

В днешния свят, управляван от данни, традиционният метод за ръчно събиране на данни е остарял. Компютър с интернет връзка на всяко бюро направи мрежата огромен източник на данни. По този начин по-ефективният и спестяващ време модерен метод за събиране на данни е уеб скрапирането. И когато става въпрос за уеб скрапинг, Python има инструмент, наречен Beautiful Soup. В тази публикация ще ви преведа през стъпките за инсталиране на Beautiful Soup, за да започнете с уеб скрапинг.
Преди да инсталирате и работите с Beautiful Soup, нека разберем защо трябва да го използвате.
Съдържание
Какво е красива супа?
Нека се престорим, че проучвате „Влиянието на COVID върху здравето на хората“ и сте открили няколко уеб страници, съдържащи подходящи данни. Но какво ще стане, ако те не ви предложат опция за изтегляне с едно кликване, за да заемете техните данни? Тук в игра влиза Красивата супа.
Beautiful Soup е сред индекса на библиотеките на Python за извличане на данни от целеви сайтове. По-удобно е извличането на данни от HTML или XML страници.
Леонард Ричардсън извади идеята за Beautiful Soup за изчистване на мрежата през 2004 г. Но неговият принос към проекта продължава и днес. Той с гордост актуализира всяко ново издание на Beautiful Soup в своя Twitter акаунт.
Въпреки че Beautiful Soup за уеб скрапинг е разработен с помощта на Python 3.8, той работи перфектно както с Python 3, така и с Python 2.4.
Често уебсайтовете използват captcha защита, за да спасят данните си от AI инструменти. В този случай няколко промени в заглавката „user-agent“ в Beautiful Soup или използването на API за разрешаване на Captcha може да имитират надежден браузър и да подмамят инструмента за откриване.
Ако обаче нямате време да изследвате Beautiful Soup или искате изчерпването да се извършва ефективно и лесно, тогава не бива да пропускате да разгледате този API за извличане на уеб сайтове, където можете просто да предоставите URL адрес и да получите данните твоите ръце.
Ако вече сте програмист, използването на Beautiful Soup за скрапинг няма да ви обезсърчи поради ясния му синтаксис при навигиране в уеб страници и извличане на желаните данни въз основа на условен анализ. В същото време е подходящ и за начинаещи.
Въпреки че Beautiful Soup не е за разширено сканиране, той работи най-добре, за да сканира данните от файлове, написани на езици за маркиране.
Ясната и подробна документация е още една важна точка, която Beautiful Soup прибра.
Нека намерим лесен начин да поставите красива супа във вашата машина.
Как да инсталирате Beautiful Soup за уеб скрапинг?
Pip – Лесен мениджър на пакети на Python, разработен през 2008 г., сега е стандартен инструмент сред разработчиците за инсталиране на всякакви библиотеки или зависимости на Python.
Pip идва по подразбиране с инсталирането на последните версии на Python. По този начин, ако имате скорошни версии на Python, инсталирани на вашата система, можете да започнете.
Отворете командния ред и въведете следната команда pip, за да инсталирате незабавно красивия Soup.
pip install beautifulsoup4
Ще видите нещо подобно на следната екранна снимка на вашия дисплей.
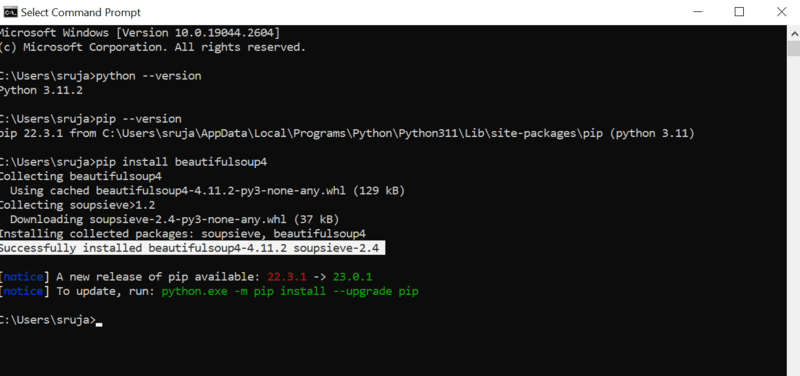
Уверете се, че сте актуализирали инсталатора на PIP до най-новата версия, за да избегнете често срещани грешки.
Командата за актуализиране на инсталатора на pip до най-новата версия е:
pip install --upgrade pip
Успешно покрихме половината място в тази публикация.
Сега имате инсталиран Beautiful Soup на вашата машина, така че нека се потопим в това как да го използвате за уеб скрапинг.
Как да импортирате и работите с Beautiful Soup за уеб скрапинг?
Въведете следната команда във вашия python IDE, за да импортирате красивия Soup в текущия скрипт на python.
from bs4 import BeautifulSoup
Сега Красивата супа е във вашия Python файл, за да го използвате за изстъргване.
Нека да разгледаме примерен код, за да научим как да извличаме желаните данни с красивия Soup.
Можем да кажем на beautiful Soup да търси конкретни HTML тагове в изходния уебсайт и да изтрие данните, налични в тези тагове.
В тази част ще използвам marketwatch.com, който актуализира цените на акциите в реално време на различни компании. Нека извлечем някои данни от този уебсайт, за да се запознаете с библиотеката Beautiful Soup.
Импортирайте пакета „заявки“, който ще ни позволи да получаваме и отговаряме на HTTP заявки и „urllib“ да зарежда уеб страницата от нейния URL адрес.
from urllib.request import urlopen import requests
Запазете връзката към уеб страницата в променлива, за да имате лесен достъп до нея по-късно.
url="https://www.marketwatch.com/investing/stock/amzn"
Следващото би било да използвате метода „urlopen“ от библиотеката „urllib“, за да съхраните HTML страницата в променлива. Предайте URL адреса на функцията „urlopen“ и запазете резултата в променлива.
page = urlopen(url)
Създайте обект Beautiful Soup и анализирайте желаната уеб страница с помощта на „html.parser“.
soup_obj = BeautifulSoup(page, 'html.parser')
Сега целият HTML скрипт на целевата уеб страница се съхранява в променливата ‘soup_obj’.
Преди да продължим, нека разгледаме изходния код на целевата страница, за да научим повече за HTML скрипта и таговете.
Щракнете с десния бутон на мишката навсякъде в уеб страницата. След това ще намерите опция за проверка, както е показано по-долу.
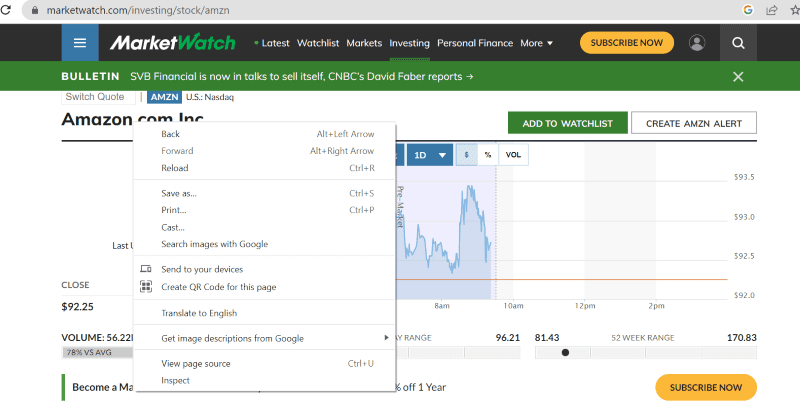
Кликнете върху проверка, за да видите изходния код.
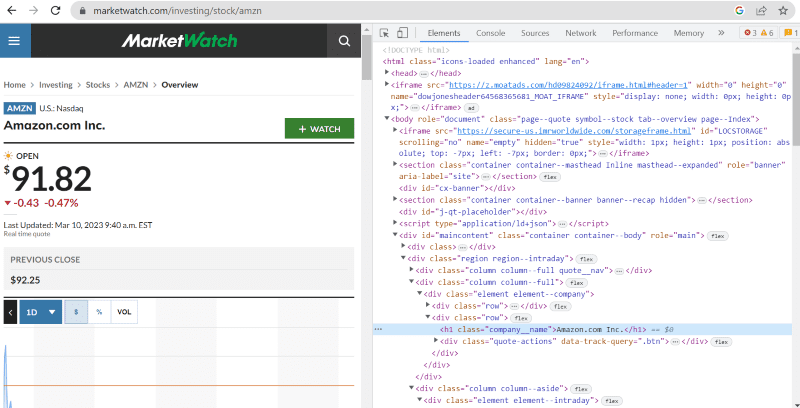
В горния изходен код можете да намерите тагове, класове и по-конкретна информация за всеки елемент, видим в интерфейса на уебсайта.
Методът „find“ в beautiful Soup ни позволява да търсим исканите HTML тагове и да извличаме данните. За да направим това, даваме името на класа и етикетите на метода, който извлича конкретни данни.
Например „Amazon.com Inc.“ показано на уеб страницата има името на класа: ‘company__name’ с етикет под ‘h1’. Можем да въведем тази информация в метода „find“, за да извлечем съответния HTML фрагмент в променлива.
name = soup_obj.find('h1', attrs={'class': 'company__name'})
Нека изведем HTML скрипта, съхранен в променливата “name” и необходимия текст на екрана.
print(name) print(name.text)

Можете да станете свидетели на извлечените данни, отпечатани на екрана.
Web Scrape уебсайта на IMDb
Много от нас търсят филмови оценки на сайта на IMBb, преди да гледат филм. Тази демонстрация ще ви даде списък с най-високо оценени филми и ще ви помогне да свикнете с красивата супа за уеб скрапинг.
Стъпка 1: Импортирайте красивите библиотеки Soup и заявки.
from bs4 import BeautifulSoup import requests
Стъпка 2: Нека присвоим URL адреса, който искаме да изтрием, на променлива, наречена „url“, за лесен достъп в кода.
Пакетът „заявки“ се използва за получаване на HTML страницата от URL адреса.
url = requests.get('https://www.imdb.com/search/title/?count=100&groups=top_1000&sort=user_rating')
Стъпка 3: В следващия кодов фрагмент ще анализираме HTML страницата на текущия URL адрес, за да създадем обект на красива супа.
soup_obj = BeautifulSoup(url.text, 'html.parser')
Променливата “soup_obj” сега съдържа целия HTML скрипт на желаната уеб страница, както е на следното изображение.
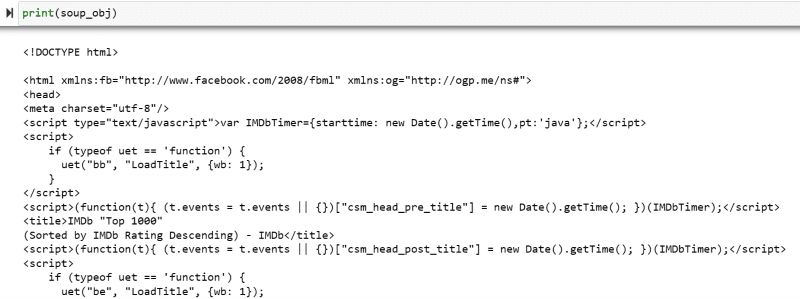
Нека проверим изходния код на уеб страницата, за да намерим HTML скрипта на данните, които искаме да изтрием.
Задръжте курсора върху елемента на уеб страницата, който искате да извлечете. След това щракнете с десния бутон върху него и отидете с опцията за проверка, за да видите изходния код на този конкретен елемент. Следните визуализации ще ви насочат по-добре.
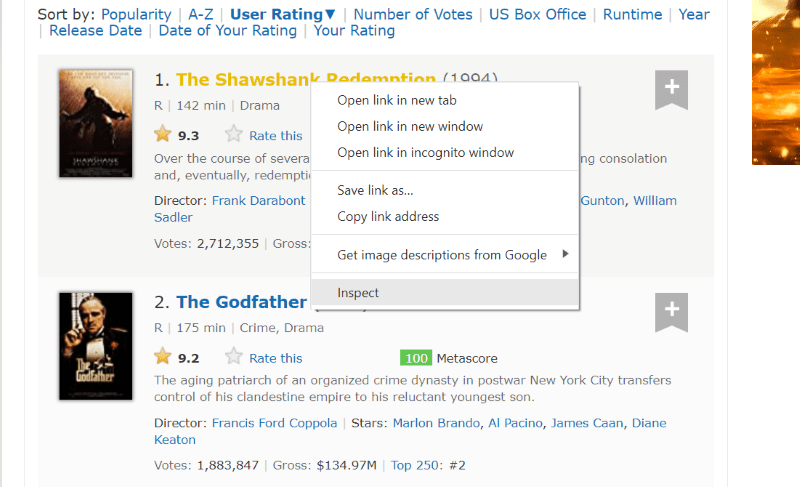
Класът „lister-list“ съдържа всички най-високо оценени данни, свързани с филми, като подразделения в последователни div тагове.
В HTML скрипта на всяка филмова карта, под класа „lister-item mode-advanced“, имаме етикет „h3“, който съхранява името на филма, ранга и годината на издаване, както е подчертано в изображението по-долу.
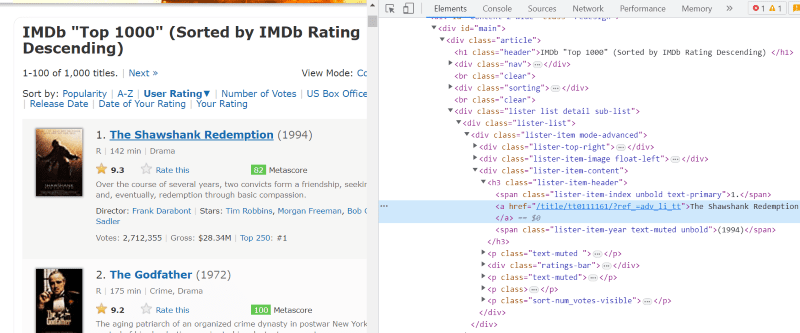
Забележка: Методът „find“ в beautiful Soup търси първия таг, който съответства на даденото му входно име. За разлика от „find“, методът „find_all“ търси всички тагове, които съответстват на дадения вход.
Стъпка 4: Можете да използвате методите „find“ и „find_all“, за да запазите HTML скрипта на името, ранга и годината на всеки филм в променлива в списък.
top_movies = soup_obj.find('div',attrs={'class': 'lister-list'}).find_all('h3')
Стъпка 5: Прегледайте списъка с филми, съхранени в променливата: „top_movies“ и извлечете името, ранга и годината на всеки филм в текстов формат от неговия HTML скрипт, като използвате кода по-долу.
for movie in top_movies:
movi_name = movie.a.text
rank = movie.span.text.rstrip('.')
year = movie.find('span', attrs={'class': 'lister-item-year text-muted unbold'})
year = year.text.strip('()')
print(movi_name + " ", rank+ " ", year+ " ")
В изходната екранна снимка можете да видите списъка с филми с тяхното име, ранг и година на издаване.
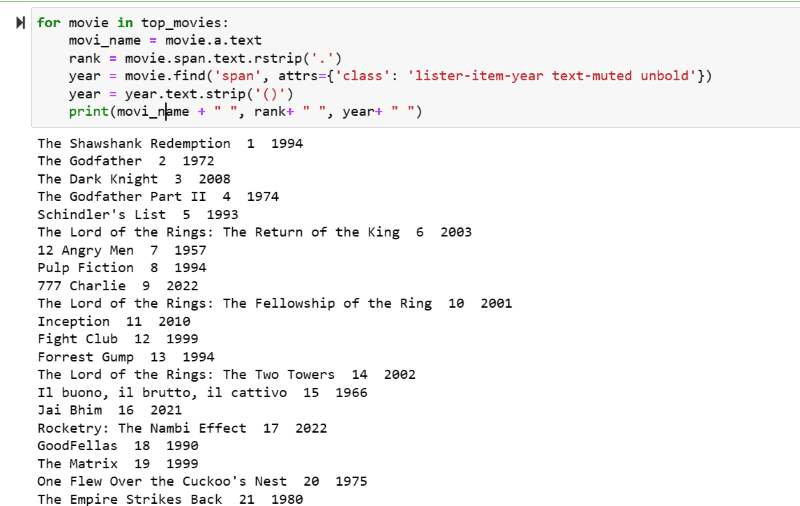
Можете без усилие да преместите отпечатаните данни в Excel лист с някакъв код на Python и да го използвате за вашия анализ.
Заключителни думи
Тази публикация ви напътства при инсталирането на красива Soup за уеб скрапинг. Освен това примерите за изстъргване, които показах, трябва да ви помогнат да започнете с Beautiful Soup.
Тъй като се интересувате как да инсталирате Beautiful Soup за уеб скрапинг, горещо ви препоръчвам да разгледате това разбираемо ръководство, за да научите повече за уеб скрапинга с помощта на Python.