
Reddit предлага JSON емисии за всеки subreddit. Ето как да създадете Bash скрипт, който изтегля и анализира списък с публикации от всеки subreddit, който харесвате. Това е само едно нещо, което можете да направите с JSON емисиите на Reddit.
Съдържание
Инсталиране на Curl и JQ
Ще използваме curl, за да извлечем JSON канала от Reddit и jq, за да анализираме JSON данните и да извлечем полетата, които искаме от резултатите. Инсталирайте тези две зависимости, като използвате apt-get на Ubuntu и други базирани на Debian Linux дистрибуции. В други дистрибуции на Linux използвайте вместо това инструмента за управление на пакети на вашата дистрибуция.
sudo apt-get install curl jq
Извлечете някои JSON данни от Reddit
Нека видим как изглежда емисията с данни. Използвайте curl, за да извлечете най-новите публикации от Леко Интересно subreddit:
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json
Обърнете внимание как опциите, използвани преди URL: -s принуждават curl да работи в безшумен режим, така че да не виждаме никакъв изход, освен данните от сървърите на Reddit. Следващата опция и параметърът, който следва, – „пример за скрепер на reddit“, задава персонализиран низ на потребителския агент, който помага на Reddit да идентифицира услугата, която осъществява достъп до техните данни. Сървърите на Reddit API прилагат ограничения за скорост въз основа на низа на потребителския агент. Задаването на персонализирана стойност ще накара Reddit да сегментира нашето ограничение на скоростта далеч от други обаждащи се и да намали шанса да получим грешка HTTP 429 Rate Limit Exceeded.
Резултатът трябва да запълни прозореца на терминала и да изглежда нещо подобно:
Има много полета в изходните данни, но всичко, което ни интересува, са заглавие, постоянна връзка и URL. Можете да видите изчерпателен списък с типове и техните полета на страницата с документация на API на Reddit: https://github.com/reddit-archive/reddit/wiki/JSON
Извличане на данни от изхода на JSON
Искаме да извлечем заглавие, постоянна връзка и URL от изходните данни и да ги запишем във файл, разделен с табулатори. Можем да използваме инструменти за обработка на текст като sed и grep, но имаме друг инструмент на наше разположение, който разбира JSON структури от данни, наречен jq. За първия ни опит, нека го използваме за красиво отпечатване и цветно кодиране на изхода. Ще използваме същото извикване както преди, но този път прекарайте изхода през jq и го инструктирайте да анализира и отпечата JSON данните.
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json | jq .
Обърнете внимание на периода, който следва командата. Този израз просто анализира входа и го отпечатва такъв, какъвто е. Резултатът изглежда добре форматиран и цветно кодиран:
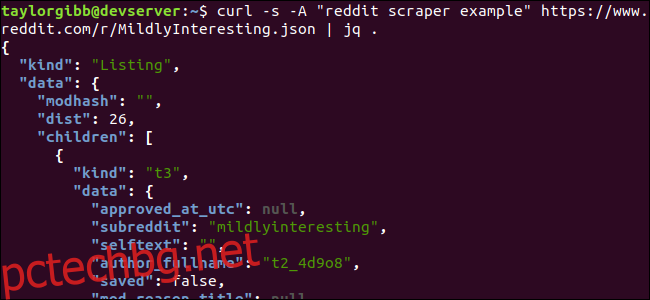
Нека да разгледаме структурата на JSON данните, които получаваме от Reddit. Основният резултат е обект, който съдържа две свойства: вид и данни. Последният притежава свойство, наречено деца, което включва масив от публикации към този subreddit.
Всеки елемент в масива е обект, който също съдържа две полета, наречени вид и данни. Свойствата, които искаме да вземем, са в обекта с данни. jq очаква израз, който може да бъде приложен към входните данни и произвежда желания изход. Той трябва да описва съдържанието по отношение на тяхната йерархия и членство в масив, както и как трябва да се трансформират данните. Нека изпълним цялата команда отново с правилния израз:
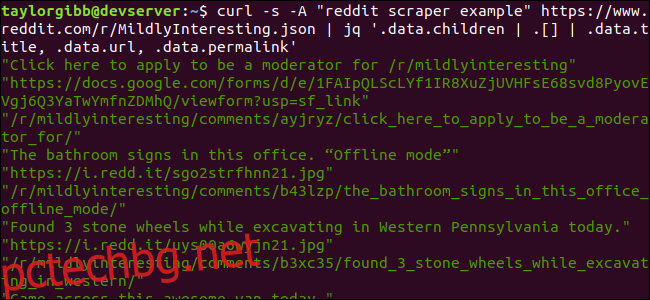
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json | jq ‘.data.children | .[] | .data.title, .data.url, .data.permalink’
Резултатът показва заглавие, URL и постоянна връзка всеки на собствен ред:
Нека се потопим в командата jq, която извикахме:
jq ‘.data.children | .[] | .data.title, .data.url, .data.permalink’
В тази команда има три израза, разделени от два символа с ръбове. Резултатите от всеки израз се предават на следващия за по-нататъшна оценка. Първият израз филтрира всичко, освен масива от списъци на Reddit. Този изход се прехвърля във втория израз и се принуждава в масив. Третият израз действа върху всеки елемент в масива и извлича три свойства. Повече информация за jq и неговия синтаксис на изразите можете да намерите в официалното ръководство на jq.
Обединяване на всичко в един скрипт
Нека съберем извикването на API и последващата обработка на JSON заедно в скрипт, който ще генерира файл с желаните от нас публикации. Ще добавим поддръжка за извличане на публикации от всеки subreddit, не само /r/MildlyInteresting.
Отворете редактора си и копирайте съдържанието на този фрагмент във файл, наречен scrape-reddit.sh
#!/bin/bash
if [ -z "$1" ]
then
echo "Please specify a subreddit"
exit 1
fi
SUBREDDIT=$1
NOW=$(date +"%m_%d_%y-%H_%M")
OUTPUT_FILE="${SUBREDDIT}_${NOW}.txt"
curl -s -A "bash-scrape-topics" https://www.reddit.com/r/${SUBREDDIT}.json |
jq '.data.children | .[] | .data.title, .data.url, .data.permalink' |
while read -r TITLE; do
read -r URL
read -r PERMALINK
echo -e "${TITLE}t${URL}t${PERMALINK}" | tr --delete " >> ${OUTPUT_FILE}
done
Този скрипт първо ще провери дали потребителят е предоставил име на subreddit. Ако не, излиза със съобщение за грешка и ненулев код за връщане.
След това той ще съхрани първия аргумент като име на subreddit и ще създаде име на файл с щампована дата, където изходът ще бъде запазен.
Действието започва, когато curl се извика с персонализирана заглавка и URL адреса на subreddit за изстъргване. Резултатът се предава по канал към jq, където се анализира и намалява до три полета: заглавие, URL и постоянна връзка. Тези редове се четат един по един и се записват в променлива с помощта на командата read, всичко в рамките на цикъл while, който ще продължи, докато няма повече редове за четене. Последният ред на вътрешния блок while отразява трите полета, ограничени от табулаторен знак, и след това го предава чрез командата tr, така че двойните кавички да могат да бъдат премахнати. След това изходът се добавя към файл.
Преди да можем да изпълним този скрипт, трябва да се уверим, че са му предоставени разрешения за изпълнение. Използвайте командата chmod, за да приложите тези разрешения към файла:
chmod u+x scrape-reddit.sh
И накрая, изпълнете скрипта с име на subreddit:
./scrape-reddit.sh MildlyInteresting
Изходният файл се генерира в същата директория и съдържанието му ще изглежда така:
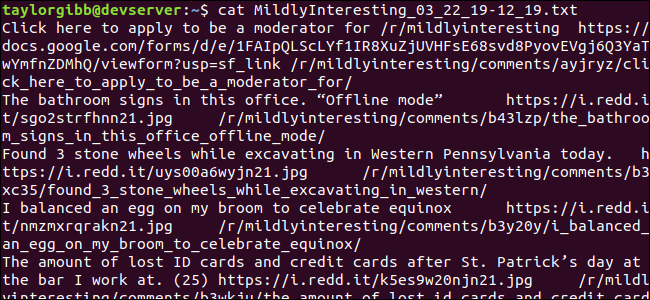
Всеки ред съдържа трите полета, които търсим, разделени с табулатор.
Отивайки по-нататък
Reddit е златна мина от интересно съдържание и медии и всичко е лесно достъпно с помощта на неговия JSON API. Сега, когато имате начин за достъп до тези данни и обработка на резултатите, можете да правите неща като:
Вземете най-новите заглавия от /r/WorldNews и ги изпратете на вашия работен плот, като използвате уведоми-изпрати
Интегрирайте най-добрите вицове от /r/DadJokes в Message-of-The-Day на вашата система
Вземете днешната най-добра снимка от /r/aww и я направете за фон на работния плот
Всичко това е възможно с помощта на предоставените данни и инструментите, които имате във вашата система. Приятно хакване!