
В областта на съвременния изкуствен интелект (ИИ) обучението с подсилване (RL) е една от най-готините изследователски теми. Разработчиците на AI и машинно обучение (ML) също се фокусират върху RL практиките, за да импровизират интелигентни приложения или инструменти, които разработват.
Машинното обучение е принципът зад всички AI продукти. Човешките разработчици използват различни ML методологии, за да обучават своите интелигентни приложения, игри и т.н. ML е силно диверсифицирана област и различни екипи за разработка идват с нови методи за обучение на машина.
Един такъв доходоносен метод на машинно обучение е задълбочено обучение с подсилване. Тук наказвате нежеланото поведение на машината и възнаграждавате желаните действия от интелигентната машина. Експертите смятат, че този метод на машинно обучение е длъжен да накара AI да се учи от собствения си опит.
Продължете да четете това най-добро ръководство относно методите за обучение с подсилване за интелигентни приложения и машини, ако обмисляте кариера в областта на изкуствения интелект и машинното обучение.
Съдържание
Какво представлява обучението с подсилване в машинното обучение?
RL е преподаването на модели за машинно обучение на компютърни програми. След това приложението може да вземе поредица от решения въз основа на моделите на обучение. Софтуерът се научава да постига цел в потенциално сложна и несигурна среда. В този вид модел на машинно обучение AI е изправен пред сценарий, подобен на игра.
Приложението AI използва проба и грешка, за да измисли креативно решение на разглеждания проблем. След като приложението AI научи правилните ML модели, то инструктира управляваната от него машина да изпълни някои задачи, които програмистът иска.
Въз основа на правилното решение и изпълнение на задачата, AI получава награда. Въпреки това, ако AI направи грешен избор, той е изправен пред наказания, като загуба на наградни точки. Крайната цел на AI приложението е да натрупа максимален брой наградни точки, за да спечели играта.
Програмистът на приложението AI определя правилата на играта или политиката за награди. Програмистът предоставя и проблема, който AI трябва да разреши. За разлика от други ML модели, AI програмата не получава никакви съвети от софтуерния програмист.
AI трябва да разбере как да разреши предизвикателствата на играта, за да спечели максимални награди. Приложението може да използва проба и грешка, произволни опити, суперкомпютърни умения и сложни тактики на мисловния процес, за да достигне до решение.
Трябва да оборудвате AI програмата с мощна изчислителна инфраструктура и да свържете нейната мисловна система с различни паралелни и исторически геймплеи. След това AI може да демонстрира критична креативност на високо ниво, която хората не могат да си представят.
Популярни примери за обучение с подсилване
#1. Побеждаване на най-добрия играч на Human Go
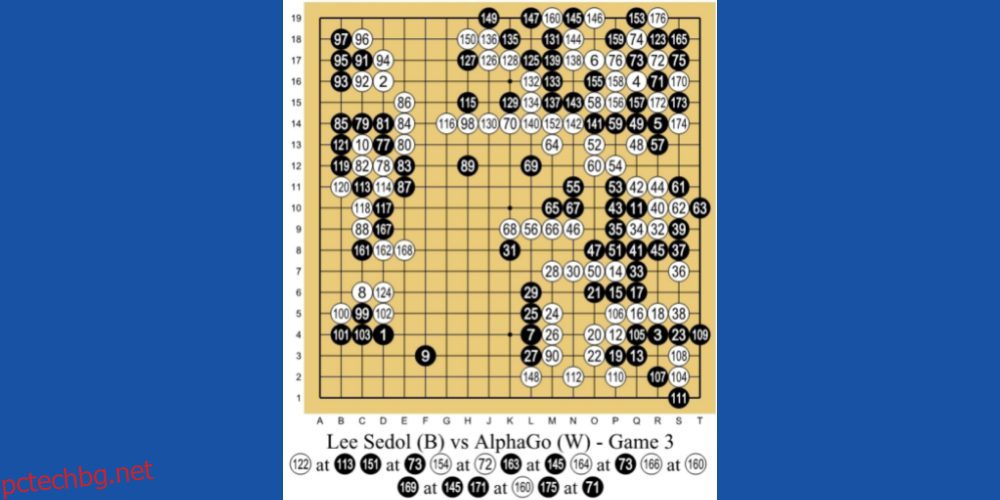
AlphaGo AI от DeepMind Technologies, дъщерно дружество на Google, е един от водещите примери за машинно обучение, базирано на RL. AI играе китайска настолна игра, наречена Go. Това е игра на 3000 години, която се фокусира върху тактики и стратегии.
Програмистите използваха RL метода на обучение за AlphaGo. Играл е хиляди сесии на игри Go с хора и себе си. След това, през 2016 г., победи най-добрия играч на Go в света Лий Се-дол в мач един на един.
#2. Роботика в реалния свят
Хората използват роботика от дълго време в производствени линии, където задачите са предварително планирани и се повтарят. Но ако трябва да направите робот с общо предназначение за реалния свят, където действията не са предварително планирани, тогава това е голямо предизвикателство.
Но изкуственият интелект с активирано обучение за подсилване може да открие плавен, навигационен и кратък маршрут между две местоположения.
#3. Самоуправляващи се превозни средства
Изследователите на автономни превозни средства широко използват метода RL, за да обучат своите AI за:
- Динамичен път
- Оптимизация на траекторията
- Планиране на движение като паркиране и смяна на лентата
- Оптимизиране на контролери, (електронен блок за управление) ECU, (микроконтролери) MCU и др.
- Обучение по магистрали по сценарий
#4. Автоматизирани системи за охлаждане

RL-базирани AI могат да помогнат за минимизиране на потреблението на енергия от охладителните системи в гигантски офис сгради, бизнес центрове, търговски центрове и, най-важното, центрове за данни. AI събира данни от хиляди топлинни сензори.
Той също така събира данни за човешки и машинни дейности. От тези данни AI може да предвиди бъдещия потенциал за генериране на топлина и по подходящ начин да включва и изключва системите за охлаждане, за да пести енергия.
Как да настроите модел на обучение за укрепване
Можете да настроите RL модел въз основа на следните методи:
#1. Базиран на политика
Този подход позволява на AI програмиста да намери идеалната политика за максимални награди. Тук програмистът не използва функцията стойност. След като зададете метода, базиран на политика, агентът за обучение за укрепване се опитва да приложи политиката, така че действията, които изпълнява във всяка стъпка, да позволят на AI да увеличи максимално наградните точки.
Основно има два вида политики:
#1. Детерминиран: Политиката може да доведе до едни и същи действия във всяко дадено състояние.
#2. Стохастичен: Произведените действия се определят от вероятността за възникване.
#2. Базиран на стойност
Подходът, базиран на стойността, напротив, помага на програмиста да намери оптималната функция на стойността, която е максималната стойност при дадена политика във всяко дадено състояние. Веднъж приложен, RL агентът очаква дългосрочна възвръщаемост във всяко едно или множество състояния съгласно споменатата политика.
#3. Базиран на модел
При базирания на модел RL подход, програмистът на AI създава виртуален модел за околната среда. След това RL агентът се движи из средата и се учи от нея.
Видове учене с подсилване
#1. Обучение с положително подсилване (PRL)
Положителното обучение означава добавяне на някои елементи за увеличаване на вероятността очакваното поведение да се случи отново. Този метод на обучение влияе положително върху поведението на RL агента. PRL също подобрява силата на определени поведения на вашия AI.
PRL типът подсилване на обучението трябва да подготви ИИ да се адаптира към промените за дълго време. Но инжектирането на твърде много положително обучение може да доведе до претоварване от състояния, което може да намали ефективността на ИИ.

#2. Обучение с отрицателно подсилване (NRL)
Когато RL алгоритъмът помага на AI да избегне или спре негативно поведение, той се учи от него и подобрява бъдещите си действия. Известно е като негативно обучение. Той предоставя на AI само ограничена интелигентност, само за да отговори на определени поведенчески изисквания.
Реални случаи на използване на обучение с подсилване
#1. Разработчиците на решения за електронна търговия са изградили персонализирани инструменти за предлагане на продукти или услуги. Можете да свържете API на инструмента към вашия сайт за онлайн пазаруване. След това AI ще се учи от отделни потребители и ще предлага персонализирани стоки и услуги.
#2. Видеоигрите с отворен свят идват с неограничени възможности. Зад програмата на играта обаче има AI програма, която се учи от въведените от играчите данни и модифицира кода на видеоигрите, за да се адаптира към неизвестна ситуация.
#3. Базираните на AI платформи за търговия с акции и инвестиции използват модела RL, за да се учат от движението на акциите и глобалните индекси. Съответно те формулират вероятностен модел, за да предложат акции за инвестиране или търговия.
#4. Онлайн видео библиотеки като YouTube, Metacafe, Dailymotion и т.н. използват AI ботове, обучени по модела RL, за да предлагат персонализирани видеоклипове на своите потребители.
Обучение с подсилване Vs. Контролирано обучение
Обучението с подсилване има за цел да обучи агента на ИИ да взема решения последователно. Накратко, можете да имате предвид, че изходът на AI зависи от състоянието на текущия вход. По подобен начин следващият вход към RL алгоритъма ще зависи от изхода на миналите входове.

Базирана на AI роботизирана машина, която играе игра на шах срещу човешки шахматист, е пример за модела на RL машинно обучение.
Напротив, при контролирано обучение програмистът обучава AI агента да взема решения въз основа на входните данни, дадени в началото или всеки друг първоначален вход. AI за автономно шофиране на автомобили, разпознаващ обекти от околната среда, е отличен пример за контролирано обучение.
Обучение с подсилване Vs. Учене без надзор
Досега разбрахте, че методът RL подтиква AI агента да се учи от политиките на модела за машинно обучение. Основно AI ще прави само онези стъпки, за които получава максимален брой наградни точки. RL помага на AI да се импровизира чрез проба и грешка.
От друга страна, при неконтролирано обучение, програмистът на AI въвежда софтуера на AI с немаркирани данни. Освен това инструкторът по ML не казва на AI нищо за структурата на данните или какво да търси в данните. Алгоритъмът научава различни решения, като каталогизира собствените си наблюдения върху дадените неизвестни набори от данни.
Курсове за засилване на обучението
Сега, след като научихте основите, ето няколко онлайн курса за усъвършенствано обучение за укрепване. Освен това получавате сертификат, който можете да демонстрирате в LinkedIn или други социални платформи:
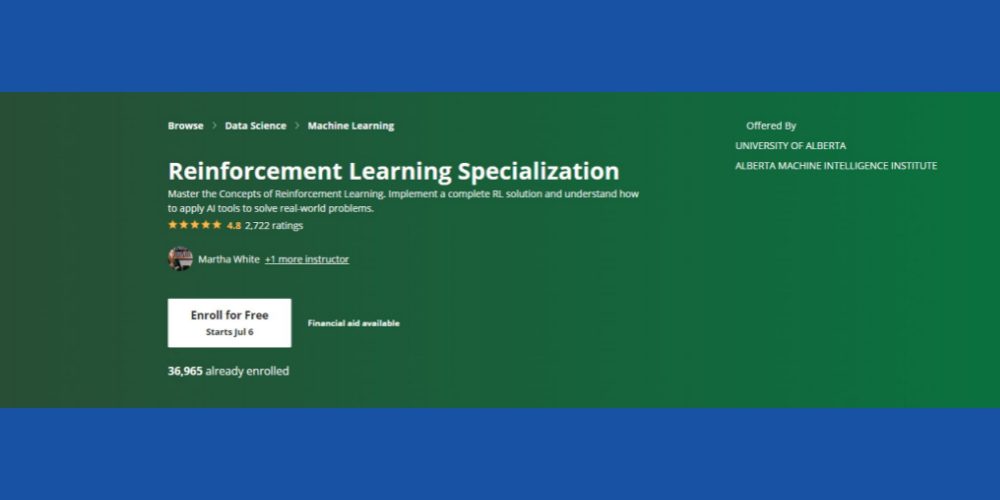
Специализация за засилване на обучението: Coursera
Искате ли да овладеете основните концепции на обучението с подсилване с ML контекст? Можете да опитате това Курс на Coursera RL който е достъпен онлайн и се предлага с опция за самостоятелно обучение и сертифициране. Курсът ще бъде подходящ за вас, ако имате следните основни умения:
- Познания за програмиране в Python
- Основни статистически понятия
- Можете да конвертирате псевдокодове и алгоритми в Python кодове
- Опит в разработката на софтуер от две до три години
- Студентите от втора година по дисциплина компютърни науки също са допустими
Курсът има оценка от 4,8 звезди и над 36 хиляди студенти вече са се записали в курса в различни курсове от време. Освен това курсът идва с финансова помощ, при условие че кандидатът отговаря на определени критерии за допустимост на Coursera.
И накрая, Институтът за машинно разузнаване на Алберта към Университета на Алберта предлага този курс (без присъден кредит). Уважавани професори в областта на компютърните науки ще функционират като инструктори на вашите курсове. След завършване на курса ще получите сертификат за Coursera.
Обучение за подсилване на AI в Python: Udemy
Ако сте във финансовия пазар или дигиталния маркетинг и искате да разработите интелигентни софтуерни пакети за споменатите области, трябва да проверите това Udemy курс по RL. Освен основните принципи на RL, съдържанието на обучението също ще ви научи как да разработвате RL решения за онлайн реклама и борсова търговия.

Някои забележителни теми, които курсът покрива са:
- Преглед на високо ниво на RL
- Динамично програмиране
- Моне Карло
- Методи за приближение
- Проект за борсова търговия с RL
Над 42 хиляди студенти са посетили курса досега. Ресурсът за онлайн обучение в момента има оценка от 4,6 звезди, което е доста впечатляващо. Освен това курсът има за цел да обслужва глобална студентска общност, тъй като учебното съдържание е достъпно на френски, английски, испански, немски, италиански и португалски.
Обучение с дълбоко укрепване в Python: Udemy
Ако имате любопитство и основни познания за задълбочено обучение и изкуствен интелект, можете да опитате това разширено RL курс по Python от Udemy. С оценка от 4,6 звезди от студенти, това е още един популярен курс за изучаване на RL в контекста на AI/ML.

Курсът има 12 раздела и обхваща следните важни теми:
- OpenAI Gym и основни RL техники
- TD Lambda
- A3C
- Основи на Theano
- Основи на Tensorflow
- Кодиране на Python за начинаещи
Целият курс ще изисква ангажирана инвестиция от 10 часа и 40 минути. Освен текстове, той включва и 79 експертни лекции.
Експерт по дълбоко укрепване на обучението: Udacity
Искате ли да научите усъвършенствано машинно обучение от световните лидери в AI/ML като Nvidia Deep Learning Institute и Unity? Udacity ви позволява да изпълните мечтата си. Вижте това Обучение с дълбоко укрепване курс, за да станете експерт по ML.

Трябва обаче да имате опит в усъвършенстван Python, междинна статистика, теория на вероятностите, TensorFlow, PyTorch и Keras.
Ще са необходими усърдно учене до 4 месеца, за да завършите курса. По време на курса ще научите жизненоважни RL алгоритми като Deep Deterministic Policy Gradients (DDPG), Deep Q-Networks (DQN) и др.
Заключителни думи
Обучението с подсилване е следващата стъпка в развитието на ИИ. Агенциите за развитие на ИИ и ИТ компаниите наливат инвестиции в този сектор, за да създадат надеждни и надеждни методологии за обучение на ИИ.
Въпреки че RL е напреднал много, има повече области на развитие. Например отделни RL агенти не споделят знания помежду си. Следователно, ако обучавате приложение да управлява кола, процесът на обучение ще стане бавен. Тъй като RL агенти, като откриване на обекти, препратки към пътища и т.н., няма да споделят данни.
Има възможности да инвестирате своята креативност и опит в машинното обучение в такива предизвикателства. Записването за онлайн курсове ще ви помогне да разширите знанията си за усъвършенствани RL методи и техните приложения в проекти от реалния свят.
Друго свързано обучение за вас са разликите между AI, Machine Learning и Deep Learning.