

Ако сте използвали Linux от известно време, вече знаете за grep — Global Regular Expression Print, инструмент за обработка на текст, който можете да използвате за търсене на файлове и директории. Той е много полезен в ръцете на опитен потребител на Linux. Използването му без регулярен израз обаче може да ограничи неговите възможности.
Но какво е Regex?
Regex са регулярни изрази, които можете да използвате, за да подобрите функционалността за търсене на grep. Regex, по дефиниция, е усъвършенстван модел за филтриране на изхода. С практика можете да използвате regex ефективно, тъй като можете да го използвате и с други команди на Linux.
В нашия урок ще научим как да използваме Grep и Regex ефективно.
Съдържание
Предпоставка
Използването на grep с regex изисква добро познаване на Linux. Ако сте начинаещ, вижте нашите ръководства за Linux.
Нуждаете се и от достъп до лаптоп или компютър с операционна система Linux. Можете да използвате всяка Linux дистрибуция по ваш избор. И ако имате машина с Windows, все още можете да използвате Linux с WSL2. Вижте нашия подробен поглед върху това тук.
Достъпът до командния ред/терминал ви позволява да изпълнявате всички команди, предоставени в нашия урок за grep/regex.
Освен това ви е необходим достъп до текстови файлове, които ще ви трябват, за да изпълнявате примерите. Използвах ChatGPT, за да генерирам стена от текст, казвайки й да пише за технологии. Подканата, която използвах, е както по-долу.
„Генерирайте 400 думи за технологиите. Трябва да включва повечето технологии. Също така се уверете, че повтаряте имената на технологиите в текста.
След като генерира текста, аз го копирах и го записах във файла tech.txt, който ще използваме в целия урок.
И накрая, основното разбиране на командата grep е задължително. Можете да разгледате 16 примера за команда grep, за да опресните знанията си. Ще ви представим накратко и командата grep, за да започнете.
Синтаксис и примери за команда grep
Синтаксисът на командата grep е прост.
$ grep -options [regex/pattern] [files]
Както можете да забележите, той очаква шаблон и списъка с файлове, които искате да изпълните командата.
Има много налични опции за grep, които променят неговата функционалност. Те включват:
- – i: пренебрегване на случаите
- -r: прави рекурсивно търсене
- -w: извършете търсене, за да намерите само цели думи
- -v: показва всички несъвпадащи редове
- -n: показва всички съвпадащи номера на редове
- -l: отпечата имената на файловете
- – цвят: цветен резултат
- -c: показва броя на съвпаденията за използвания шаблон
#1. Търсене на цяла дума
Ще трябва да използвате аргумента -w с grep за търсене на цяла дума. Използвайки го, вие заобикаляте всички низове, които отговарят на дадения шаблон.
$ grep -w ‘tech\|5G’ tech.txt
Както можете да видите, командата води до изход, където търси две думи, „5G“ и „tech“, в целия текст. След това ги маркира с червен цвят.
Тук | символът за тръба е екраниран, така че grep да не го обработва като метасимвол.
#2. Търсене без регистрация
За да извършите търсене без значение за главни и малки букви, използвайте grep с аргумента -i.
$ grep -i ‘tech’ tech.txt
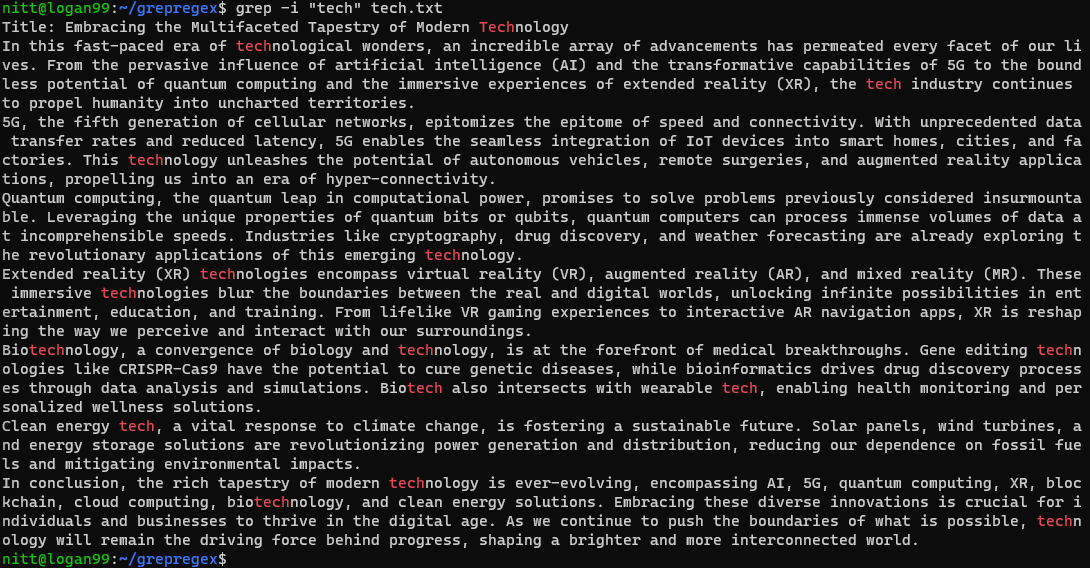
Командата търси всеки екземпляр на низа „tech“, независимо дали е пълна дума или част от нея.
#3. Направете търсене на несъответстващ ред
За да покажете всички редове, които не съдържат даден шаблон, ще трябва да използвате аргумента -v.
$ grep -v ‘tech’ tech.txt

Резултатът показва всички редове, които не съдържат думата „tech“. Освен това ще видите и празни редове. Тези редове са редовете, които са след параграф.
#4. Направете рекурсивно търсене
За да извършите рекурсивно търсене, използвайте аргумента -r с grep.
$ grep -R ‘error\|warning’ /var/log/*.log
#output /var/log/bootstrap.log:2023-01-03 21:40:18 URL:http://ftpmaster.internal/ubuntu/pool/main/libg/libgpg-error/libgpg-erro 0_1.43-3_amd64.deb [69684/69684] -> "/build/chroot//var/cache/apt/archives/partial/libgpg-error0_1.43-3_amd64.deb" [1] /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: ignoring pre-dependency problem!
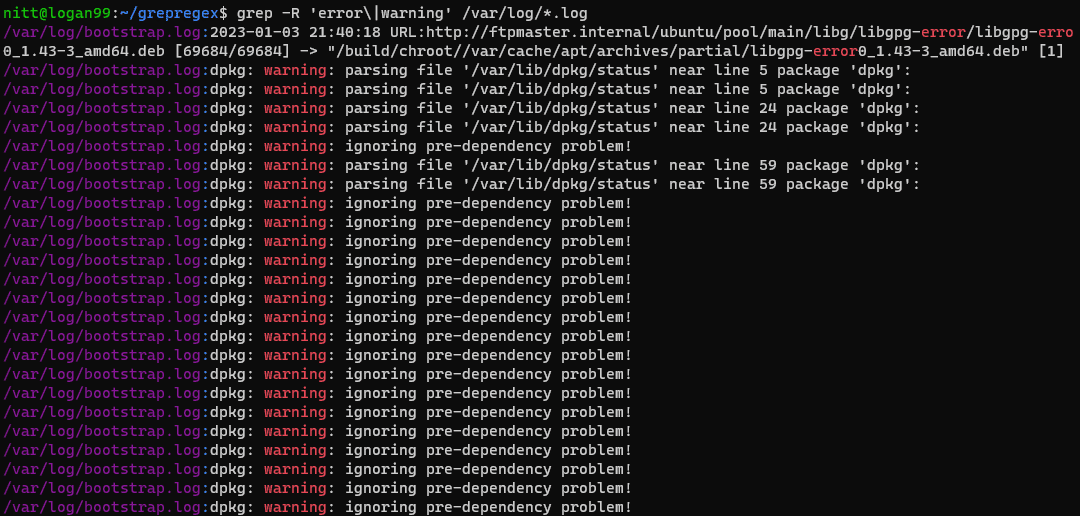
Командата grep рекурсивно търси две думи, „грешка“ и „предупреждение“, в директорията /var/log. Това е удобна команда, за да научите за всички предупреждения и грешки в регистрационните файлове.
Grep и Regex: Какво е това и примери
Тъй като работим с regex, трябва да знаете, че regex предлага три опции за синтаксис. Те включват:
- Основни регулярни изрази (BRE)
- Разширени регулярни изрази (ERE)
- Pearl съвместими регулярни изрази (PCRE)
Командата grep използва BRE като опция по подразбиране. Така че, ако искате да използвате други режими на регулярни изрази, ще трябва да ги споменете. Командата grep също третира метасимволите такива, каквито са. Така че, ако използвате метасимволи като ?, +, ), ще трябва да ги екранирате с командата обратна наклонена черта (\).
Синтаксисът на grep с regex е както по-долу.
$ grep [regex] [filenames]
Нека видим grep и regex в действие с примерите по-долу.
#1. Съвпадения на буквални думи
За да направите съвпадение на буквална дума, ще трябва да предоставите низ като регулярен израз. В края на краищата думата също е регулярен израз.
$ grep "technologies" tech.txt

По същия начин можете също да използвате буквални съвпадения, за да намерите текущи потребители. За да направите това, бягайте,
$ grep bash /etc/passwd
#output root:x:0:0:root:/root:/bin/bash nitt:x:1000:1000:,,,:/home/nitt:/bin/bash
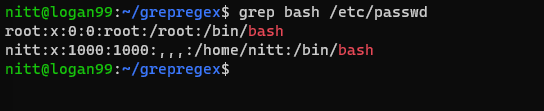
Това показва потребителите, които имат достъп до bash.
#2. Съвпадение на котва
Съпоставянето на котва е полезна техника за разширени търсения с помощта на специални знаци. В регулярния израз има различни символи за котва, които можете да използвате, за да представите конкретни позиции в рамките на текст. Те включват:
- Карет символ „^“: Карет символът съвпада с началото на въведения низ или ред и търси празен низ.
- Символ за долар ‘$’: Символът за долар съвпада с края на въведения низ или ред и търси празен низ.
Другите два знака за съвпадение на котва включват границата на думата ‘\ b’ и границата без дума ‘\ B’.
- ‘\ b’ граница на думата: С \b можете да утвърдите позицията между дума и несловен знак. С прости думи, това ви позволява да съпоставите пълни думи. По този начин можете да избегнете частични съвпадения. Можете също да го използвате, за да замените думи или да преброите срещанията на думи в низ.
- \B граница без дума: Това е обратното на \b граница на дума в регулярен израз, тъй като утвърждава позиция, която не е между знаци от две думи или не-думи.
Нека преминем през примери, за да добием ясна представа.
$ grep ‘^From’ tech.txt

Използването на каретка изисква въвеждане на думата или модела в правилния регистър. Това е така, защото е чувствителен към малки и малки букви. Така че, ако изпълните следната команда, тя няма да върне нищо.
$ grep ‘^from’ tech.txt
По същия начин можете да използвате символа $, за да намерите изречението, което съответства на даден модел, низ или дума.
$ grep ‘technology.$' tech.txt

Можете да комбинирате и двата символа ^ и $. Нека разгледаме примера по-долу.
$ grep “^From \| technology.$” tech.txt
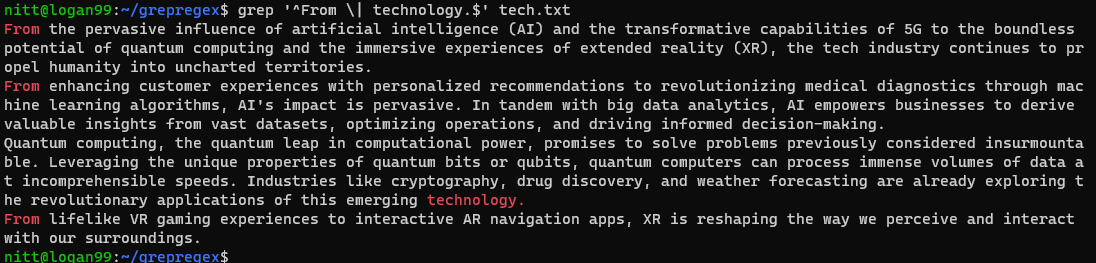
Както можете да видите, изходът съдържа изречения, започващи с „От“ и изречения, завършващи с „технология“.
#3. Групиране
Ако искате да търсите няколко шаблона наведнъж, ще трябва да използвате Групиране. Помага ви да създавате малки групи от символи и шаблони, които можете да третирате като едно цяло. Например, можете да създадете група (техническа), която включва термина „t“, „e“, „c“, „h“.
За да добием ясна представа, нека разгледаме един пример.
$ grep 'technol\(ogy\)\?' tech.txt

С групирането можете да сравнявате повтарящи се шаблони, да улавяте групи и да търсите алтернативи.
Алтернативно търсене с групиране
Нека да видим пример за алтернативно търсене.
$ grep "\(tech\|technology\)" tech.txt
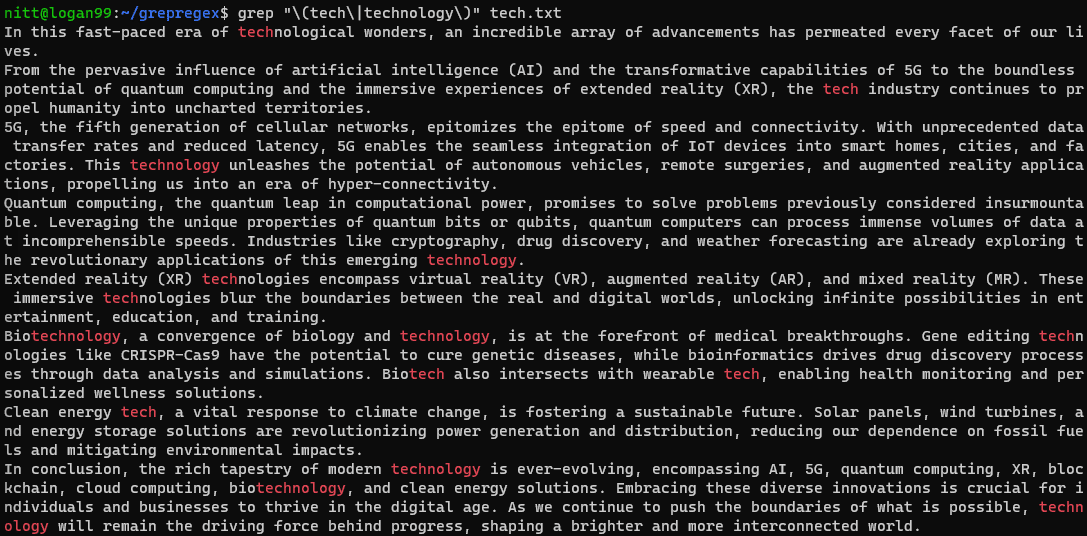
Ако искате да извършите търсене на низ, тогава ще трябва да го предадете със символа за тръба. Нека го видим в примера по-долу.
$ echo “tech technological technologies technical” | grep "\(tech\|technology\)"
#output “tech technological technologies technical”

Прихващащи групи, неулавяни групи и повтарящи се модели
А какво да кажем за улавяните и неулавяните групи?
Ще трябва да създадете група в регулярния израз и да я предадете на низа или файл за заснемане на групи.
$ echo 'tech655 tech655nical technologies655 tech655-oriented 655' | grep "\(tech\)\(655\)"
#output tech655 tech655nical technologies655 tech655-oriented 655

А за групи без прихващане ще трябва да използвате ?: в скоби.
И накрая, имаме повтарящи се модели. Ще трябва да промените регулярния израз, за да проверите за повтарящи се модели.
$ echo ‘teach tech ttrial tttechno attest’ | grep '\(t\+\)'
#output ‘teach tech ttrial tttechno attest’
Тук регулярният израз търси един или повече екземпляри на знака ‘t’.
#4. Класове на символи
С класове знаци можете лесно да пишете регулярни изрази. Тези символни класове използват квадратни скоби. Някои от добре познатите класове герои включват:
- [:digit:] – 0 до 9 цифри
- [:alpha:] – азбучни знаци
- [:alnum:] – буквено-цифрови знаци
- [:lower:] – малки букви
- [:upper:] – главни букви
- [:xdigit:] – шестнадесетични цифри, включително 0-9, AF, af
- [:blank:] – празни знаци като табулация или интервал
И така нататък!
Нека проверим някои от тях в действие.
$ grep [[:digit]] tech.txt

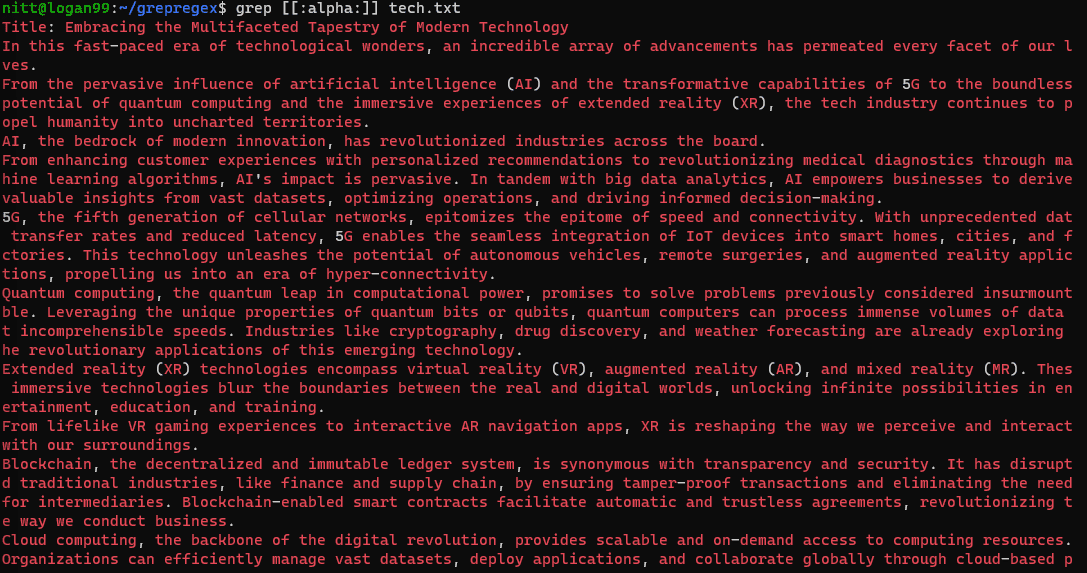
$ grep [[:alpha:]] tech.txt
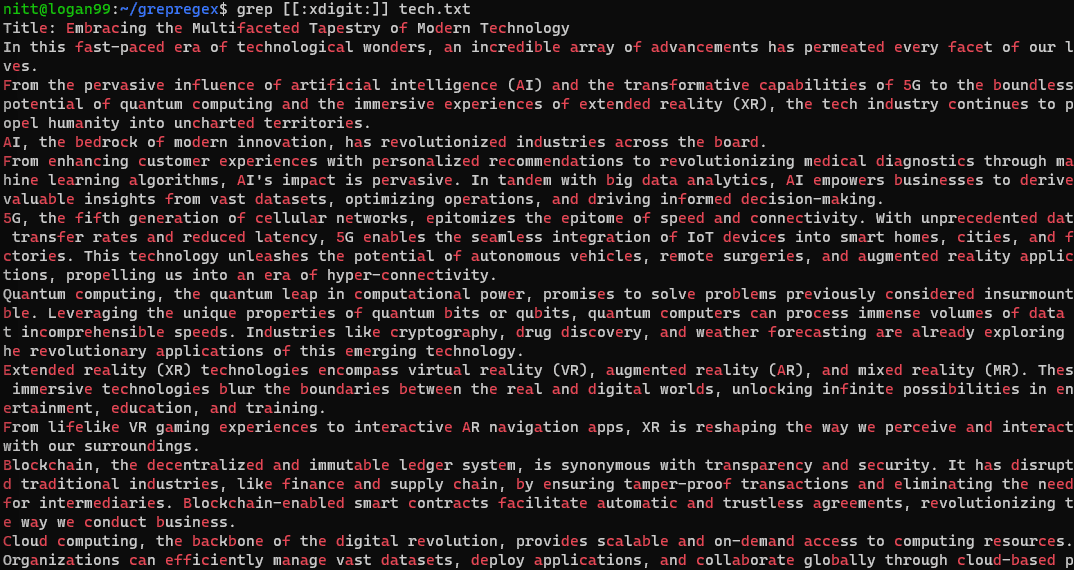
$ grep [[:xdigit:]] tech.txt
#5. Квантори
Кванторите са метазнаци и са в основата на регулярния израз. Те ви позволяват да съпоставите точния външен вид. Нека ги разгледаме по-долу.
- * → Нула или повече съвпадения
- + → едно или повече съвпадения
- ? → Нула или едно съвпадение
- {x} → x съвпада
- {x, } → x или повече съвпадения
- {x,z} → от x до z съвпада
- {, z} → до z съвпадения
$ echo ‘teach tech ttrial tttechno attest’ | grep -E 't+'
#output ‘teach tech ttrial tttechno attest’
Тук той търси екземпляри на знака ‘t’ за едно или повече съвпадения. Тук -E означава разширен регулярен израз (който ще обсъдим по-късно.)

#6. Разширен регулярен израз
Ако не ви харесва добавянето на екраниращи знаци в модела на регулярен израз, трябва да използвате разширен регулярен израз. Премахва необходимостта от добавяне на екраниращи знаци. За да направите това, ще трябва да използвате флага -E.
$ grep -E 'in+ovation' tech.txt

#7. Използване на PCRE за извършване на сложни търсения
PCRE (съвместим с Perl регулярен израз) ви позволява да правите много повече от писане на основни изрази. Например, можете да напишете „\d“, което обозначава [0-9].
Например, можете да използвате PCRE за търсене на имейл адреси.
echo "Contact me at [email protected]" | grep -P "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b"
#output Contact me at [email protected]

Тук PCRE гарантира, че шаблонът е съвпадащ. По същия начин можете също да използвате PCRE модел, за да проверите за модели на дата.
$ echo "The Sparkain site launched on 2023-07-29" | grep -P "\b\d{4}-\d{2}-\d{2}\b"
#output The Sparkain site launched on 2023-07-29

Командата намира датата във формат ГГГГ-ММ-ДД. Можете да го промените, за да съответства и на друг формат на датата.
#8. Редуване
Ако искате алтернативни съвпадения, можете да използвате екранираните символи за вертикална черта (\|).
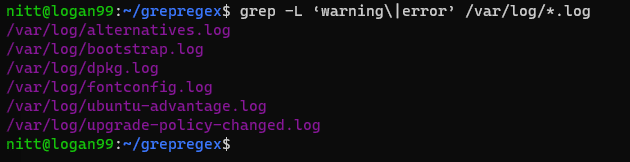
$ grep -L ‘warning\|error’ /var/log/*.log
#output /var/log/alternatives.log /var/log/bootstrap.log /var/log/dpkg.log /var/log/fontconfig.log /var/log/ubuntu-advantage.log /var/log/upgrade-policy-changed.log
Резултатът изброява имената на файловете, съдържащи „предупреждение“ или „грешка“.
Заключителни думи
Това ни води до края на нашето ръководство за grep и regex. Можете да използвате grep с regex широко, за да прецизирате търсенията. С правилна употреба можете да спестите много време и да помогнете за автоматизирането на много задачи, особено ако ги използвате за писане на скриптове или използвате регулярния израз при извършване на търсене в текста.
След това вижте често задаваните въпроси и отговори за интервюта за Linux.