

Командата Linux uniq преминава през вашите текстови файлове, търсейки уникални или дублиращи се редове. В това ръководство разглеждаме неговата гъвкавост и функции, както и как можете да се възползвате максимално от тази изящна помощна програма.
Съдържание
Намиране на съвпадащи редове от текст в Linux
Командата uniq е бърз, гъвкав и страхотен в това, което прави. Въпреки това, подобно на много команди на Linux, той има няколко странности – което е добре, стига да знаете за тях. Ако се решите без малко вътрешно ноу-хау, може да останете да си почешете главата от резултатите. Ще посочим тези странности, докато вървим.
Командата uniq е идеална за тези в лагера на целеустремените, предназначени да правят едно нещо и да го правят добре. Ето защо той също така е особено подходящ за работа с тръби и играе ролята си в командните тръбопроводи. Един от неговите най-честите сътрудници е сортиране, защото uniq трябва да има сортиран вход, върху който да работи.
Да го запалим!
Работи uniq без опции
Имаме текстов файл, който съдържа текстовете на на Робърт Джонсън песен Вярвам, че ще избърша метлата си. Нека видим какво прави uniq от него.
Ще напишем следното, за да преведем изхода в по-малко:
uniq dust-my-broom.txt | less

Получаваме цялата песен, включително дублиращи се редове, в по-малко:
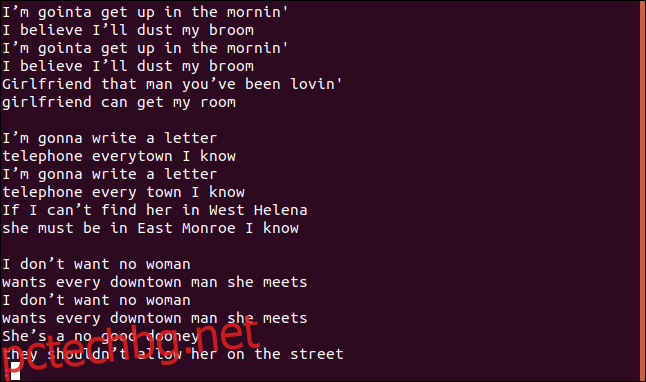
Изглежда, че това не са нито уникалните линии, нито дублираните линии.
Точно така, защото това е първата странност. Ако стартирате uniq без опции, той се държи така, сякаш сте използвали опцията -u (уникални редове). Това казва на uniq да отпечатва само уникалните редове от файла. Причината да виждате дублиращи се редове е, че за да може uniq да счита даден ред за дубликат, той трябва да е в непосредствена близост до неговия дубликат, откъдето идва сортирането.
Когато сортираме файла, той групира дублиращите се редове и uniq ги третира като дублирани. Ще използваме сортиране на файла, ще препратим сортирания изход в uniq и след това ще пренесем крайния изход в по-малко.
За целта набираме следното:
sort dust-my-broom.txt | uniq | less

Сортиран списък с редове се появява в по-малко.

Репликата „Вярвам, че ще избърша метлата си“ определено се появява в песента повече от веднъж. Всъщност се повтаря два пъти в първите четири реда на песента.
И така, защо се показва в списък с уникални редове? Тъй като първият път, когато се появи ред във файла, той е уникален; само следващите записи са дублирани. Можете да мислите за това като изброяване на първото появяване на всеки уникален ред.
Нека отново да използваме сортиране и да пренасочим изхода в нов файл. По този начин не е нужно да използваме сортиране във всяка команда.
Набираме следната команда:
sort dust-my-broom.txt > sorted.txt
 sorted.txt” в прозорец на терминала.’ ширина=”646″ височина=”57″ onload=”pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);” onerror=”this.onerror=null;pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);”>
sorted.txt” в прозорец на терминала.’ ширина=”646″ височина=”57″ onload=”pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);” onerror=”this.onerror=null;pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);”>
Сега имаме предварително сортиран файл, с който да работим.
Преброяване на дубликатите
Можете да използвате опцията -c (брой), за да отпечатате колко пъти всеки ред се появява във файл.
Въведете следната команда:
uniq -c sorted.txt | less

Всеки ред започва с колко пъти този ред се появява във файла. Въпреки това ще забележите, че първият ред е празен. Това ви казва, че във файла има пет празни реда.
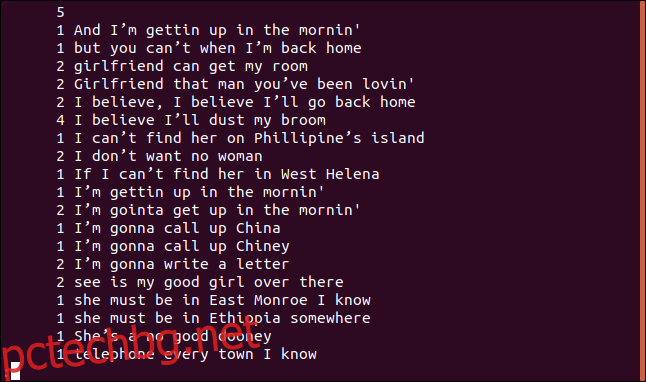
Ако искате изходът да бъде сортиран в числов ред, можете да подадете изхода от uniq в сортиране. В нашия пример ще използваме опциите -r (обратно) и -n (числово сортиране) и ще преведем резултатите в по-малко.
Пишем следното:
uniq -c sorted.txt | sort -rn | less

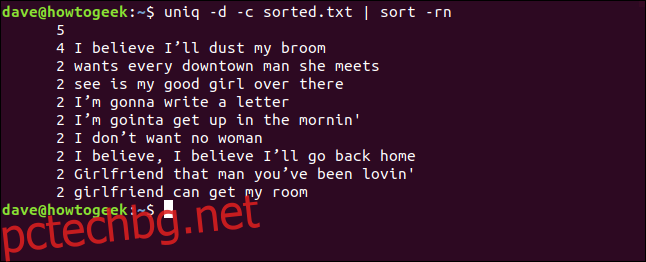
Списъкът е сортиран в низходящ ред въз основа на честотата на появяване на всеки ред.

Изброяване само на дублиращи се редове
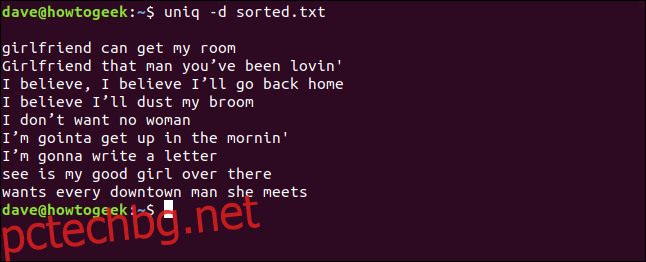
Ако искате да видите само редовете, които се повтарят във файл, можете да използвате опцията -d (повтаря се). Без значение колко пъти даден ред се дублира във файл, той е посочен само веднъж.
За да използваме тази опция, въвеждаме следното:
uniq -d sorted.txt

Дублираните редове са изброени за нас. Ще забележите празния ред в горната част, което означава, че файлът съдържа дублиращи се празни редове – това не е място, оставено от uniq за козметично компенсиране на списъка.
Можем също да комбинираме опциите -d (повтаря се) и -c (брой) и да предаваме изхода чрез сортиране. Това ни дава сортиран списък с редовете, които се появяват поне два пъти.
Въведете следното, за да използвате тази опция:
uniq -d -c sorted.txt | sort -rn
Изброяване на всички дублирани редове
Ако искате да видите списък на всеки дублиран ред, както и запис за всеки път, когато се появи ред във файла, можете да използвате опцията -D (всички дублирани редове).
За да използвате тази опция, въведете следното:
uniq -D sorted.txt | less

Списъкът съдържа запис за всеки дублиран ред.

Ако използвате опцията –group, тя отпечатва всеки дублиран ред с празен ред или преди (предварително), или след всяка група (добавяне), или и двете преди и след (и двете) всяка група.
Използваме append като наш модификатор, така че въвеждаме следното:
uniq --group=append sorted.txt | less

Групите са разделени с празни редове, за да бъдат по-лесни за четене.
Проверка на определен брой знаци
По подразбиране uniq проверява цялата дължина на всеки ред. Ако обаче искате да ограничите проверките до определен брой знаци, можете да използвате опцията -w (проверка на символи).
В този пример ще повторим последната команда, но ще ограничим сравненията до първите три знака. За целта набираме следната команда:
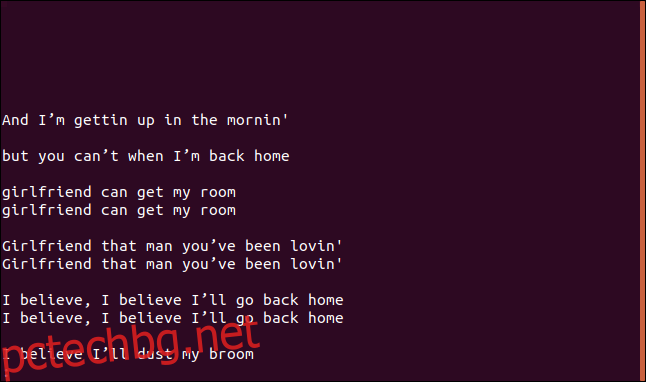
uniq -w 3 --group=append sorted.txt | less

Резултатите и групировките, които получаваме, са доста различни.
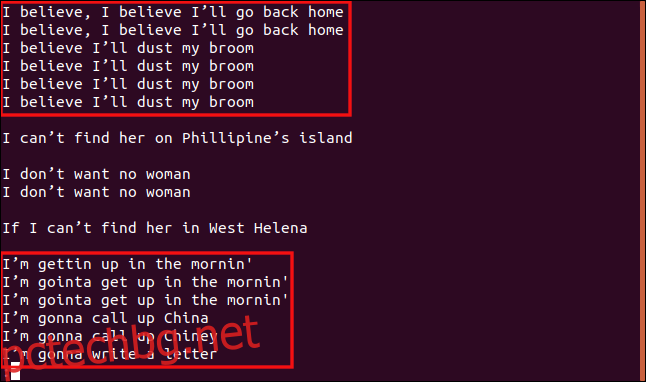
Всички редове, които започват с „I b“, са групирани заедно, тъй като тези части от редовете са идентични, така че се считат за дублирани.
По същия начин всички редове, които започват с „аз съм“, се третират като дубликати, дори ако останалата част от текста е различна.
Игнориране на определен брой символи
Има някои случаи, в които може да е полезно да пропуснете определен брой знаци в началото на всеки ред, например когато редовете във файл са номерирани. Или да речем, че имате нужда от uniq, за да прескочите клеймото за време и да започнете да проверявате редовете от шест знак вместо от първия знак.
По-долу е дадена версия на нашия сортиран файл с номерирани редове.

Ако искаме uniq да започне своите проверки за сравнение от знак три, можем да използваме опцията -s (пропускане на знаци), като напишем следното:
uniq -s 3 -d -c numbered.txt
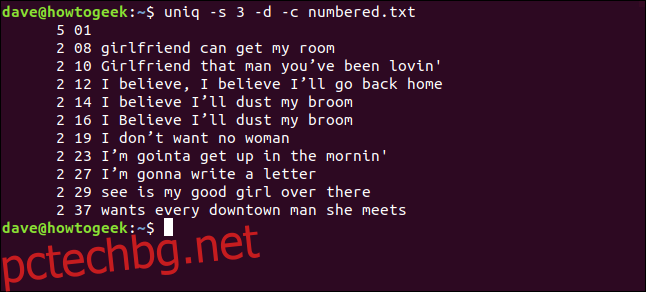
Редовете се откриват като дубликати и се броят правилно. Обърнете внимание, че показаните номера на редовете са тези на първото появяване на всеки дубликат.
Можете също да пропуснете полета (поредица от знаци и малко празно пространство) вместо знаци. Ще използваме опцията -f (полета), за да кажем на uniq кои полета да игнорира.
Пишем следното, за да кажем на uniq да игнорира първото поле:
uniq -f 1 -d -c numbered.txt
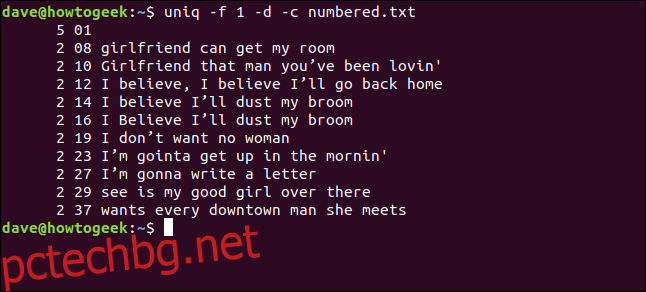
Получаваме същите резултати, които направихме, когато казахме на uniq да пропусне три знака в началото на всеки ред.
Пренебрегване на делото
По подразбиране uniq е чувствителен към малки и големи букви. Ако една и съща буква се появи ограничена и с малки букви, uniq счита, че редовете са различни.
Например, проверете изхода от следната команда:
uniq -d -c sorted.txt | sort -rn
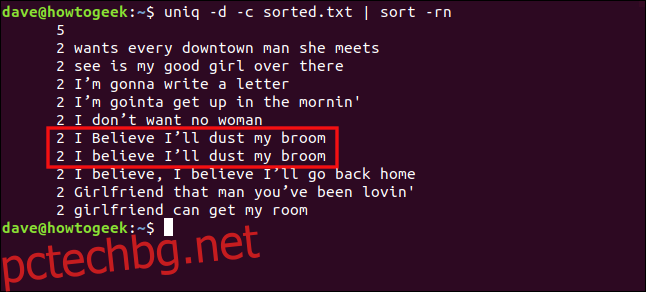
Редовете „Вярвам, че ще избърша праха от метлата си“ и „Вярвам, че ще избърша праха от метлата си“ не се третират като дублирани поради разликата в буквата на „B“ в „вярвам“.
Ако включим опцията -i (игнориране на регистъра на буквите), тези редове ще бъдат третирани като дублирани. Пишем следното:
uniq -d -c -i sorted.txt | sort -rn
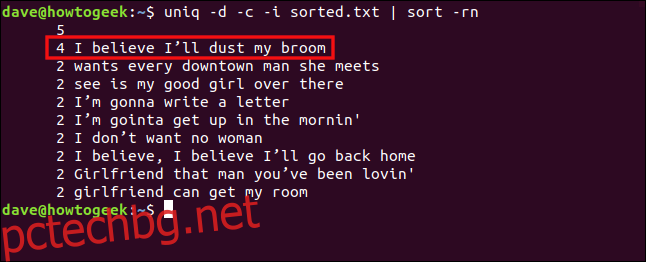
Сега линиите се третират като дубликати и се групират заедно.
Linux предоставя на ваше разположение множество специални помощни програми. Както много от тях, uniq не е инструмент, който ще използвате всеки ден.
Ето защо голяма част от това да станете опитни в Linux е да запомните кой инструмент ще реши текущия ви проблем и къде можете да го намерите отново. Ако тренирате обаче, ще се справите добре.
Или винаги можете просто да потърсите How-To Geek – вероятно имаме статия за това.