

Scikit-LLM е пакет на Python, който помага за интегрирането на големи езикови модели (LLM) в рамката на scikit-learn. Помага при изпълнението на задачи за анализ на текст. Ако сте запознати с scikit-learn, ще ви бъде по-лесно да работите със Scikit-LLM.
Важно е да се отбележи, че Scikit-LLM не замества scikit-learn. scikit-learn е библиотека за машинно обучение с общо предназначение, но Scikit-LLM е специално проектирана за задачи за анализ на текст.
Съдържание
Първи стъпки със Scikit-LLM
За да започнете с Scikit-LLM, ще трябва да инсталирате библиотеката и да конфигурирате вашия API ключ. За да инсталирате библиотеката, отворете вашата IDE и създайте нова виртуална среда. Това ще помогне за предотвратяване на потенциални конфликти на версиите на библиотеката. След това изпълнете следната команда в терминала.
pip install scikit-llm
Тази команда ще инсталира Scikit-LLM и неговите необходими зависимости.
За да конфигурирате вашия API ключ, трябва да го придобиете от вашия LLM доставчик. За да получите OpenAI API ключ, изпълнете следните стъпки:
Продължете към OpenAI API страница. След това щракнете върху вашия профил, разположен в горния десен ъгъл на прозореца. Изберете Преглед на API ключове. Това ще ви отведе до страницата с API ключове.
На страницата API ключове щракнете върху бутона Създаване на нов таен ключ.
Назовете вашия API ключ и щракнете върху бутона Създаване на таен ключ, за да генерирате ключа. След генерирането трябва да копирате ключа и да го съхраните на сигурно място, тъй като OpenAI няма да покаже ключа отново. Ако го загубите, ще трябва да генерирате нов.
Сега, след като имате вашия API ключ, отворете вашата IDE и импортирайте SKLLMConfig клас от библиотеката Scikit-LLM. Този клас ви позволява да задавате опции за конфигурация, свързани с използването на големи езикови модели.
from skllm.config import SKLLMConfig
Този клас очаква да зададете своя OpenAI API ключ и подробности за организацията.
SKLLMConfig.set_openai_key("Your API key")
SKLLMConfig.set_openai_org("Your organization ID")
ID на организацията и името не са еднакви. ИД на организацията е уникален идентификатор на вашата организация. За да получите ID на вашата организация, преминете към Организация OpenAI страница с настройки и я копирайте. Вече сте установили връзка между Scikit-LLM и големия езиков модел.
Scikit-LLM изисква от вас да имате разплащателен план. Това е така, защото безплатният пробен OpenAI акаунт има ограничение на скоростта от три заявки на минута, което не е достатъчно за Scikit-LLM.
Опитът да използвате безплатния пробен акаунт ще доведе до грешка, подобна на тази по-долу, докато извършвате анализ на текст.

За да научите повече за ограниченията на скоростта. Продължете към Страница с ограничения на скоростта на OpenAI.
Доставчикът на LLM не се ограничава само до OpenAI. Можете да използвате и други доставчици на LLM.
Импортиране на необходимите библиотеки и зареждане на набора от данни
Импортирайте панди, които ще използвате за зареждане на набора от данни. Освен това от Scikit-LLM и scikit-learn импортирайте необходимите класове.
import pandas as pd
from skllm import ZeroShotGPTClassifier, MultiLabelZeroShotGPTClassifier
from skllm.preprocessing import GPTSummarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MultiLabelBinarizer
След това заредете набора от данни, върху който искате да извършите текстов анализ. Този код използва набора от данни за филми на IMDB. Можете обаче да го настроите, за да използвате свой собствен набор от данни.
data = pd.read_csv("imdb_movies_dataset.csv")
data = data.head(100)
Използването само на първите 100 реда от набора от данни не е задължително. Можете да използвате целия си набор от данни.
След това извлечете характеристиките и колоните с етикети. След това разделете своя набор от данни на набори за обучение и тестване.
X = data['Description']y = data['Genre']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Колоната Жанр съдържа етикетите, които искате да предвидите.
Zero-Shot текстова класификация със Scikit-LLM
Zero-shot текстова класификация е функция, предлагана от големи езикови модели. Той класифицира текста в предварително дефинирани категории без необходимост от изрично обучение върху етикетирани данни. Тази възможност е много полезна, когато се занимавате със задачи, при които трябва да класифицирате текст в категории, които не сте предвидили по време на обучението на модела.
За да извършите нулева текстова класификация с помощта на Scikit-LLM, използвайте класа ZeroShotGPTClassifier.
zero_shot_clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo")
zero_shot_clf.fit(X_train, y_train)
zero_shot_predictions = zero_shot_clf.predict(X_test)
print("Zero-Shot Text Classification Report:")
print(classification_report(y_test, zero_shot_predictions))
Резултатът е както следва:
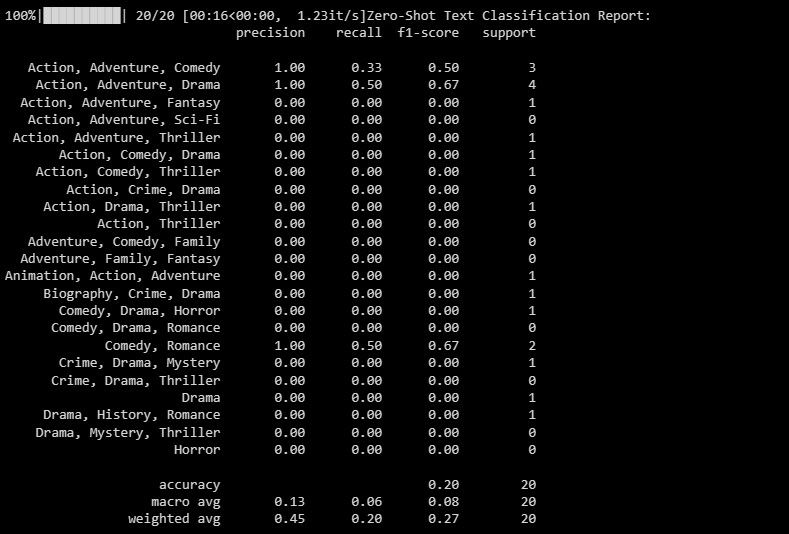
Докладът за класификация предоставя показатели за всеки етикет, който моделът се опитва да предвиди.
Текстова класификация с много етикети Zero-Shot със Scikit-LLM
В някои сценарии един текст може да принадлежи към няколко категории едновременно. Традиционните модели на класификация се борят с това. Scikit-LLM от друга страна прави тази класификация възможна. Класификацията на текст с нулев изстрел с множество етикети е от решаващо значение при присвояването на множество описателни етикети на единична текстова проба.
Използвайте MultiLabelZeroShotGPTClassifier, за да предвидите кои етикети са подходящи за всяка текстова проба.
candidate_labels = ["Action", "Comedy", "Drama", "Horror", "Sci-Fi"]
multi_label_zero_shot_clf = MultiLabelZeroShotGPTClassifier(max_labels=2)
multi_label_zero_shot_clf.fit(X_train, candidate_labels)
multi_label_zero_shot_predictions = multi_label_zero_shot_clf.predict(X_test)
mlb = MultiLabelBinarizer()
y_test_binary = mlb.fit_transform(y_test)
multi_label_zero_shot_predictions_binary = mlb.transform(multi_label_zero_shot_predictions)
print("Multi-Label Zero-Shot Text Classification Report:")
print(classification_report(y_test_binary, multi_label_zero_shot_predictions_binary))
В кода по-горе вие дефинирате етикетите кандидати, към които може да принадлежи вашият текст.
Резултатът е както е показано по-долу:
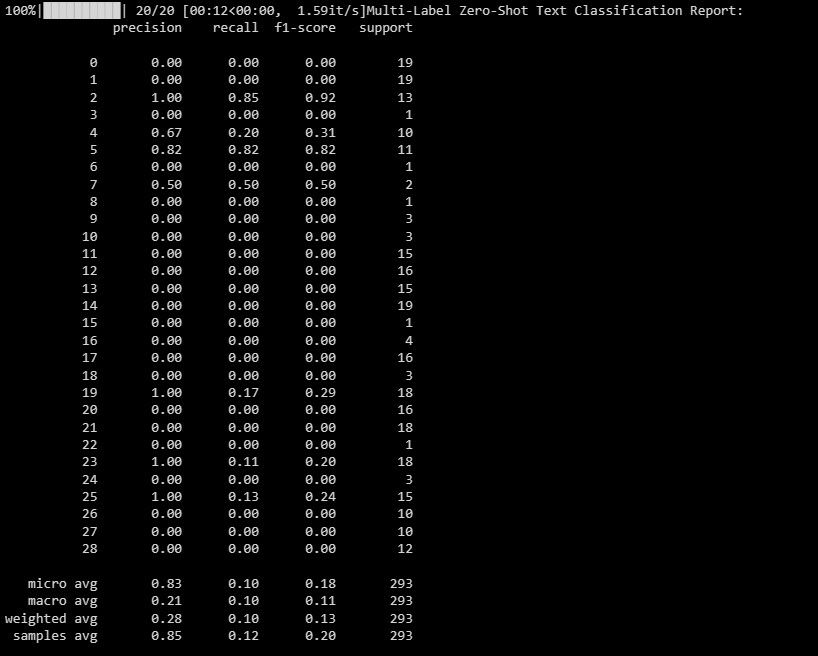
Този отчет ви помага да разберете колко добре се представя вашият модел за всеки етикет в класификацията с множество етикети.
Векторизация на текст със Scikit-LLM
При текстовата векторизация текстовите данни се преобразуват в цифров формат, който моделите за машинно обучение могат да разберат. Scikit-LLM предлага GPTVectorizer за това. Тя ви позволява да трансформирате текст във вектори с фиксирани размери, като използвате GPT модели.
Можете да постигнете това, като използвате честотата на термина – обратна честота на документа.
tfidf_vectorizer = TfidfVectorizer(max_features=1000)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
print("TF-IDF Vectorized Features (First 5 samples):")
print(X_train_tfidf[:5])
Ето резултата:
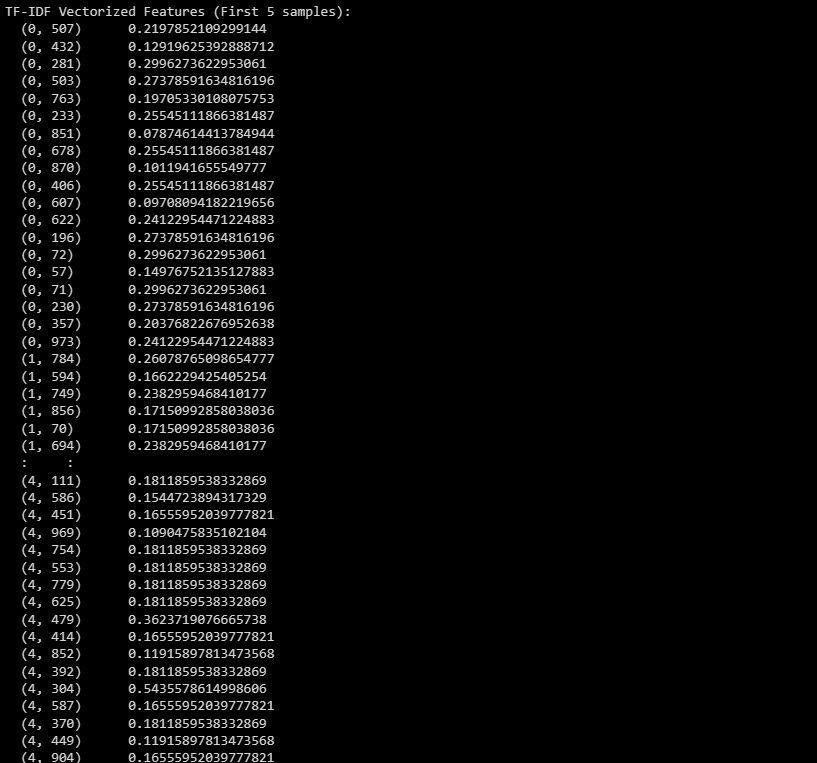
Резултатът представлява векторизираните характеристики на TF-IDF за първите 5 проби в набора от данни.
Резюмиране на текст със Scikit-LLM
Резюмирането на текст помага за уплътняването на част от текста, като същевременно запазва най-критичната информация. Scikit-LLM предлага GPTSummarizer, който използва GPT моделите за генериране на кратки резюмета на текст.
summarizer = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=15)
summaries = summarizer.fit_transform(X_test)
print(summaries)
Резултатът е както следва:
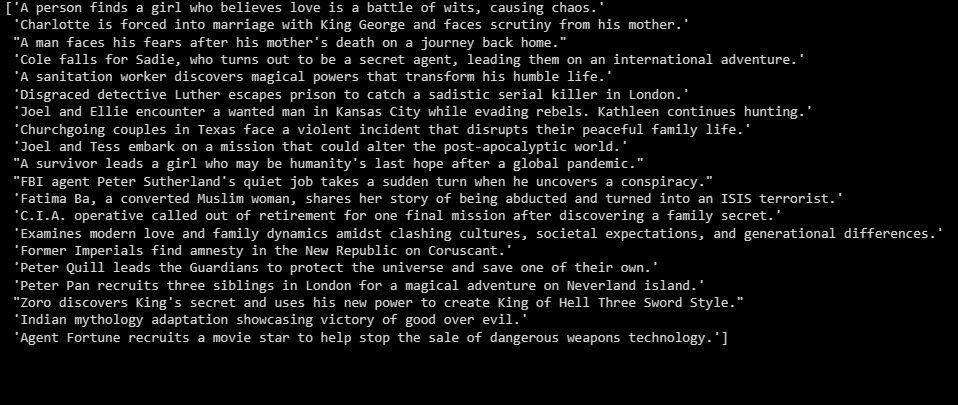
Горното е обобщение на данните от теста.
Създавайте приложения върху LLMs
Scikit-LLM отваря свят от възможности за анализ на текст с големи езикови модели. Разбирането на технологията зад големите езикови модели е от решаващо значение. Това ще ви помогне да разберете техните силни и слаби страни, което може да ви помогне в изграждането на ефективни приложения върху тази авангардна технология.