на времеви редове с тенденции има тенденция да има положителни стойности, които бавно намаляват с увеличаването на закъсненията.
#Residuals of Unemployment checkresiduals(econ$uempmed) pacf(econ$uempmed)
Заключение
Когато се докопаме до данни, които са повече или по-малко чисти, тоест вече почистени, веднага се изкушаваме да се потопим в етапа на изграждане на модела, за да извлечем първите резултати. Трябва да устоите на това изкушение и да започнете да правите проучвателен анализ на данни, който е прост, но ни помага да извлечем мощна представа за данните.
Можете също така да разгледате някои от най-добрите ресурси, за да научите статистика за Data Science.