

MapReduce предлага ефективен, по-бърз и рентабилен начин за създаване на приложения.
Този модел използва усъвършенствани концепции като паралелна обработка, локализиране на данни и т.н., за да предостави много предимства на програмисти и организации.
Но на пазара има толкова много програмни модели и рамки, че изборът става труден.
И когато става въпрос за Big Data, не можете просто да изберете нищо. Трябва да изберете такива технологии, които могат да обработват големи части от данни.
MapReduce е чудесно решение за това.
В тази статия ще обсъдя какво всъщност представлява MapReduce и как може да бъде от полза.
Да започваме!
Съдържание
Какво е MapReduce?
MapReduce е програмен модел или софтуерна рамка в рамката на Apache Hadoop. Използва се за създаване на приложения, способни да обработват масивни данни паралелно на хиляди възли (наречени клъстери или мрежи) с толерантност към грешки и надеждност.
Тази обработка на данни се извършва в база данни или файлова система, където се съхраняват данните. MapReduce може да работи с файлова система Hadoop (HDFS) за достъп и управление на големи обеми данни.
Тази рамка е въведена през 2004 г. от Google и е популяризирана от Apache Hadoop. Това е обработващ слой или двигател в Hadoop, работещ с програми MapReduce, разработени на различни езици, включително Java, C++, Python и Ruby.
Програмите MapReduce в облачните изчисления работят паралелно, като по този начин са подходящи за извършване на анализ на данни в големи мащаби.
MapReduce има за цел да раздели задача на по-малки, множество задачи, като използва функциите „map“ и „reduce“. Той ще картографира всяка задача и след това ще я редуцира до няколко еквивалентни задачи, което води до по-малка мощност на обработка и натоварване на клъстерната мрежа.
Пример: Да предположим, че приготвяте храна за къща, пълна с гости. Така че, ако се опитате да приготвите всички ястия и да извършите всички процеси сами, това ще стане забързано и отнема много време.
Но да предположим, че включвате някои от вашите приятели или колеги (не гости), които да ви помогнат при приготвянето на храната, като разпределите различни процеси на друг човек, който може да изпълнява задачите едновременно. В този случай ще приготвите ястието по-бързо и лесно, докато гостите ви са още вкъщи.
MapReduce работи по подобен начин с разпределени задачи и паралелна обработка, за да позволи по-бърз и лесен начин за изпълнение на дадена задача.
Apache Hadoop позволява на програмистите да използват MapReduce, за да изпълняват модели върху големи разпределени набори от данни и да използват усъвършенствани машинно обучение и статистически техники за намиране на модели, правене на прогнози, точкови корелации и др.
Характеристики на MapReduce
Някои от основните характеристики на MapReduce са:
- Потребителски интерфейс: Ще получите интуитивен потребителски интерфейс, който предоставя разумни подробности за всеки аспект на рамката. Ще ви помогне да конфигурирате, приложите и настроите задачите си безпроблемно.

- Полезен товар: Приложенията използват интерфейси Mapper и Reducer, за да активират функциите за карта и намаляване. Mapper картографира входните двойки ключ-стойност към междинни двойки ключ-стойност. Редукторът се използва за намаляване на междинните двойки ключ-стойност, споделящи ключ, до други по-малки стойности. Той изпълнява три функции – сортиране, разбъркване и намаляване.
- Partitioner: Той контролира разделянето на междинните изходни ключове за карта.
- Репортер: Това е функция за отчитане на напредъка, актуализиране на броячи и задаване на съобщения за състояние.
- Броячи: Представлява глобални броячи, дефинирани от приложението MapReduce.
- OutputCollector: Тази функция събира изходни данни от Mapper или Reducer вместо междинни изходи.
- RecordWriter: Той записва изходните данни или двойките ключ-стойност в изходния файл.
- DistributedCache: Той ефективно разпространява по-големи файлове само за четене, които са специфични за приложението.
- Компресиране на данни: Писачът на приложение може да компресира както изходни данни за задания, така и изходни междинни карти.
- Пропускане на лош запис: Можете да пропуснете няколко лоши записа, докато обработвате въведените от вас карти. Тази функция може да се контролира чрез класа – SkipBadRecords.
- Отстраняване на грешки: Ще получите опцията да изпълнявате дефинирани от потребителя скриптове и да активирате отстраняване на грешки. Ако задача в MapReduce е неуспешна, можете да стартирате своя скрипт за отстраняване на грешки и да откриете проблемите.
MapReduce архитектура
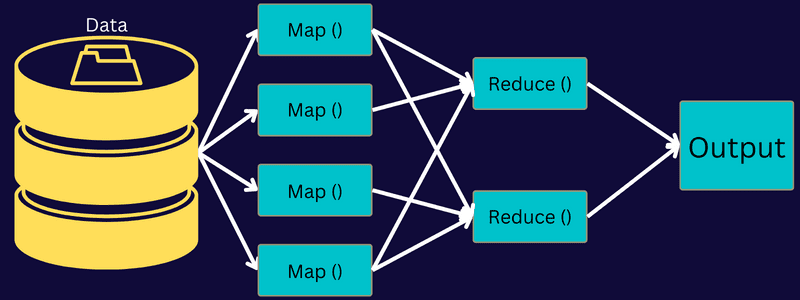
Нека разберем архитектурата на MapReduce, като навлезем по-дълбоко в нейните компоненти:
- Задача: Заданието в MapReduce е действителната задача, която клиентът на MapReduce иска да изпълни. Състои се от няколко по-малки задачи, които се комбинират, за да образуват крайната задача.
- Сървър за хронология на задачи: Това е процес на демон за съхраняване и запазване на всички исторически данни за приложение или задача, като регистрационни файлове, генерирани след или преди изпълнение на задача.
- Клиент: Клиент (програма или API) доставя задача на MapReduce за изпълнение или обработка. В MapReduce един или няколко клиента могат непрекъснато да изпращат задачи към MapReduce Manager за обработка.
- MapReduce Master: MapReduce Master разделя задачата на няколко по-малки части, като гарантира, че задачите се изпълняват едновременно.
- Части от заданието: Подзадачите или частите от заданието се получават чрез разделяне на основното задание. Те се обработват и накрая се комбинират, за да се създаде крайната задача.
- Входни данни: Това е наборът от данни, подаден на MapReduce за обработка на задачи.
- Изходни данни: Това е крайният резултат, получен след като задачата бъде обработена.
И така, това, което наистина се случва в тази архитектура, е, че клиентът изпраща задача на MapReduce Master, който я разделя на по-малки, равни части. Това позволява работата да се обработва по-бързо, тъй като по-малките задачи отнемат по-малко време, за да бъдат обработени, вместо по-големите задачи.
Уверете се обаче, че задачите не са разделени на твърде малки задачи, защото ако направите това, може да се наложи да се сблъскате с по-големи разходи за управление на разделяния и да загубите значително време за това.
След това частите на заданието са достъпни, за да продължите със задачите Map и Reduce. Освен това задачите Map и Reduce имат подходяща програма, базирана на случая на използване, върху който екипът работи. Програмистът разработва логически базиран код, за да изпълни изискванията.
След това входните данни се подават към задачата за карта, така че картата да може бързо да генерира изхода като двойка ключ-стойност. Вместо да се съхраняват тези данни в HDFS, се използва локален диск за съхраняване на данните, за да се елиминира възможността за репликация.
След като задачата приключи, можете да изхвърлите резултата. Следователно репликацията ще се превърне в излишък, когато съхранявате изхода на HDFS. Резултатът от всяка задача за карта ще бъде подаден към задачата за намаляване, а изходът от картата ще бъде предоставен на машината, изпълняваща задачата за намаляване.
След това изходът ще бъде обединен и предаден на функцията за намаляване, дефинирана от потребителя. И накрая, намаленият изход ще бъде съхранен на HDFS.
Освен това процесът може да има няколко Map и Reduce задачи за обработка на данни в зависимост от крайната цел. Алгоритмите Map и Reduce са оптимизирани, за да поддържат минимална времева или пространствена сложност.
Тъй като MapReduce включва предимно задачи за Map и Reduce, е уместно да разберете повече за тях. И така, нека обсъдим фазите на MapReduce, за да добием ясна представа за тези теми.
Фази на MapReduce
Карта
В тази фаза входните данни се преобразуват в изходните или двойките ключ-стойност. Тук ключът може да се отнася до идентификатора на адрес, докато стойността може да бъде действителната стойност на този адрес.
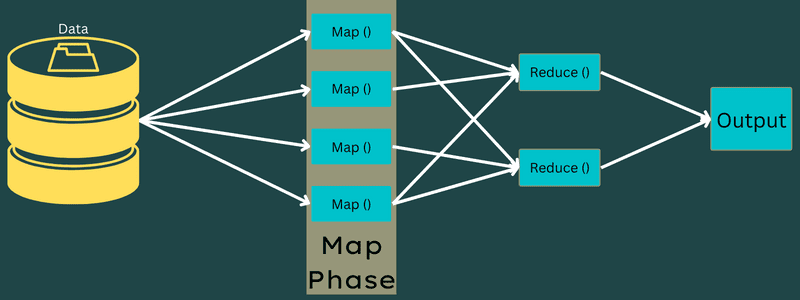
Има само една, но две задачи в тази фаза – разделяне и картографиране. Разделяне означава подчастите или частите от работата, разделени от основната работа. Те се наричат също входни разделяния. Така че входното разделяне може да се нарече входно парче, консумирано от карта.
След това се извършва задачата за картографиране. Счита се за първата фаза при изпълнение на програма за намаляване на картата. Тук данните, съдържащи се във всяко разделяне, ще бъдат предадени на функция за карта за обработка и генериране на изхода.
Функцията – Map() се изпълнява в хранилището на паметта върху входните двойки ключ-стойност, генерирайки междинна двойка ключ-стойност. Тази нова двойка ключ-стойност ще работи като вход, който ще бъде подаван към функцията Reduce() или Reducer.
Намалете
Междинните двойки ключ-стойност, получени във фазата на картографиране, работят като вход за функцията Reduce или Reducer. Подобно на фазата на картографиране, участват две задачи – разбъркване и намаляване.
И така, получените двойки ключ-стойност се сортират и разбъркват, за да бъдат подавани към Редуктора. След това редукторът групира или агрегира данните според своята двойка ключ-стойност въз основа на алгоритъма за редуктор, който разработчикът е написал.
Тук стойностите от фазата на разбъркване се комбинират, за да върнат изходна стойност. Тази фаза обобщава целия набор от данни.
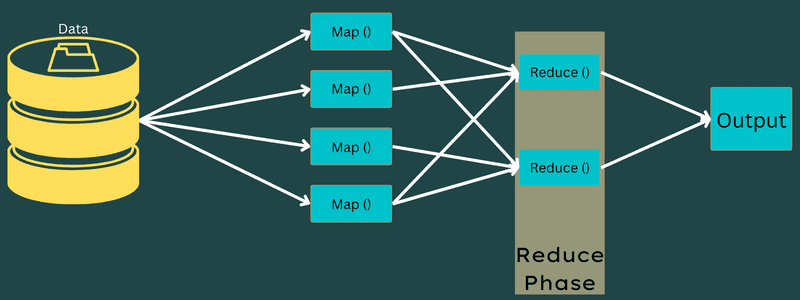
Сега пълният процес на изпълнение на задачите Map и Reduce се контролира от някои обекти. Това са:
- Job Tracker: С прости думи, Job Tracker действа като майстор, който е отговорен за пълното изпълнение на подадена задача. Инструментът за проследяване на задачи управлява всички задачи и ресурси в клъстер. Освен това инструментът за проследяване на задачи планира всяка карта, добавена в инструмента за проследяване на задачи, която работи на конкретен възел с данни.
- Множество тракери на задачи: С прости думи, множество тракери на задачи работят като роби, изпълнявайки задачата, следвайки инструкциите на Job Tracker. Инструмент за проследяване на задачи се разполага на всеки възел поотделно в клъстера, изпълняващ задачите Map и Reduce.
Работи, защото заданието ще бъде разделено на няколко задачи, които ще се изпълняват на различни възли с данни от клъстер. Job Tracker е отговорен за координирането на задачата, като планира задачите и ги изпълнява на множество възли с данни. След това инструментът за проследяване на задачи, разположен на всеки възел с данни, изпълнява части от заданието и се грижи за всяка задача.
Освен това инструментите за проследяване на задачи изпращат отчети за напредъка към инструмента за проследяване на задачи. Освен това Task Tracker периодично изпраща сигнал за „сърцебиене“ до Job Tracker и ги уведомява за състоянието на системата. В случай на повреда, инструментът за проследяване на задачи е в състояние да пренасрочи заданието на друг инструмент за проследяване на задачи.
Изходна фаза: Когато достигнете тази фаза, ще имате окончателните двойки ключ-стойност, генерирани от Редуктора. Можете да използвате форматиращ изход, за да преведете двойките ключ-стойност и да ги запишете във файл с помощта на записващо устройство.
Защо да използвате MapReduce?
Ето някои от предимствата на MapReduce, обясняващи причините, поради които трябва да го използвате във вашите приложения за големи данни:
Паралелна обработка
Можете да разделите задание на различни възли, където всеки възел едновременно обработва част от това задание в MapReduce. Така че разделянето на по-големите задачи на по-малки намалява сложността. Също така, тъй като различните задачи се изпълняват паралелно в различни машини вместо една машина, обработката на данните отнема значително по-малко време.
Локалност на данните
В MapReduce можете да преместите процесора към данни, а не обратното.
По традиционни начини данните се доставят до обработващия блок за обработка. Въпреки това, с бързото нарастване на данните, този процес започна да поставя много предизвикателства. Някои от тях са по-високи разходи, отнемат повече време, натоварват главния възел, чести повреди и намалена производителност на мрежата.
Но MapReduce помага за преодоляване на тези проблеми, като следва обратен подход – привеждане на обработващо устройство към данните. По този начин данните се разпределят между различни възли, където всеки възел може да обработва част от съхранените данни.
В резултат на това предлага рентабилност и намалява времето за обработка, тъй като всеки възел работи паралелно със съответната част от данните. Освен това, тъй като всеки възел обработва част от тези данни, нито един възел няма да бъде претоварен.
Сигурност

Моделът MapReduce предлага по-висока сигурност. Той помага да защитите вашето приложение от неоторизирани данни, като същевременно подобрява сигурността на клъстера.
Мащабируемост и гъвкавост
MapReduce е силно мащабируема рамка. Тя ви позволява да стартирате приложения от няколко машини, като използвате данни с хиляди терабайти. Той също така предлага гъвкавостта на обработката на данни, които могат да бъдат структурирани, полуструктурирани или неструктурирани и във всякакъв формат или размер.
Простота
Можете да пишете програми MapReduce на всеки език за програмиране като Java, R, Perl, Python и други. Поради това е лесно за всеки да учи и пише програми, като същевременно гарантира, че изискванията му за обработка на данни са изпълнени.
Случаи на използване на MapReduce
- Индексиране на пълен текст: MapReduce се използва за извършване на индексиране на пълен текст. Неговият Mapper може да картографира всяка дума или фраза в един документ. Редукторът се използва за запис на всички картирани елементи в индекс.
- Изчисляване на Pagerank: Google използва MapReduce за изчисляване на Pagerank.
- Анализ на регистрационни файлове: MapReduce може да анализира регистрационни файлове. Той може да разбие голям лог файл на различни части или да го раздели, докато картографът търси достъпни уеб страници.
Двойка ключ-стойност ще бъде подадена към редуктора, ако уеб страница бъде забелязана в регистрационния файл. Тук уеб страницата ще бъде ключът, а индексът „1“ е стойността. След предоставяне на двойка ключ-стойност на Reducer, различни уеб страници ще бъдат агрегирани. Крайният резултат е общият брой посещения за всяка уеб страница.

- Reverse Web-Link Graph: Рамката намира приложение и в Reverse Web-Link Graph. Тук Map() дава целевия URL адрес и източника и приема входни данни от източника или уеб страницата.
След това Reduce() обобщава списъка на всеки URL източник, свързан с целевия URL. Накрая извежда източниците и целта.
- Броене на думи: MapReduce се използва за броене колко пъти се появява дума в даден документ.
- Глобално затопляне: Организации, правителства и компании могат да използват MapReduce за решаване на проблеми с глобалното затопляне.
Например, може да искате да знаете за повишеното ниво на температурата на океана поради глобалното затопляне. За целта можете да съберете хиляди данни по целия свят. Данните могат да бъдат висока температура, ниска температура, географска ширина, дължина, дата, час и т.н. това ще отнеме няколко карти и ще намали задачите за изчисляване на изхода с помощта на MapReduce.
- Изпитвания на лекарства: Традиционно учените по данни и математиците работят заедно, за да формулират ново лекарство, което може да се бори с болест. С разпространението на алгоритми и MapReduce, ИТ отделите в организациите могат лесно да се справят с проблеми, които са били обработвани само от суперкомпютри, Ph.D. учени и т.н. Сега можете да проверите ефективността на лекарство за група пациенти.
- Други приложения: MapReduce може да обработва дори широкомащабни данни, които иначе няма да се поберат в релационна база данни. Той също така използва инструменти за наука за данни и им позволява да се изпълняват върху различни, разпределени набори от данни, което преди беше възможно само на един компютър.
В резултат на здравината и простотата на MapReduce, той намира приложения в армията, бизнеса, науката и т.н.
Заключение
MapReduce може да се окаже пробив в технологиите. Това е не само по-бърз и по-прост процес, но и рентабилен и отнемащ по-малко време. Като се имат предвид неговите предимства и нарастващата употреба, вероятно ще стане свидетел на по-голямо приемане в индустрии и организации.
Можете също така да разгледате някои от най-добрите ресурси, за да научите Big Data и Hadoop.