
Нека разберем как можете да поддържате производството си надеждно с помощта на инструментите на Chaos Engineering.
Инженерингът на хаоса е дисциплина, в която експериментирате върху вашата система или приложение, за да разкриете нейните слабости и пропуски в капацитета. Това са нещо, което не сте предполагали, че може да се случи, докато го създавате. Така че бихте причинили някои повреди на вашата система, за да покажете нейните слабости, за да направите корекциите и да направите вашата система и вашето приложение по-устойчиви.
Много популярни организации като Netflix, LinkedIn и Facebook извършват хаос инженеринг, за да разберат по-добре своята архитектура на микроуслуги и разпределени системи. Помага за намирането на нови проблеми по-рано от реалните потребителски оплаквания и предприема необходимите действия за коригирането им. Ето как тези организации могат да обслужват милиони потребители, да увеличат тяхната продуктивност и да спестят милиони долари 🤑.
Предимства на Chaos Engineering:
- Контролирайте загубите на приходи чрез намиране на критични проблеми
- Намаляване на грешките на системата или приложението
- По-добро потребителско изживяване с по-малко смущения и висока наличност на услугата
- Помага ви да научите повече за системата и да придобиете увереност.
Колко уверени сте в надеждността на вашето производство? Наистина ли е устойчив на бедствия?
Нека разберем с помощта на следните популярни инструменти за тестване на хаос.
Съдържание
Chaos Mesh
Chaos Mesh е решение за управление на инженеринг на хаоса, което инжектира грешки във всеки слой на система Kubernetes. Това включва подове, мрежата, системния I/O и ядрото. Chaos Mesh може автоматично да убива Kubernetes pods и да симулира закъснения. Може да наруши комуникацията между контейнерите и да симулира грешки при четене/запис. Той може да планира правила за експериментите и да дефинира техния обхват. Тези експерименти са определени с помощта на YAML файлове.
Chaos Mesh има табло за преглед на анализи на експерименти. Той работи върху Kubernetes и поддържа по-голямата част от облачната платформа. Той е с отворен код и наскоро беше приет като пясъчник проект на CNCF. Използвайки принципите на хаос инженеринг, можете да добавите Chaos Mesh към вашия работен процес DevOps, за да изградите устойчиви приложения.
Характеристики на Chaos Engineering:
- Лесно разгръщане на Kubernetes клъстери без промяна в логиката на разгръщане
- Не са необходими уникални зависимости за внедряване
- Дефинира хаос обекти с помощта на CustomResourceDefinitions (CRD)
- Осигурява табло за проследяване на всички експерименти
Хаос Инструментариум е прост инструмент с отворен код за Chaos Engineering Experiment Automation.
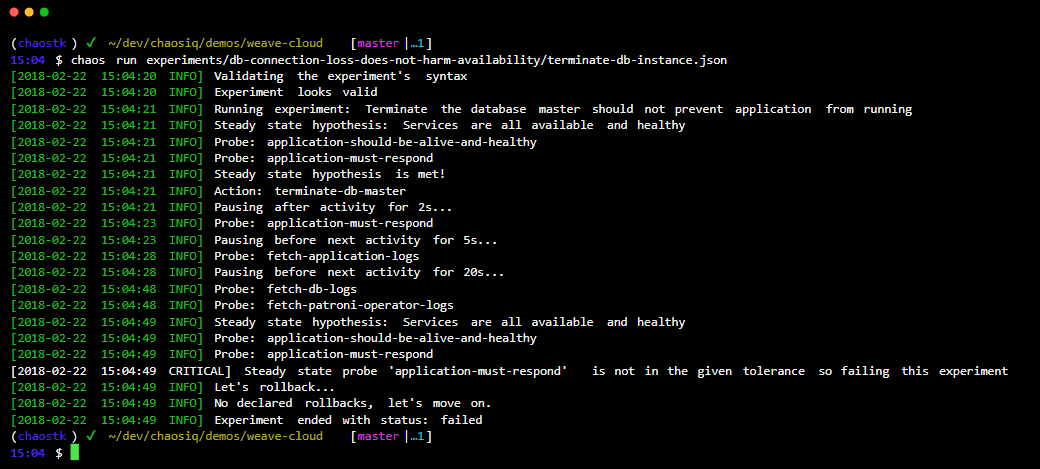
Вие интегрирате Chaos ToolKit с вашата система, като използвате набор от драйвери или плъгини, които поддържа AWS, Google Cloud, Slack, Prometheus и др.
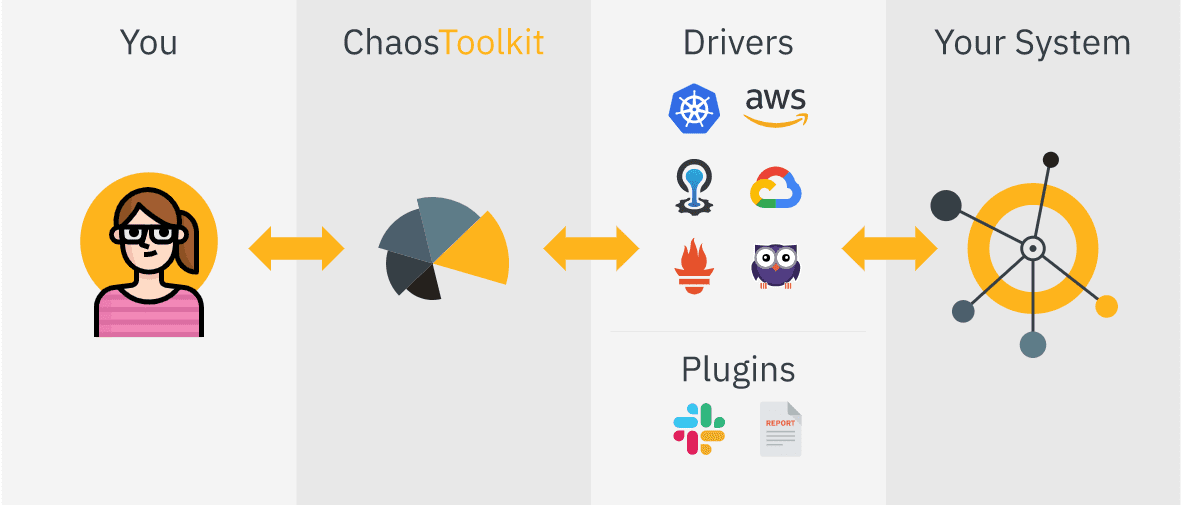
Характеристики на Chaos ToolKit:
- Осигурява декларативен Open API за създаване на експерименти с хаос, независимо от доставчик или технология
- Може лесно да се вгради в тръбопроводи CICD за автоматизация
- Осигурява търговска и корпоративна поддръжка също чрез ChaosIQ
ChaosKube
Както можете да познаете от името, това е за Kubernetes.
Чаоскубе е инструмент за хаос с отворен код, който периодично убива произволни подове в клъстера Kubernetes. Помага ви да разберете как ще реагира вашата система, когато модулът се повреди. По подразбиране той убива под във всяко пространство на имена на всеки 10 минути. Можете да филтрирате целевите модули в Chaoskube, като използвате пространства от имена, етикети, анотации и т.н. Може лесно да се инсталира с помощта на Chaoskube.

Chaos Monkey
Chaos Monkey е инструмент, използван за проверка на устойчивостта на облачните системи чрез целенасочено създаване на повреди за тези системи, за да разберат тяхната реакция. Netflix го създаде, за да тества устойчивостта и възстановимостта на неговата AWS инфраструктура. Наречена е Chaos Monkey, защото създава унищожение като дива и въоръжена маймуна, за да тества провалите.
Също така, Chaos Monkey даде началото на новата инженерна практика Chaos Engineering. Създаден е на принципа, че е по-добре да се проваляте многократно, за да избегнете внезапен значителен провал.
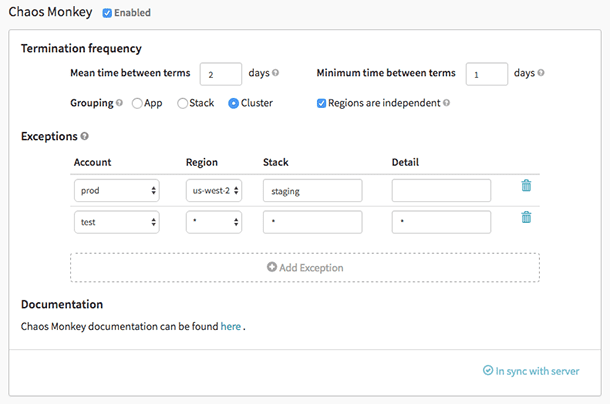
Характеристики на Chaos Monkey:
- Помага ви да се подготвите за случайни повреди на екземпляри.
- Насърчава излишъка при неочаквани повреди
- Използва Spinnaker, за да активира междуоблачна съвместимост
- Осигурява конфигурируем график за симулиране на повреди
- Интегриран с губернатор за добавяне на нови зависимости към chaos monkey
Сими
Сими е инструмент за хаос за инжектиране на грешки, който се интегрира с проекта за устойчивост на Polly за .NET. Тя ви позволява да създавате политики за инжектиране на хаос чрез Polly, където изпълнявате своите кодове. Той предлага различни политики, като например политика за изключения за инжектиране на изключения в системата, политика за поведение за инжектиране на ново поведение и т.н. Тези политики са предназначени да инжектират поведението на случаен принцип.
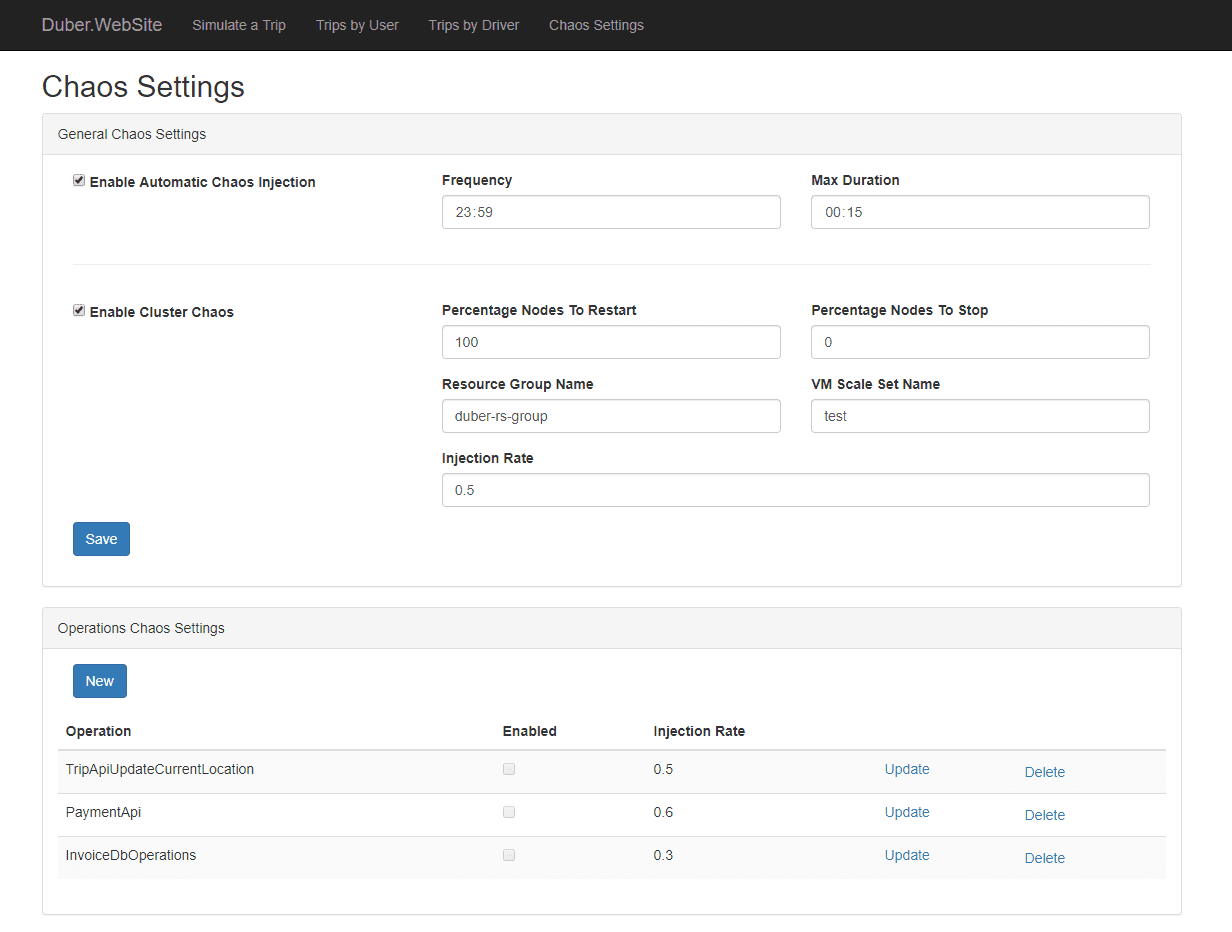
Характеристики на Simmy:
- Осигурява политики за маймуни или политики за хаос за внасяне на хаос
- Лесен за тестване на грешки в зависимостите
- Помага за бързото връщане към работния модел и контролира радиуса на взрива.
- Той е готов за производство.
- Може да дефинира повреди и въз основа на външни фактори (например повреди, дължащи се на глобална конфигурация)
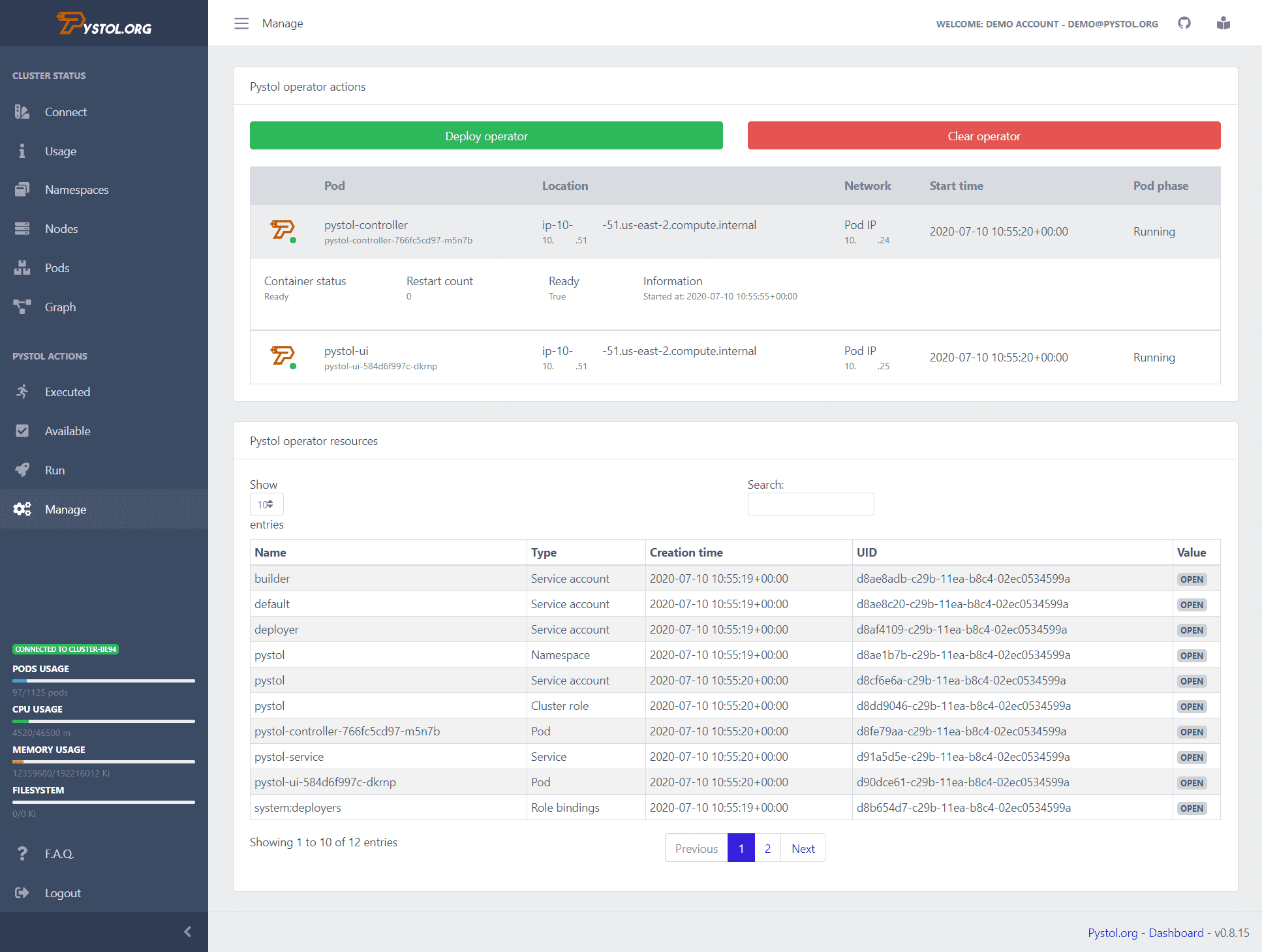
Пистол
Пистол е инструмент, който се използва за инжектиране на грешни инжекции в облачни среди. Той наблюдава събития в ETCD чрез операторите на Kubernetes. Когато се изпълни действие за инжектиране на грешка, операторите създават подовете и изпълняват някои Ansible колекции. Така че разработчиците не трябва да пишат свои собствени действия, които да изпълняват.
Pystol предоставя готови действия за тестване на системата. Все пак, ако програмист иска да създаде ново действие, това може да се направи с помощта на GoLang и Python.
Той осигурява табло за непрекъснато интегриране, за да даде обобщен изглед на всички работни операции. Можете да стартирате Pystol локално или да го разположите в контейнер, като използвате неговия докер образ. Pystol предоставя два интерфейса, единият е Web UI, а другият е чрез CLI. Очевидно уеб интерфейсът е по-добър вариант.
Мукси
Мукси е прокси за тестване на вашите модели за устойчивост и толерантност към грешки за откази на разпределена система в реалния свят. Може да подправя транспортно ниво (слой 4), ниво на TCP сесия (слой 5) и ниво на HTTP протокол (слой 7).
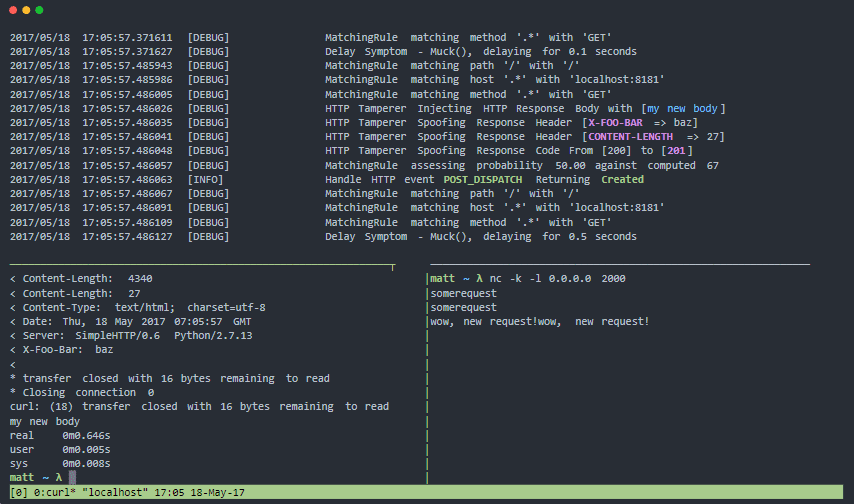
Характеристики на Muxy:
- Модулна архитектура и лесно разширяема
- Има официален докер контейнер
- Лесен за инсталиране, не са необходими зависимости.
- Идеален за непрекъснато тестване на устойчивостта
- Симулира проблеми с мрежовата свързаност за разпределени системи и мобилни устройства
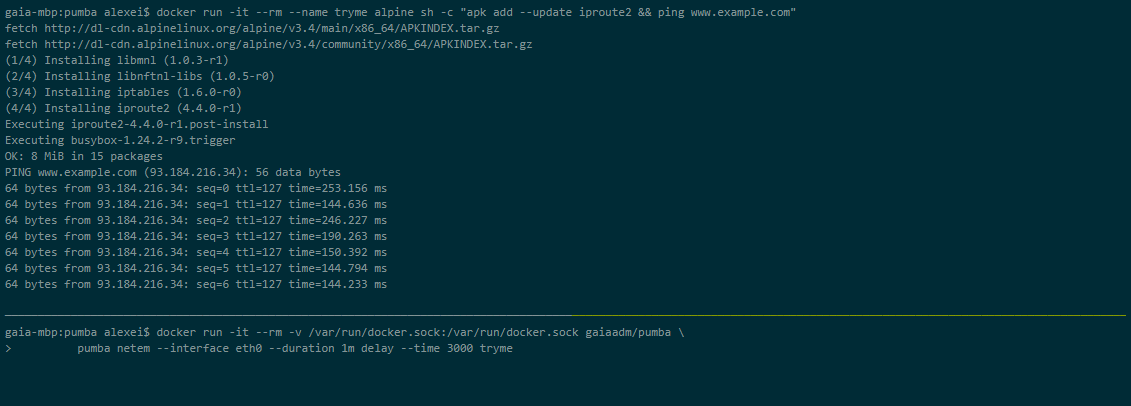
Пумба
Пумба е инструмент от командния ред, който извършва тестване на хаос за докер контейнери. С Pumba нарочно сривате докер контейнерите на приложението, за да видите как системата реагира. Можете също да извършите стрес тестове на ресурсите на контейнера като процесор, памет, файлова система, вход/изход и т.н.
Можете също да стартирате Pumba на Kubernetes клъстер. Трябва да използвате DaemonSets, за да разположите Pumba на Kubernetes възли. Можете да използвате множество Pumba контейнери, за да изпълнявате множество Pumba команди в един и същ DaemonSet.
ChaosBlade
ChaosBlade е инструмент с отворен код за въвеждане на експерименти в системите от Alibaba. Той тества всички неуспехи, с които Alibaba се сблъска през последните десет години, и прилага най-добрите практики, за да ги избегне. Той следва принципите на хаос инженеринг, за да провери устойчивостта на грешки на разпределените системи.
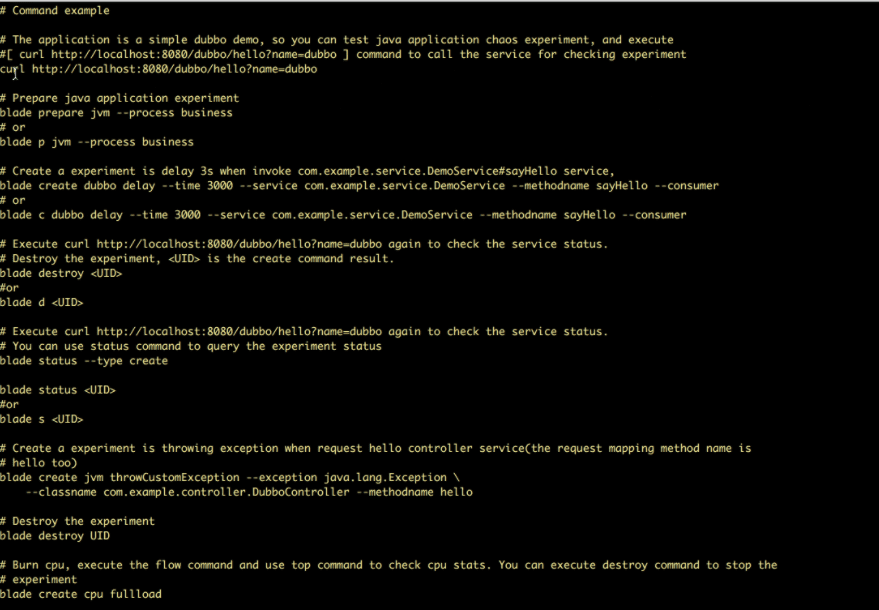
Характеристики на ChaosBlade:
- Предоставя експериментални сценарии за множество ресурси като процесор, мрежа, памет, диск и др.
- Предоставя експериментални сценарии за възли, мрежи и подове на платформата Kubernetes
- Осигурява лесни за използване CLI команди за изпълнение на експерименти
Лакмус
Лакмус следва принципите на инженеринг на хаоса в облака. Мисията на лакмусовия инструмент е да предостави цялостна рамка за намиране на слабости във вашите Kubernetes системи и работещите ви приложения в Kubernetes.
Той има хаос оператор и CRD (CustomResourceDefinitions) около това, което позволява възможност за plug-and-play. Всичко е свързано с поставянето на вашата логика на хаоса в докер изображение, поставянето му в лакмусова рамка и оркестрирането им с помощта на CRD.

Характеристики на лакмуса:
- Помага на инженерите и разработчиците за надеждност на сайта да открият слабости в системата Kubernetes
- Предоставя готови за използване общи експерименти
- Осигурява Chaos API за управление на работния процес на хаос
- Litmus SDK поддържа Go, Python и Ansible за създаване на ваши собствени експерименти.
Гремлин
Гремлин помага на инженерите да изградят по-устойчив софтуер. Той предоставя платформа за безопасно, сигурно и лесно провеждане на инженерни експерименти за хаос.

Можете внимателно да инжектирате грешка в хостове или контейнери с gremlin, независимо къде се намират, независимо дали това е публичният облак или вашият собствен център за данни.
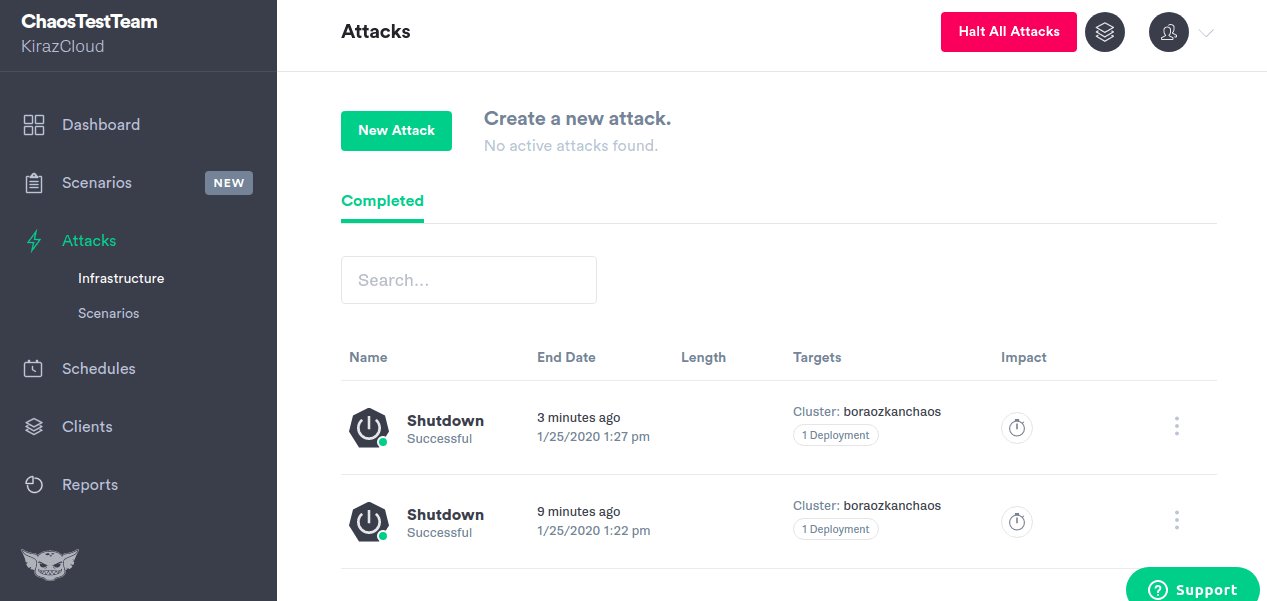
Характеристики на Gremlin:
- Инсталира лек агент на вашите хостове или контейнери за инжектиране на грешки
- Осигурява 10+ различни режима на атака на инфраструктурата
- Държавните гремлини ви позволяват да манипулирате системното време, да изключвате или рестартирате хостове и да убивате процесори.
- Мрежовите гремлини могат да инжектират латентност, за да въведат загуба на пакети или намаляване на трафика.
- Атаките на библиотеката Alfi на Gremlin могат да бъдат конфигурирани, стартирани и спрени чрез уеб приложението. API или CLI
- Позволява ви да насочите точно радиуса на взрива, който искате да атакувате
- Позволява ви да спрете всички атаки и да върнете системата обратно към стабилно състояние
Steadybit
Steadybit цели проактивно намаляване на времето за престой и осигурява видимост на системните проблеми. Можете да стартирате този инструмент локално във вашата инфраструктура или облак като услуга (SaaS).
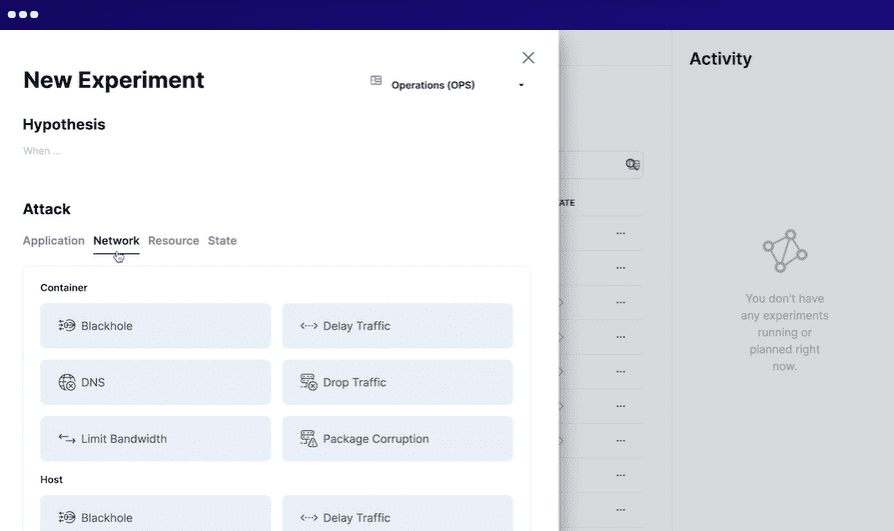
За да използвате Steadybit, вие дефинирате ситуацията, симулирате експериментите, изпълнявате симулираните експерименти в производството и автоматизирате всички експерименти. Той изпълнява интелигентни агенти във вашата система, за да открие потенциални проблеми и слабости. Той се интегрира с множество системи с лекота.
Заключение
Продължете напред и бъдете достатъчно смели, за да приложите принципите на инженеринг на хаоса и да тествате производството си с гореспоменатите инструменти. Тези инструменти ще ви помогнат да намерите множество неидентифицирани слабости във вашата система и ще ви помогнат да направите системата си по-устойчива.